Set Block Decoding: A New Method to Boost Large Language Model Inference Speed by 3-5x
1. The Problem: Why Do Language Models Need Faster Inference?
If you’ve ever used a large language model (LLM) for tasks like writing code or solving math problems, you might have experienced:
-
Lagging responses when generating long code blocks -
Slowdowns halfway through complex calculations -
Increasing wait times as text generation progresses
These issues stem from fundamental challenges in LLM inference. Traditional autoregressive models face three core limitations:
Key Pain Points:
-
Computational Intensity: Each new word (token) requires a full model computation -
Memory Pressure: Constant reloading of model parameters and cached data -
Linear Scaling Delay: Generating 1,000 tokens requires 1,000 full computations
Imagine a relay race where each runner must complete the entire track individually. Set Block Decoding (SBD) introduces smarter race strategies.
2. The Breakthrough: SBD’s Parallel Decoding Innovation
2.1 Traditional vs SBD Approaches
Standard Next-Token Prediction (NTP):
Generation: token1 → token2 → token3 → ... → token1000
Computations: 1,000 full model passes
SBD Method:
Generation: block1 (predicts 4 tokens) → block2 (predicts 4 tokens) → ...
Computations: ~200 passes (assuming 5 tokens per block)
2.2 Three Core Innovations
1. Hybrid Attention Mechanism
-
Causal Attention: Maintains left-to-right generation coherence -
Bidirectional Attention: Allows future tokens to “see” each other in blocks
2. Dynamic Masking System
# Training-time mask generation
if random() < probability_threshold:
hide_current_token()
else:
show_current_token()
This creates varied prediction scenarios during training.
3. Entropy-Guided Decoding
-
Calculates uncertainty (entropy) for each token -
Prioritizes tokens with low uncertainty -
Dynamically adjusts parallel prediction scope
3. Architecture Deep Dive: How SBD Works
3.1 Model Structure Changes
Visualization Guide:
-
White Area: Standard causal attention (processes history) -
Blue Area: Bidirectional attention (future tokens interact) -
Pink Area: KV cache of decoded blocks
3.2 Training Process
| Phase | Input Handling | Loss Function | Key Operation |
|---|---|---|---|
| Pretraining | Raw text + random masks | NTP loss + MATP loss | Mixed attention patterns |
| Fine-tuning | Instruction data + dynamic blocks | Same loss combination | Fixed block size |
# Training loss calculation example
loss = CrossEntropy(ground_truth, NTP_prediction)
+ CrossEntropy(masked_tokens, MATP_prediction)
3.3 Inference Process
-
Prefill Stage: Process initial prompt and cache KV -
Decoding Stage: -
Initialize k masked positions -
Repeat until completion: -
Model forward pass to predict block -
Select decodable tokens by entropy threshold -
Update KV cache
-
-
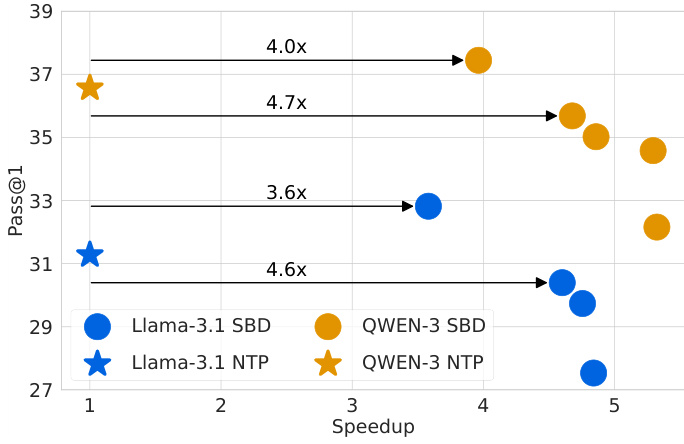
4. Real-World Results: 3-5x Speed Gains
4.1 Benchmark Performance
| Model | Training | Sampling | MATH500 | AIME25 | GSM8K |
|---|---|---|---|---|---|
| Llama-3.1 8B | NTP | NTP | 80.2 | 33.3 | 85.3 |
| Llama-3.1 8B | SBD | SBD (low γ) | 81.0 (3.55x) | 30.0 (3.35x) | 84.2 (2.20x) |
| Qwen-3 8B | NTP | NTP | 86.6 | 33.3 | 90.1 |
| Qwen-3 8B | SBD | SBD (high γ) | 85.4 (3.54x) | 26.6 (5.06x) | 88.7 (2.86x) |
Numbers in parentheses show speedup multiples. Negative values indicate minor accuracy tradeoffs.
4.2 Key Findings
-
Accuracy Preservation:
-
Math reasoning tasks maintain accuracy at low γ settings -
Code generation (HumanEval+) shows 5.36x speedup
-
-
Flexibility Advantage:
-
Adjust γ parameter to balance speed/accuracy -
No architectural changes required
-
5. The Science: Why SBD Works
5.1 Roofline Model Analysis
X-axis: Compute density (FLOPs/Byte)
Y-axis: Performance (FLOPs/sec)
Key Insight:
-
At block size=16, computational density matches NTP -
Larger batches show more significant acceleration
5.2 Memory Bandwidth Optimization
| Operation | Data Volume | Bandwidth Requirement |
|---|---|---|
| NTP | 1 token/iteration | O(L) |
| SBD | k tokens/iteration | O(L/k) |
For 1,000 tokens with k=16, memory access reduced 16x
6. Practical Implementation Guide
6.1 Best Use Cases
✅ Recommended For:
-
Long-form text generation (stories, code, reports) -
Complex mathematical problem solving -
Multi-turn dialogue systems -
Code completion/generation
❌ Use With Caution:
-
Very short texts (<10 tokens) -
Non-time-sensitive applications -
Scenarios requiring per-token precision
6.2 Deployment Example
# Pseudocode: Inference workflow
model = load_sbd_model("llama-3.1-8b-sbd")
prompt = "Please calculate: "
block_size = 16 # Adjust based on task
gamma = 0.35 # Low values for accuracy, high for speed
output = []
current = prompt
while len(output) < max_length:
block = sample_block(model, current, block_size, gamma)
output.extend(block)
current = update_context(current, block)
6.3 Parameter Tuning Guide
| Parameter | Typical Range | Adjustment Direction |
|---|---|---|
| block_size | 4-32 | Larger = faster but potential accuracy loss |
| gamma | 0.1-1.5 | Higher = faster but lower accuracy |
| temperature | 0-1 | 0=greedy decoding, 1=random sampling |
7. Frequently Asked Questions (FAQ)
Q: Does SBD require retraining models?
A: No. The paper shows effective results with just 100B tokens of fine-tuning on pretrained models.
Q: Which architectures are supported?
A: Tested on Llama-3.1 8B and Qwen-3 8B, but theoretically works with any Transformer architecture.
Q: How does it compare to diffusion models?
A: Outperforms diffusion models on code generation (68.3% vs 76.0% on HumanEval+) with faster inference.
Q: Are there special hardware requirements?
A: Runs on standard GPUs. H100 shows optimal results. Requires FP8 precision support.
Q: Does it support Chinese?
A: The paper doesn’t specify Chinese testing, but the method is language-agnostic.
8. Future Directions
-
Larger Model Validation: Current testing up to 8B parameters -
Hardware Optimization: Custom GPU kernel development -
Dynamic Block Sizing: Context-aware block size adjustment -
Multimodal Extension: Vision-language model acceleration
This article is based on the Meta FAIR team paper “Set Block Decoding is a Language Model Inference Accelerator,” with experimental data from Table 1. Always refer to the latest code implementations for deployment.
