REFRAG: Revolutionizing AI Content Generation Speed and Efficiency
Introduction
In today’s digital landscape, AI-powered content generation has become a cornerstone of many industries. From customer service chatbots to academic research assistants, systems leveraging Retrieval-Augmented Generation (RAG) technology are transforming how we interact with information. However, as these systems process increasingly longer text inputs, they face critical challenges: slower response times and higher computational demands. Enter REFRAG – a groundbreaking framework that redefines efficiency for RAG-based AI systems. This post explores how REFRAG tackles these challenges through innovative context compression techniques.
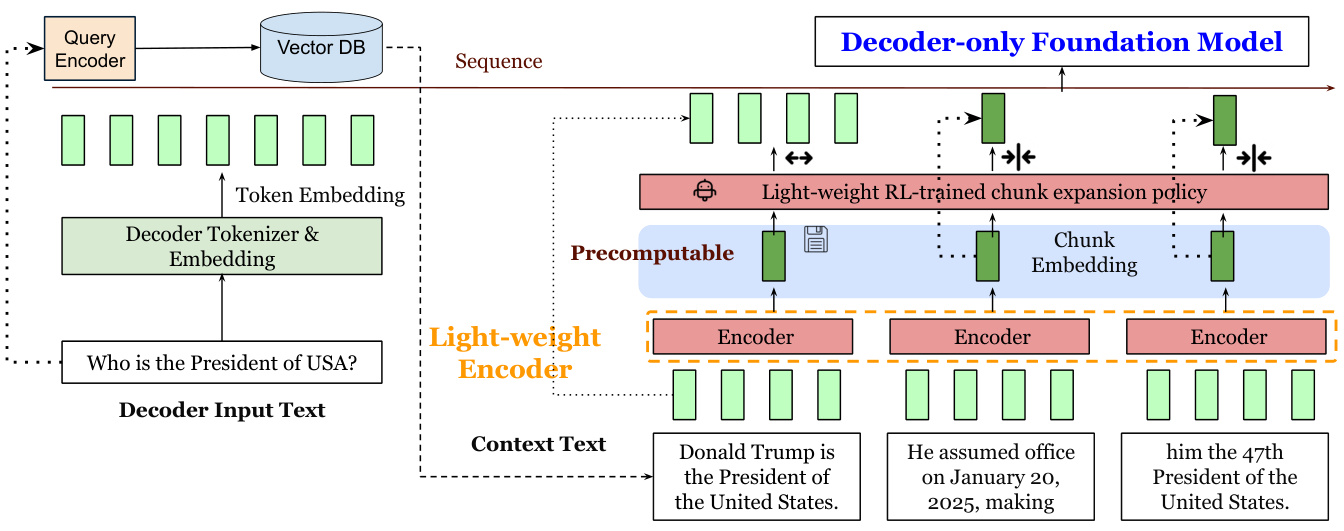
Visual comparison of input processing between standard RAG and REFRAG
Why AI Systems Need a “Weight Loss” Program
The Growing Burden of Long Contexts
Modern AI models act like supercharged librarians, retrieving and synthesizing information from vast knowledge bases. Yet when given lengthy instructions or context, they encounter two major hurdles:
-
Response Lag: The time to generate the first word (TTFT) increases quadratically with input length -
Memory Overload: Storage requirements for intermediate calculations (KV cache) grow linearly
Imagine a librarian who must scan every book in a 100,000-volume library for every query – even when only 5 books contain relevant information.
RAG’s Unique Challenges
Retrieval-Augmented Generation systems face special inefficiencies:
-
☾ Sparse Information Density: Retrieved passages often contain redundant or irrelevant content -
☾ Low Cross-Context Relevance: Most retrieved chunks have minimal connections to each other -
☾ Wasted Preprocessing: Existing retrieval systems already compute semantic relationships that get ignored during generation
Heatmap showing typical block-diagonal attention patterns in RAG contexts
REFRAG’s Three-Step Efficiency Revolution
1. Compression: Chunking for Efficiency
Core Concept:
Break long contexts into fixed-size chunks (e.g., 16 tokens each) and compress each chunk into a single vector using a lightweight encoder.
Technical Implementation:
-
☾ Use models like RoBERTa to create chunk embeddings -
☾ Project embeddings to match decoder’s token space -
☾ Reduce decoder input length by factor of k (compression rate)
2. Sensing: Smart Chunk Selection
Key Innovation:
Train a reinforcement learning policy to dynamically identify which chunks need full expansion versus compression.
Selection Strategy:
-
☾ Prioritize chunks with high semantic importance -
☾ Consider query-chunk relevance scores -
☾ Balance compression ratio with information retention
3. Expansion: On-Demand Detail Retrieval
Adaptive Process:
-
☾ Keep important chunks in full token form -
☾ Use compressed versions for less critical sections -
☾ Maintain autoregressive generation properties
Visualization of chunk selection patterns during generation
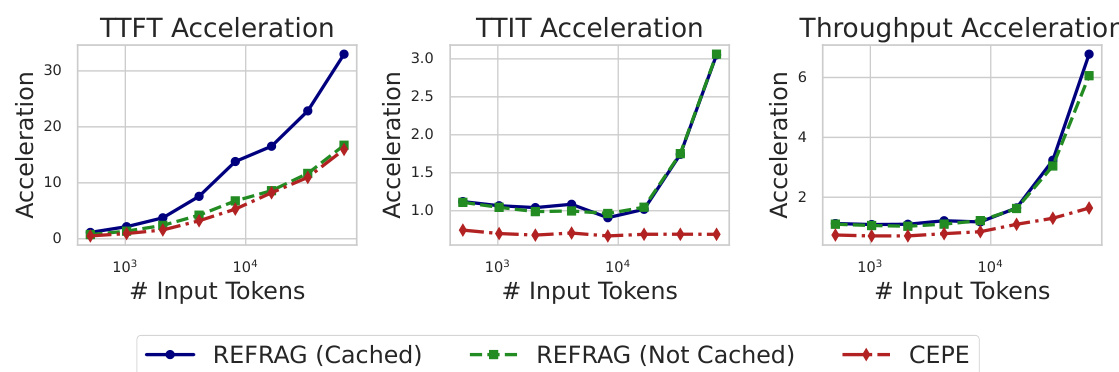
Real-World Performance Breakthroughs
Speed Improvements
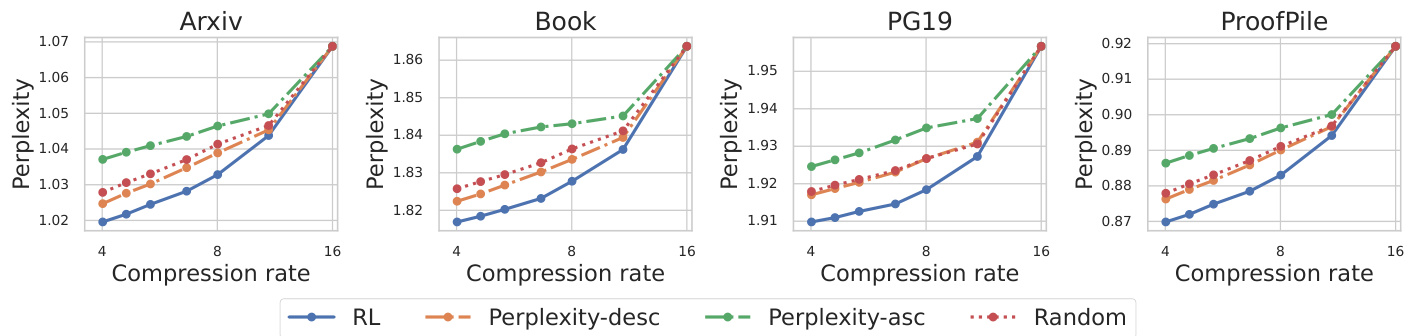
Memory Efficiency
-
☾ KV cache memory usage reduced by factor of k -
☾ Supports 16x larger context windows -
☾ Maintains or improves perplexity scores
Multi-Turn Conversation Results
Practical Applications
1. Intelligent Customer Service Systems
Challenge: Users expect real-time responses even when referencing conversation history
REFRAG Solution:
-
☾ Compress historical dialogue chunks -
☾ Dynamically expand relevant context -
☾ Maintain low latency during multi-turn interactions
2. Academic Research Assistance
Use Case: Analyzing 100+ research papers
Advantages:
-
☾ Automatically compress low-relevance paragraphs -
☾ Keep critical methodology sections in full detail -
☾ Process longer literature reviews efficiently
3. Code Understanding Tools
Implementation Example:
Technical Deep Dive
Training Strategy
Two-Phase Approach:
-
Continual Pre-training:
-
☾ Use “paragraph prediction” task to align encoder-decoder -
☾ 50% ArXiv + 50% Books domain data -
☾ 20B token training dataset
-
-
Instruction Fine-tuning:
-
☾ Domain-specific adaptation -
☾ 1.1M QA data points across 5 domains
-
Curriculum Learning Design
Progressive difficulty schedule:
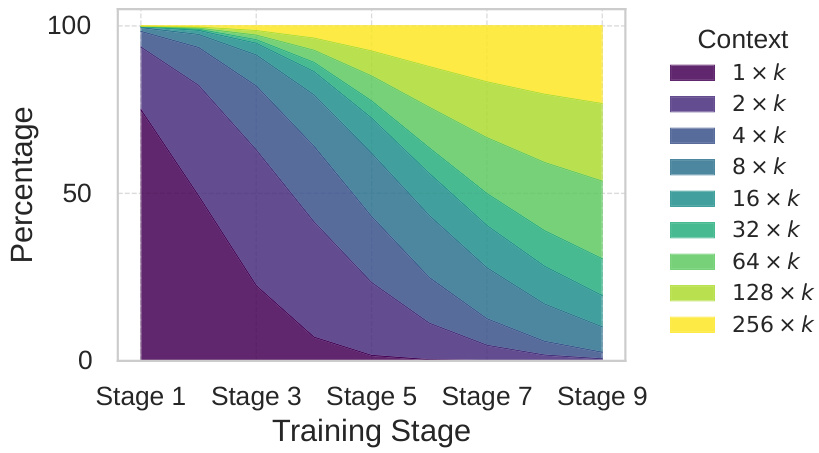
Visualization of training data mixture evolution
RL Policy Implementation
GRPO Algorithm Features:
-
☾ Grouped reward baseline -
☾ Clipped probability ratio (ε=0.2) -
☾ Perplexity-based advantage calculation
Frequently Asked Questions
Q1: Does REFRAG require model architecture modifications?
No. It works with existing LLM architectures (e.g., LLaMA) by adding an encoder module during inference.
Q2: How to choose compression rate (k)?
-
☾ k=8: Medium-length texts (4k-8k tokens) -
☾ k=16: Long-form content (>8k tokens) -
☾ k=32: Extreme compression scenarios
Q3: How does REFRAG compare to CEPE?
Q4: Deployment requirements?
-
☾ Lightweight encoder (~350M parameters) -
☾ BF16-compatible GPU (e.g., NVIDIA A100) -
☾ Additional storage for chunk embeddings
Future Directions
-
Dynamic Chunk Sizing: Context-aware block partitioning -
Multimodal Support: Extension to text-image hybrid scenarios -
Online Learning: Real-time policy adaptation -
Hardware Optimization: Custom compression instructions
Conclusion
REFRAG represents a paradigm shift in efficient AI processing. By intelligently compressing context while preserving critical information, it achieves remarkable speed improvements without sacrificing accuracy. As AI systems continue to handle increasingly complex tasks, innovations like REFRAG will be crucial for maintaining responsive, resource-efficient AI applications.
