

RecGPT: Technical Analysis of the Next-Generation Recommendation System Based on Large Language Models

1. The Dilemma of Traditional Recommendation Systems and LLM-Driven Transformation
In the daily logs of billions of user interactions on e-commerce platforms, recommendation systems must precisely capture genuine user intent from fragmented behaviors like clicks, cart additions, and favorites. Traditional systems face two core challenges:
1.1 Behavioral Overfitting
-
Problem: Over-reliance on historical click patterns creates homogenized recommendations -
Example: User A views coffee machines 3 times → continuous recommendations of similar coffee machines -
Missed Opportunity: Neglects related needs like coffee beans or grinders
1.2 Long-Tail Effect
-
Problem: 80% of exposure goes to top products, stifling niche items -
Data Point: New products receive 1/5 the exposure of established items -
Impact: Small designer brands get <0.3% visibility
1.3 RecGPT’s Breakthrough
By leveraging Large Language Models’ semantic understanding, RecGPT transforms recommendation logic from “behavior fitting” to “intent comprehension”:
| Metric | Improvement | Business Impact |
|---|---|---|
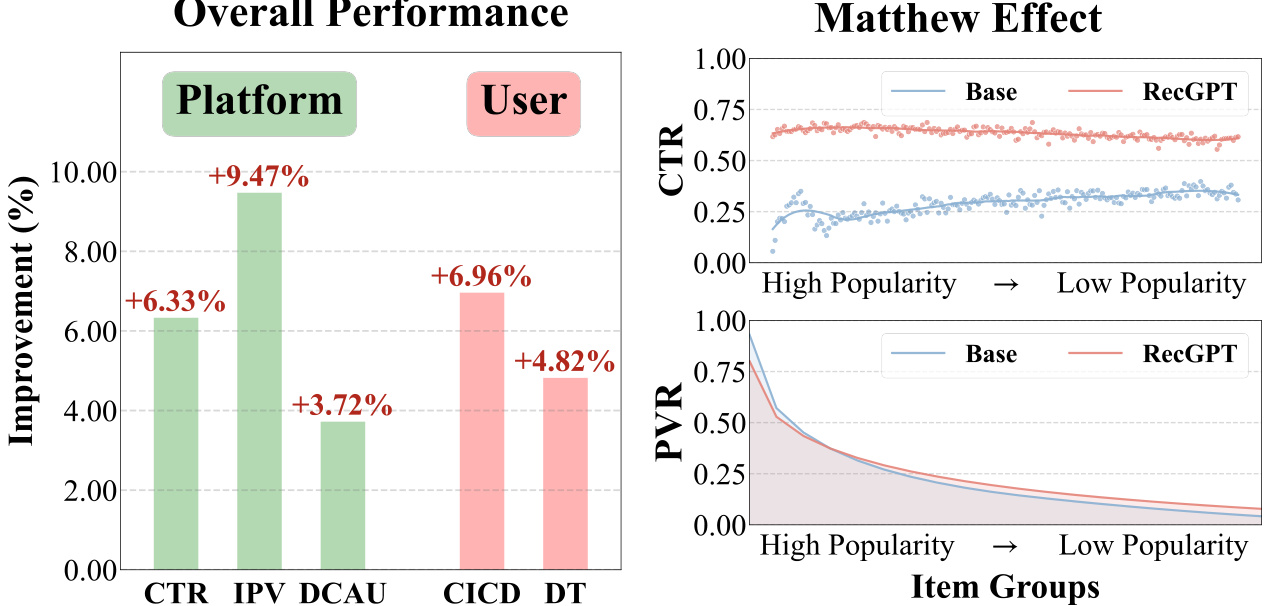
| Clicked Item Category Diversity (CICD) | +6.96% | Breaks filter bubbles |
| Merchant Exposure Equity | +9.47% | Balances market opportunities |
| User Dwell Time (DT) | +4.82% | Enhances engagement |
2. Deep Dive into RecGPT’s Technical Architecture
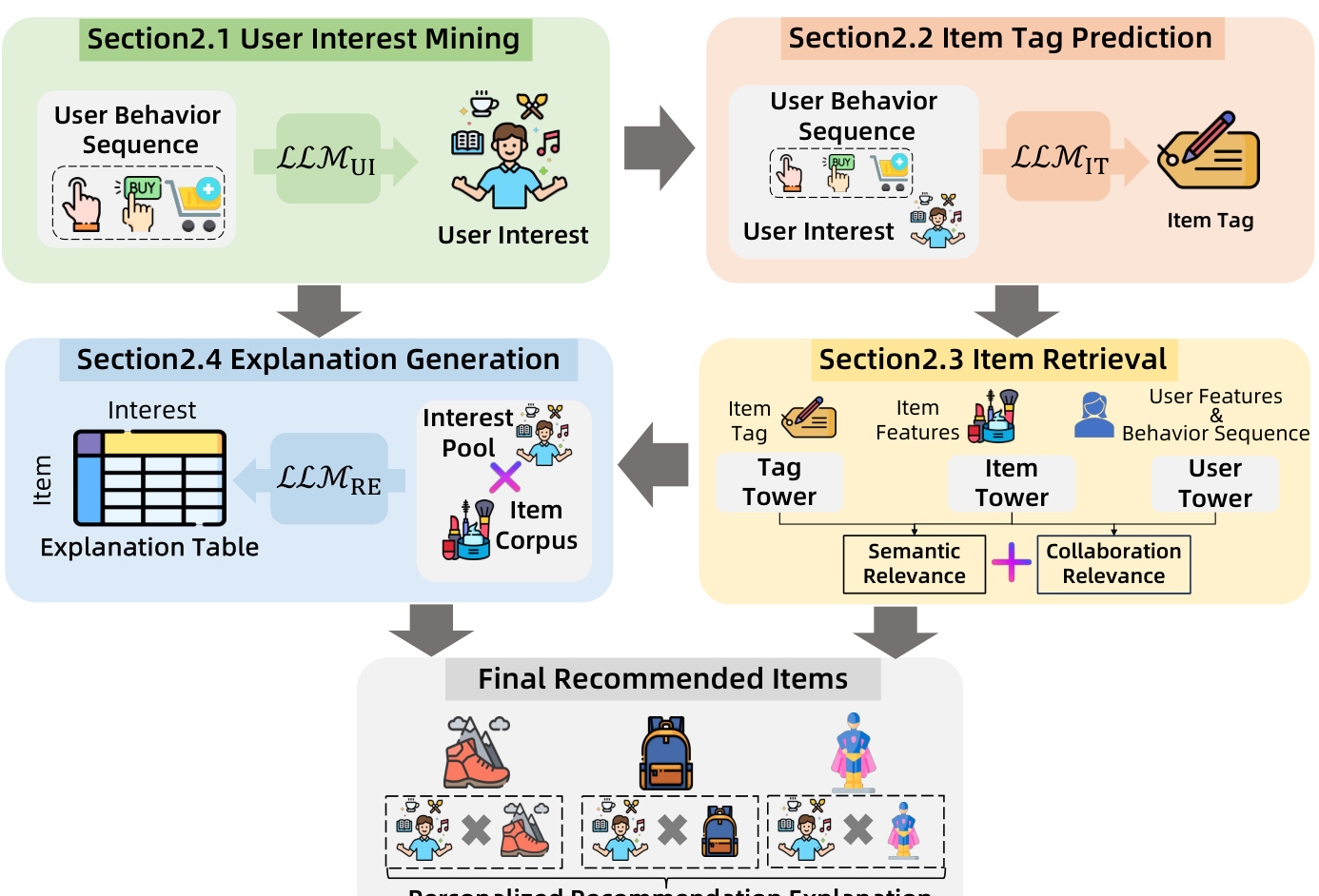
2.1 User Intent Mining Module
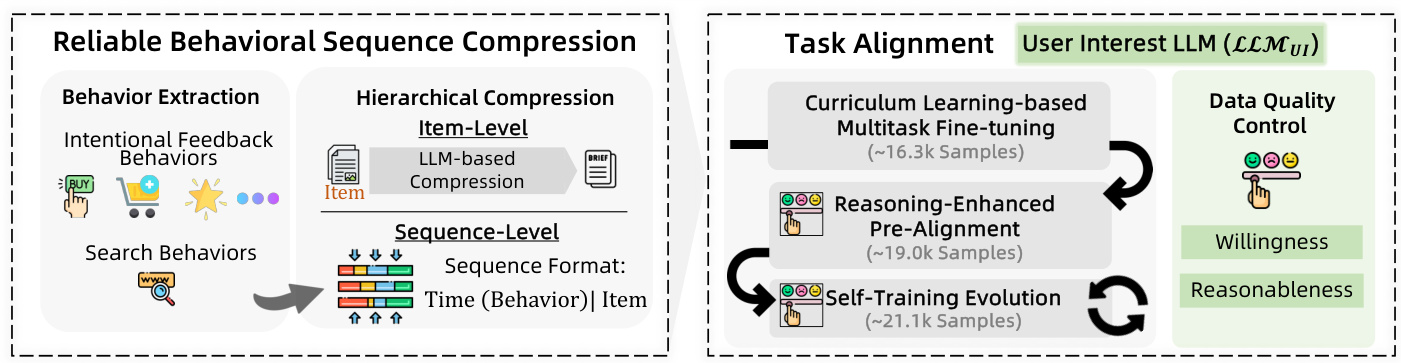
2.1.1 Ultra-Long Sequence Processing
Challenge: Average user behavior sequence exceeds 37,000 interactions, surpassing LLM’s 128K token limit
Solution: Hierarchical Behavior Compression
| Compression Level | Method | Efficiency Gain |
|---|---|---|
| Behavior-level | Extract high-confidence actions (favorites/purchases/searches) | 40% length reduction |
| Sequence-level | Temporal-behavior aggregation + item reverse grouping | Additional 58% reduction |
Sample Compressed Output:
Time1(search:running shoes,click:socks),Time2(cart:water bottle)|ItemA,ItemB,ItemC
2.1.2 Multi-Stage Task Alignment
Three-phase training strategy enhances intent understanding:
-
Curriculum Learning Pre-training (16.3k samples)
-
Foundation: Query categorization, query-item relevance -
Intermediate: E-commerce Q&A, product feature extraction -
Advanced: Causal reasoning, keyword extraction
-
-
Reasoning-Enhanced Pre-training (19.0k samples)
-
Uses DeepSeek-R1 to generate high-quality training data -
Focus: Cross-behavior intent recognition, implicit need inference
-
-
Self-Training Evolution (21.1k samples)
-
Model self-generates training data -
LLM-Judge system automates quality control
-

2.2 Item Tag Prediction Module
2.2.1 Tag Format Standard
Outputs structured as “Modifier + Core Word”, e.g.,
Outdoor waterproof non-slip hiking boots
2.2.2 Multi-Constraint Prompt Engineering
Five core constraints guide generation:
| Constraint | Requirement | Example |
|---|---|---|
| Interest Consistency | Tags must align with user interests | Reject: Embroidery pillowcase (skincare interest) |
| Diversity | Generate ≥50 tags per user | Covers 8+ categories like apparel/beauty/home |
| Semantic Precision | Avoid vague terms | Reject: “fashion sports equipment” |
| Freshness | Prioritize new categories | Summer focus:防晒衣/凉鞋 |
| Seasonal Relevance | Context-aware recommendations | Winter:羽绒服/保暖内衣 |
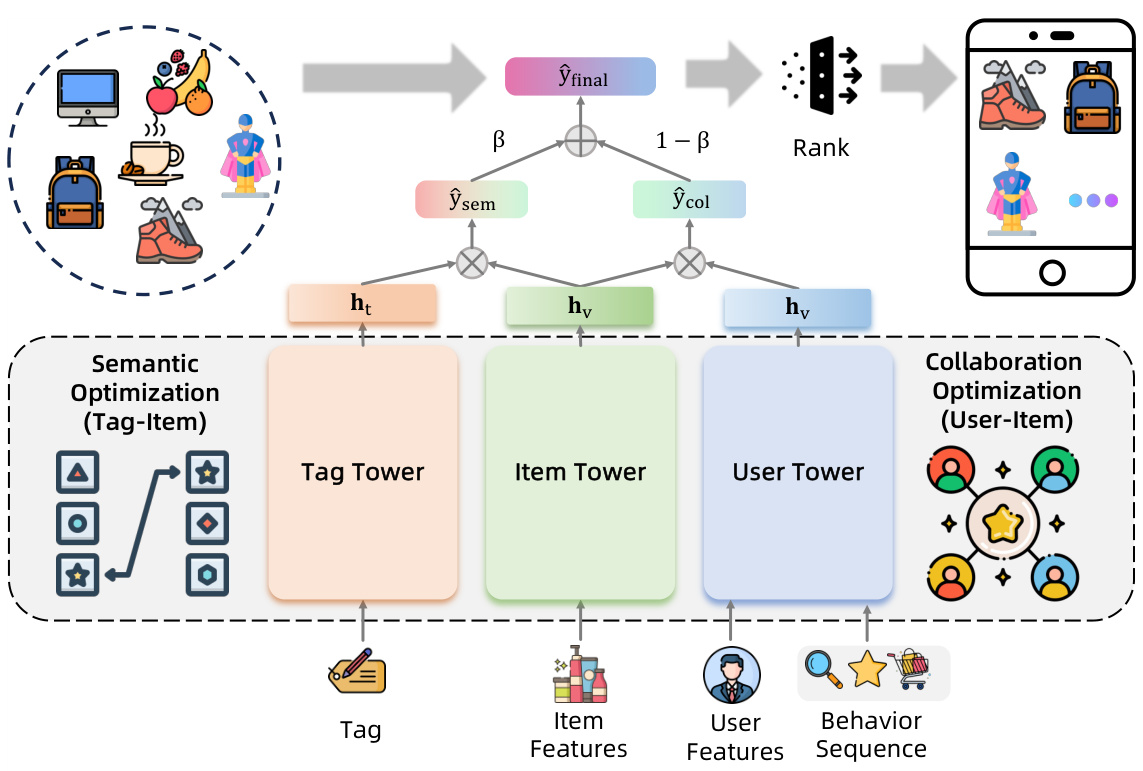
2.3 Three-Tower Retrieval Architecture
Innovative “User-Item-Tag” framework:
| Tower | Input Features | Output | Function |
|---|---|---|---|
| User | User ID + multi-behavior sequences | 256D | Captures collaborative signals |
| Item | Product attributes + stats | 256D | Base product representation |
| Tag | LLM-generated tag text | 256D | Injects semantic understanding |
Fusion Formula:
Final Score = β×User Score + (1-β)×Tag Score
(Optimal β=0.6)
3. RecGPT Deployment Results
3.1 Online A/B Test Metrics (June 17-20, 2025)
| Metric | Improvement | Interpretation |
|---|---|---|
| User Dwell Time (DT) | +4.82% | Enhanced content appeal |
| Clicked Category Diversity (CICD) | +6.96% | Breaks information silos |
| Exposed Category Diversity (EICD) | +0.11% | Richer displays |
| Item Page Views (IPV) | +9.47% | Increased exploration |
| Click-Through Rate (CTR) | +6.33% | Higher precision |
| Daily Active Click Users (DCAU) | +3.72% | Better retention |

3.2 Merchant Ecosystem Improvement
Analysis of product group CTR/PVR distribution shows:
| Product Group | CTR Change | Exposure Impact |
|---|---|---|
| Top 1% | -1.2% | Prevents over-concentration |
| Top 10-30% | +8.7% | Boosts mid-tier visibility |
| Rank >50% | +23% | Long-tail growth |

4. Technical Challenges & Future Directions
4.1 Current Limitations
-
Sequence Length Constraints
-
2% of user histories still exceed 128K tokens -
Need better context window management
-
-
Multi-Objective Optimization
-
Current periodic updates lack real-time adaptation -
Separate training of different tasks
-
4.2 Future Roadmap
-
RL-Based Multi-Objective Learning
-
Implement ROLL framework for online feedback -
Optimize: Engagement/Conversion/Platform health
-
-
End-to-End LLM Judge System
-
Develop RLHF-based evaluation -
Build unified multi-task assessment
-
5. Frequently Asked Questions
Q1: How does RecGPT solve traditional recommendation filter bubbles?
A: Through three semantic understanding layers:
-
Intent mining identifies cross-category interests -
Tag generation enforces 50+ diverse tags -
Retrieval balances collaborative and semantic scores
Q2: What hardware resources does RecGPT require?
A:
-
Training: 8×A100 GPUs (model alignment) -
Serving: FP8 quantization + KV caching -
57% faster inference for large-scale deployment
Q3: What impact does RecGPT have on small merchants?
A:
-
23% more exposure for tail products -
More balanced ad distribution -
Breaks “rich get richer” cycles
Q4: How is tag quality ensured?
A:
-
4D quality control: Relevance/Consistency/Specificity/Validity -
Human+LLM dual evaluation -
15% rejection rate for low-quality tags

