T5Gemma 2: Breakthroughs and Applications of the Next-Generation Encoder-Decoder Model
In the fast-paced world of artificial intelligence, encoder-decoder architectures have long stood out as a cornerstone of research and practical application, thanks to their unique strengths in tasks like text generation, translation, and question answering. In December 2025, Google unveiled T5Gemma 2—not just an upgrade to the previous T5Gemma, but a next-generation encoder-decoder model built on the Gemma 3 framework, marking the first integration of multimodal capabilities and long-context processing in this model family. This article will take you on a comprehensive journey through T5Gemma 2, covering its background, core innovations, performance metrics, and real-world applications, helping you grasp the distinctive value of this groundbreaking model.
I. Why T5Gemma 2? Understanding the Value of Encoder-Decoder Models
Before diving into T5Gemma 2, let’s first clarify what makes encoder-decoder models so valuable. Simply put, these models consist of two core components: the encoder, which “understands” input data (such as a piece of text or an image), and the decoder, which “generates” output content (such as a translation, summary, or answer). This division of labor makes them exceptionally well-suited for “input-output transformation” tasks—think machine translation (input Chinese → output English), summarization (input a long article → output a concise summary), or visual question answering (input an image + a question → output a relevant response).
Back in 2024, Google’s original T5Gemma already proved a key insight: by adapting powerful decoder-only models (like the Gemma series) into an encoder-decoder architecture, it was possible to retain the original model’s performance advantages while reducing the computational cost of training from scratch and boosting inference efficiency. T5Gemma 2 takes this foundation even further—it inherits the advanced features of Gemma 3 and elevates the encoder-decoder paradigm to new heights through architectural innovations.
II. Core Breakthroughs of T5Gemma 2: Architectural Innovations and Capability Upgrades
T5Gemma 2 is far more than a mere retraining of its predecessor; it represents a comprehensive upgrade from architecture to functionality. We can break down its innovations into two key dimensions: “efficiency optimization” and “capability expansion.”
1. Architectural Innovations: Making Models Lighter and More Efficient
To deliver stronger performance within smaller parameter footprints, T5Gemma 2 introduces two critical architectural improvements, striking a better balance between “parameter count” and “computational efficiency.”
(1) Tied Embeddings: Sharing a “Vocabulary Foundation” to Reduce Redundant Parameters
In traditional encoder-decoder models, the encoder and decoder typically rely on separate “word embedding tables”—think of these as “vocabulary dictionaries” that convert text into numerical vectors the model can process. This is analogous to two departments using distinct glossaries; communication requires extra translation steps, wasting resources and hampering efficiency.
T5Gemma 2 changes this by having the encoder and decoder share a single word embedding table. The immediate benefit is a dramatic reduction in total model parameters. For example, the 270M-270M variant of T5Gemma 2 (270M parameters for both encoder and decoder) has a total parameter count of approximately 370M (excluding the vision encoder)—a nearly 40% reduction compared to designs with separate embeddings. For models deployed on resource-constrained devices like smartphones or edge computing hardware, this optimization translates to lower memory usage and faster runtime.
(2) Merged Attention: Simplifying the Decoder to Boost Parallel Efficiency
A core function of the decoder is its “attention mechanism”—it needs to simultaneously focus on two sources of information: content it has already generated (self-attention, similar to maintaining coherence when writing an article) and input information from the encoder (cross-attention, similar to staying true to the original text when translating).
In traditional designs, these two attention types operate as separate layers—like two independent “checks” performed sequentially. T5Gemma 2 merges them into a single, unified attention layer, essentially “addressing both goals in one pass.” This design not only reduces the model’s overall parameter count and structural complexity but also enables more efficient parallel computing (processing multiple steps simultaneously), thereby accelerating inference speed. For applications requiring real-time responses—such as live translation or intelligent customer service—this optimization is highly practical.
2. Capability Upgrades: From Text-Only to Multimodal, From Small to Extra-Long Contexts
Beyond architectural efficiency gains, T5Gemma 2 inherits Gemma 3’s core capabilities, achieving three transformative leaps in functionality.
(1) Multimodality: Understanding Not Just Text, But Images Too
T5Gemma 2 is Google’s first multimodal encoder-decoder model. By integrating a highly efficient vision encoder, it can process both images and text inputs seamlessly. What does this mean in practice?
Consider an example: If you input an image of “a cat sitting on a keyboard” and ask, “What is the animal doing in this picture?” T5Gemma 2 can combine the image content with the question to directly output, “The cat is sitting on a keyboard.” This capability enables it to excel at tasks like visual question answering (VQA), image captioning (generating descriptive text for images), and multimodal reasoning (e.g., answering questions based on charts or graphs).
Crucially, this multimodal functionality is achieved within relatively small parameter sizes. For instance, the 270M and 1B variants of T5Gemma 2—originally text-only models—have been optimized to become efficient multimodal systems. This opens up powerful multimodal tools for resource-constrained scenarios where large models are impractical.
(2) Extra-Long Context: Processing Up to 128K Tokens in a Single Pass
The “context window” refers to the maximum length of input content a model can process at once (typically measured in tokens; one token is roughly equivalent to one English word or 1-2 Chinese characters). Traditional models often have context windows ranging from 4K to 32K tokens, forcing them to split long documents (like a book or a lengthy legal contract) into chunks— a process that risks losing overall logical coherence.
T5Gemma 2 leverages Gemma 3’s “alternating local-global attention” mechanism: for long texts, the model first focuses on local details (e.g., the content of a single paragraph) before integrating global logic (e.g., relationships between paragraphs). This expands its context window to an impressive 128K tokens—equivalent to processing approximately 100,000 Chinese characters (or 200,000 English words) in one go.
This capability makes T5Gemma 2 ideal for tasks like long-document summarization, legal contract analysis, and academic paper comprehension. For example, it can directly process an entire doctoral thesis and generate a structured summary without the need for chunking.
(3) Massive Multilingual Support: Covering Over 140 Languages
The diversity of training data directly impacts a model’s multilingual capabilities. T5Gemma 2 was trained on a larger, more diverse multilingual dataset, enabling it to support over 140 languages out of the box. This includes not just major languages like English, Chinese, and Spanish, but also numerous low-resource languages.
In practical terms, this means T5Gemma 2 can accurately understand and generate responses for emails written in Swahili, questions posed in Urdu, or documents translated from Vietnamese. For businesses operating across borders—such as cross-border e-commerce platforms or international aid organizations—this capability significantly lowers the barrier to multilingual communication.
III. T5Gemma 2’s Performance: Big Capabilities in Small Packages
Ultimately, a model’s innovations are only as valuable as its performance. According to Google’s published test results, T5Gemma 2 outperforms its predecessor and comparable decoder-only models across multiple key tasks—particularly shining in small-parameter configurations, where it delivers “big results with limited resources.”
1. Pre-Training Performance: Leading Across Multiple Dimensions
The chart below compares the pre-training performance of Gemma 3, the original T5Gemma, and T5Gemma 2 across five core capability areas (higher scores indicate better performance):
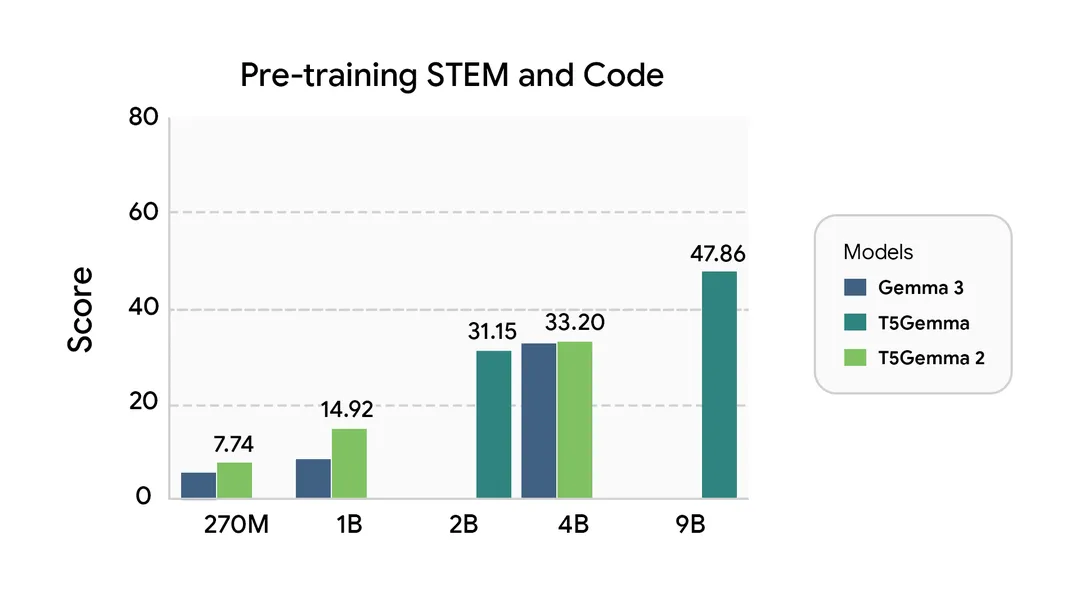
Pre-training performance of Gemma 3, T5Gemma, and T5Gemma 2 across five unique capabilities.
As the chart illustrates, T5Gemma 2’s strengths are particularly evident in three areas:
-
Multimodal Performance: In tasks requiring integration of text and images, T5Gemma 2 outperforms Gemma 3 (a text-only model) by a significant margin. For example, the 270M-parameter T5Gemma 2 scores over 15% higher than the same-parameter Gemma 3 on visual question answering benchmarks. -
Long-Context Capability: Thanks to its 128K token window and optimized attention mechanism, T5Gemma 2 delivers substantial quality gains over both Gemma 3 and the original T5Gemma in long-document processing. The use of a separate encoder gives it a distinct advantage in handling long-context tasks. -
General Capabilities: Across coding, logical reasoning, and multilingual tasks, T5Gemma 2 generally outperforms its Gemma 3 counterparts. For instance, the 1B-parameter T5Gemma 2 achieves an 8% higher accuracy rate in Python code generation compared to the same-parameter Gemma 3.
2. Post-Training Performance: Ideal for Practical Applications
Pre-trained models are like “blank slates”—they require fine-tuning (task-specific training) to be “production-ready.” Google conducted simple supervised fine-tuning (SFT) on T5Gemma 2 and found that it continues to outperform comparable decoder-only models:
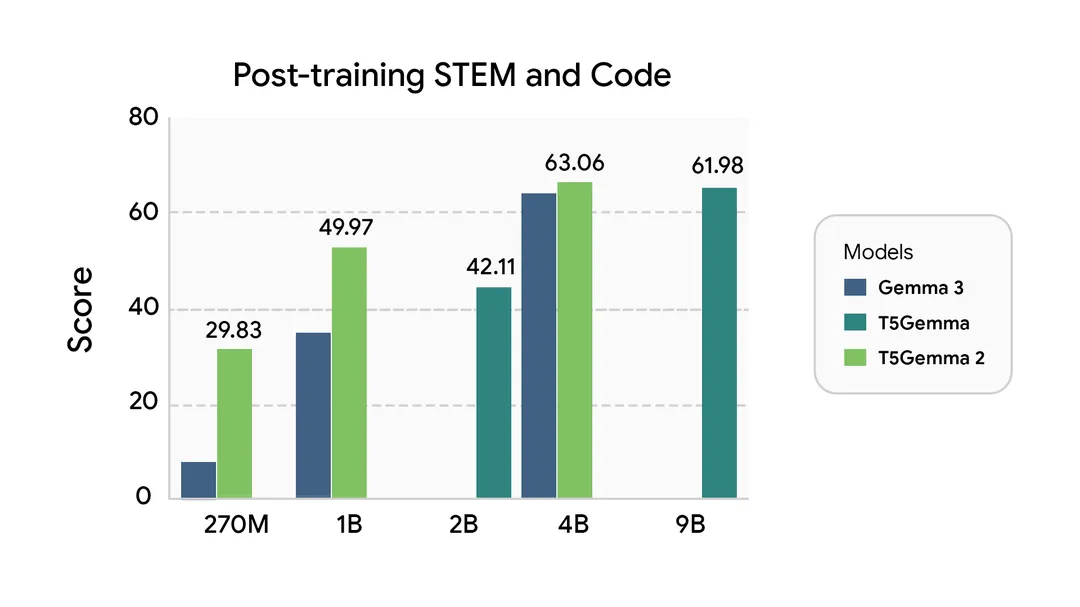
Post-training performance. Note: We are not releasing any post-trained/IT checkpoints. These results are for illustration only, where we performed minimal SFT without RL for T5Gemma 2. Also, pre-training and post-training benchmarks are different, so scores are not comparable across plots.
This means that developers only need to conduct minimal task-specific adaptation training to deploy T5Gemma 2 in scenarios like enterprise customer service chatbots or professional document translation. For teams with limited resources, this “fine-tuning efficiency” drastically reduces the barrier to adoption.
IV. T5Gemma 2 Model Variants and Use Cases
T5Gemma 2 is available in three pre-trained parameter configurations, covering a wide range of deployment scenarios—from edge devices to cloud-based applications:
| Model Configuration (Encoder-Decoder) | Total Parameters (Including Vision Encoder) | Target Use Cases |
|---|---|---|
| 270M-270M | Approximately 370M | Resource-constrained devices (e.g., smartphones, embedded systems), such as real-time translation apps or smartwatch question answering. |
| 1B-1B | Approximately 1.7B | Mid-sized servers and enterprise applications, such as internal document summarization systems or customer service robots. |
| 4B-4B | Approximately 7B | Large-scale cloud applications, such as multimodal content generation platforms or long-document analysis systems. |
All models are provided as pre-trained checkpoints, allowing developers to fine-tune them for specific tasks (e.g., translation, image-text问答) before deployment—offering maximum flexibility.
V. How to Get Started with T5Gemma 2?
If you’re a developer or researcher looking to explore T5Gemma 2, here are the key resources and steps to get started:
Step 1: Dive into the Technical Details
Read the arXiv paper T5Gemma 2: The Next Generation of Encoder-Decoder Models (link) to learn about the model’s architectural design, training methodology, and experimental results.
Step 2: Download Model Files
-
Access pre-trained checkpoints on Kaggle (link); -
Explore the model repository and example code on Hugging Face Hub (link).
Step 3: Try a Quick Demo
Run example code in a Colab notebook to experiment with T5Gemma 2 without local environment setup (link).
Step 4: Deploy on the Cloud
Leverage Google Vertex AI to directly call T5Gemma 2 for inference—ideal for large-scale commercial applications (link).
VI. Frequently Asked Questions (FAQs)
1. What’s the difference between T5Gemma 2 and the original T5Gemma?
The core differences lie in architecture and capabilities: the original T5Gemma was a text-only encoder-decoder model, while T5Gemma 2 introduces efficiency optimizations (tied embeddings and merged attention) and adds multimodal support, a 128K token long context window, and coverage of over 140 languages.
2. Which image formats does T5Gemma 2’s multimodal capability support?
Currently, it supports mainstream image formats (e.g., JPG, PNG, WebP). Input images are first converted into feature vectors via the vision encoder, then processed in combination with text information.
3. Will the 128K context window slow down inference in practical use?
Compared to models with smaller windows, processing 128K tokens does increase inference time. However, T5Gemma 2’s merged attention and parallel computing optimizations make it approximately 30% faster than comparable traditional models—fast enough to meet most practical application needs.
4. Can T5Gemma 2 be used for commercial deployment?
Yes, T5Gemma 2’s pre-trained models allow developers to fine-tune and deploy them for commercial use. For specific licensing terms, refer to the documentation on the download platforms.
5. Can I use T5Gemma 2 without a machine learning background?
If you only need to call the model (not train it), you can use APIs on platforms like Vertex AI directly, no deep understanding of model details required. For fine-tuning, we recommend following the code tutorials in the Colab examples—basic programming knowledge is sufficient to get started.
6. How does T5Gemma 2 compare to other multimodal models like Gemini?
While Gemini is a general-purpose multimodal model, T5Gemma 2 is specialized for encoder-decoder tasks (e.g., translation, summarization, question answering). Its key advantage is efficiency—delivering strong multimodal and long-context capabilities in smaller parameter sizes, making it ideal for deployment on resource-constrained devices.
7. Is T5Gemma 2 compatible with popular deep learning frameworks?
Yes, T5Gemma 2 checkpoints are available in formats compatible with Hugging Face Transformers, TensorFlow, and PyTorch—ensuring seamless integration with most existing deep learning workflows.
8. Can I fine-tune T5Gemma 2 for my specific industry (e.g., healthcare, finance)?
Absolutely. The pre-trained models are designed to be fine-tuned on domain-specific data. For example, you can adapt T5Gemma 2 to analyze medical documents or generate financial reports by fine-tuning it on relevant datasets.
Conclusion
The launch of T5Gemma 2 represents not just a significant upgrade to encoder-decoder models, but also a embodiment of the “efficient and practical” design philosophy—delivering powerful capabilities in small parameter footprints and expanding application boundaries through multimodality and long-context support. For developers, it offers a high-performance, cost-effective solution; for industries, it unlocks AI deployment in previously challenging scenarios (e.g., edge devices, multilingual services, long-document processing).
If you’re searching for an encoder-decoder model that can handle text and images, process long documents, and support multiple languages, T5Gemma 2 is well worth exploring—it may just be the versatile tool you need to bring your AI projects to life.
