

How to Stream LLM Responses in Real-Time Using Server-Sent Events (SSE)


In the realm of artificial intelligence (AI) development, real-time streaming of responses from Large Language Models (LLMs) has become pivotal for enhancing user experiences and optimizing application performance. Whether building chatbots, live assistants, or interactive content generation systems, efficiently delivering incremental model outputs to clients is a core challenge. Server-Sent Events (SSE), a lightweight HTTP-based protocol, emerges as an ideal solution for this scenario.
This article explores the mechanics of SSE, its practical applications in LLM streaming, and demonstrates how tools like Apidog streamline real-time data debugging. Whether you’re new to real-time communication protocols or seeking to refine existing AI applications, this guide offers actionable insights.
What Are Server-Sent Events (SSE)?
Core Principles of SSE
Server-Sent Events (SSE) enable servers to push real-time data to clients over a single HTTP connection. Unlike WebSocket, which facilitates bidirectional communication, SSE focuses on unidirectional streaming—perfect for scenarios where servers continuously send updates while clients only receive them. For instance, when a user queries a chatbot, the server can progressively generate responses and stream fragments via SSE, allowing users to see partial outputs without waiting for the complete answer.
SSE vs. WebSocket: Key Differences
-
Communication Model: SSE is unidirectional (server→client), while WebSocket is bidirectional (client↔server). -
Protocol Complexity: SSE operates over HTTP without additional handshakes; WebSocket requires a separate connection setup. -
Use Cases: SSE excels in server-push scenarios (e.g., news feeds, live logs); WebSocket suits interactive applications (e.g., gaming, collaborative editing).
For streaming LLM responses, SSE’s simplicity and low overhead make it the superior choice.
Why SSE Is Ideal for Streaming LLM Responses
Technical Advantages Explained
-
Real-Time Delivery
LLMs (e.g., GPT-4, DeepSeek R1) typically generate responses word-by-word or sentence-by-sentence. With SSE, the server pushes each fragment immediately upon generation, letting users view partial content without delay. For example:1. "Analyzing your query..." 2. "Retrieving relevant data..." 3. "Generating final response: ..."This incremental feedback significantly enhances user experience.
-
Resource Efficiency
SSE maintains a persistent connection, eliminating the need for client-side polling. The server sends data only when updates are available, reducing bandwidth and computational costs. -
Developer-Friendly Implementation
Clients simply listen to anEventSourceto receive data, avoiding complex state management. Below is a basic JavaScript example:const eventSource = new EventSource('/stream'); eventSource.onmessage = (event) => { console.log('Received data:', event.data); };
Hands-On: Debugging SSE Streams with Apidog
Tool Overview
👉Apidog is a robust API development tool that parses SSE streams in real time, offering features like auto-merging fragmented responses and visual debugging timelines. Here’s a step-by-step walkthrough:
Step 1: Create an SSE Debugging Endpoint
-
Create a new HTTP project in Apidog. -
Add an endpoint pointing to your LLM service’s SSE interface (e.g., https://api.deepseek.com/v1/chat/completions). -
Ensure the request headers include Accept: text/event-stream.
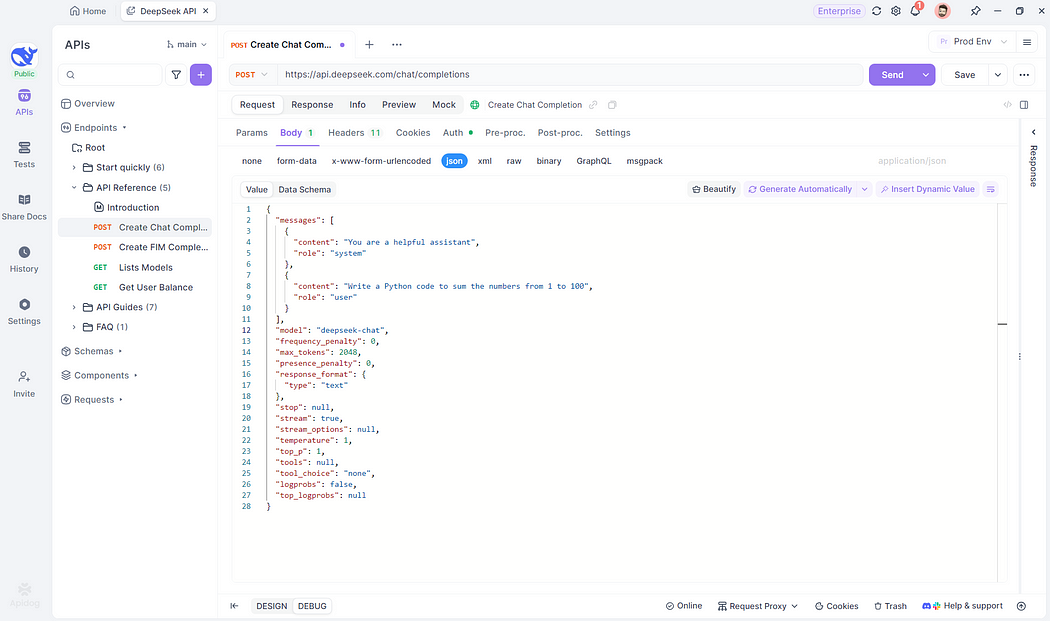
Step 2: Send Requests and Capture Streamed Responses
After clicking “Send,” if the server returns a Content-Type: text/event-stream header, Apidog automatically detects the SSE stream and parses incoming data. All server-pushed fragments display in real time.
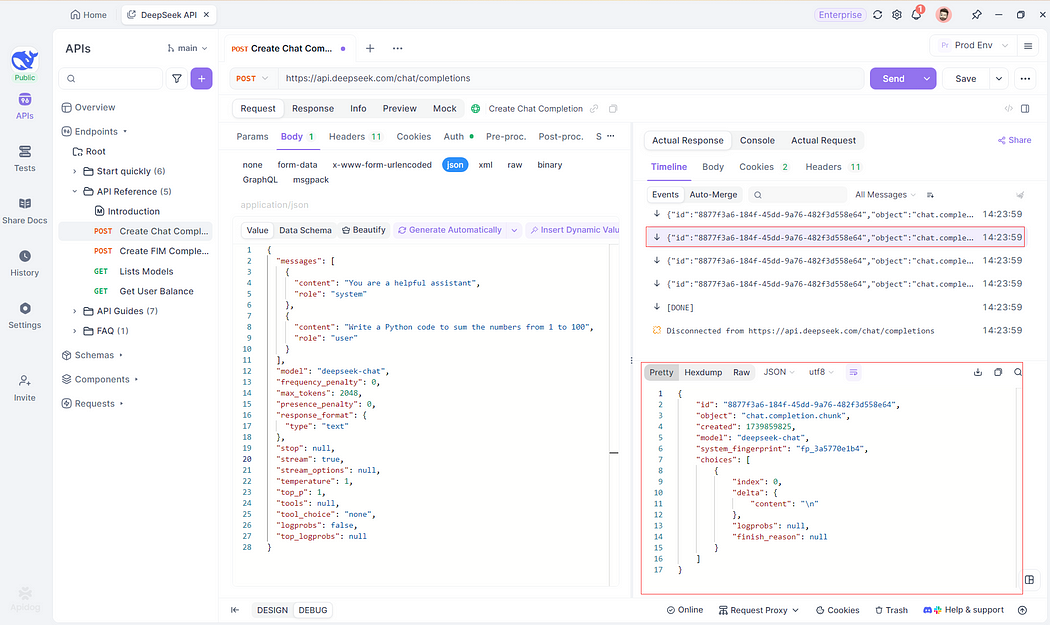
Step 3: Analyze Responses Using Timeline View
Apidog’s Timeline View arranges data fragments chronologically, allowing developers to observe the model’s response generation process. For example:
[Timestamp 10:00:00] Fragment received: "Processing query..."
[Timestamp 10:00:02] Fragment received: "Searching knowledge base..."
[Timestamp 10:00:05] Fragment received: "Generating answer: Hello! ..."
This visibility aids in identifying latency issues or logic errors.
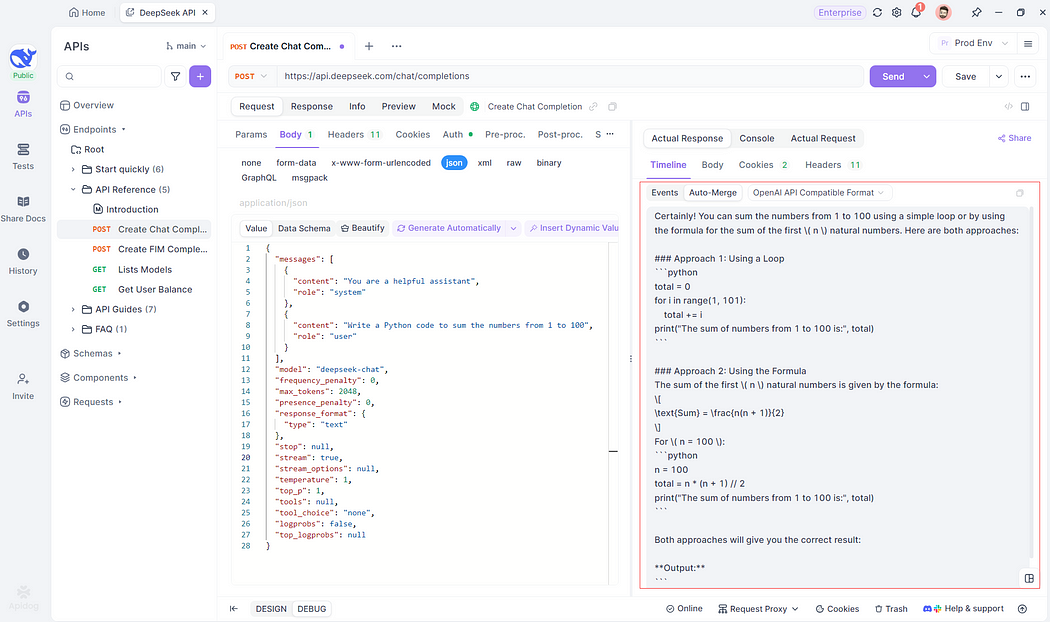
Step 4: Auto-Merge Fragmented Responses
LLM responses often consist of multiple fragments. Apidog’s Auto-Merge feature consolidates these into a coherent output. For example:
Original fragments:
1. "Hello!"
2. "The weather is sunny today."
3. "Perfect for a walk."
Merged result:
"Hello! The weather is sunny today. Perfect for a walk."
This feature is invaluable for handling complex outputs from models like OpenAI or Gemini.
Advanced Debugging: Custom Response Handling
Scenario 1: Non-Standard JSON SSE Responses
If your LLM returns non-standard JSON (e.g., custom field names), use JSONPath Extraction Rules to target specific fields. For instance, given:
{"result": {"text": "Generated content..."}}
Configure JSONPath as $.result.text to extract the text value.
Scenario 2: Plain Text or Unstructured Data
For non-JSON streams (e.g., plain text), write Post-Processor Scripts to parse data. The script below converts text to uppercase:
function parseResponse(data) {
return data.toUpperCase();
}
Best Practices for Reliable SSE Streaming
-
Handle Network Interruptions
Implement client-side reconnection mechanisms:eventSource.onerror = () => { setTimeout(() => { eventSource = new EventSource('/stream'); }, 5000); // Reconnect after 5 seconds }; -
Optimize Fragment Sizes
Keep SSE messages under 1KB to prevent delays from large payloads. -
Ensure Cross-Model Compatibility
Test your setup with multiple LLMs (e.g., OpenAI, DeepSeek, Gemini) to validate universal parsing logic. -
Monitor Performance Metrics
Use Apidog’s Timeline View to track fragment arrival times and identify bottlenecks.
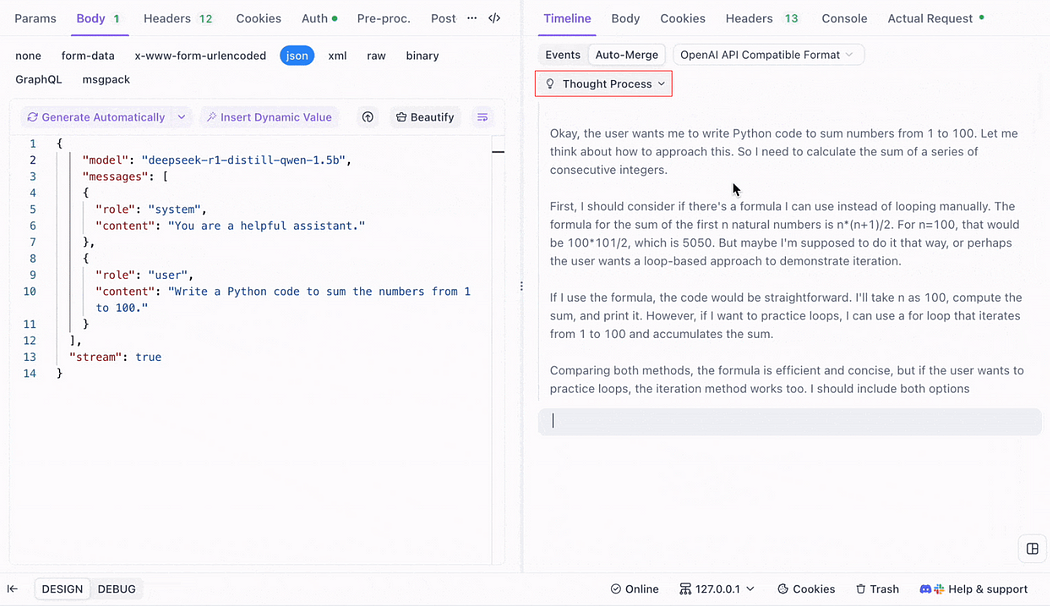
Visualizing the LLM’s “Thought Process”
Apidog not only displays final responses but also reveals intermediate steps via its Timeline View. For example, when a user asks, “How to make pizza?”, you might observe:
1. Parsing query: Identifies keywords "pizza," "make."
2. Knowledge retrieval: Searches recipe databases.
3. Step generation: Lists ingredients and baking temperatures.
4. Response refinement: Adds tips (e.g., oven preheating).
This transparency helps developers refine prompts or adjust model parameters.
Conclusion
Server-Sent Events (SSE) provide a cost-effective, efficient method for real-time LLM response streaming. By leveraging Apidog’s debugging tools—auto-merge, timeline analysis, and custom parsing—developers can troubleshoot faster, optimize model performance, and gain deeper insights into AI decision-making. Whether building real-time chat applications or interactive AI systems, SSE is a critical technology to master.
For production deployments, adhere to the best practices outlined here: prioritize network resilience, optimize data fragmentation, and ensure cross-model compatibility. These steps guarantee smooth, instantaneous interactions that meet modern user expectations.