

Qwen3-TTS Deep Dive: Architecture, Features, Deployment, and Performance Review
As artificial intelligence technology advances rapidly, Text-to-Speech (TTS) technology has evolved from simple robotic reading into a sophisticated system capable of understanding context, simulating complex emotions, and supporting real-time multilingual interaction. Among the many open-source models available, Qwen3-TTS has become a focal point for developers and researchers due to its powerful end-to-end architecture, extremely low latency, and exceptional speech restoration capabilities.
Based on official documentation and technical reports, this article provides an in-depth analysis of Qwen3-TTS’s technical details, model architecture, diverse application scenarios, and detailed performance evaluation data, helping you fully understand the potential and application methods of this tool.
Core Overview and Technical Breakthroughs
Qwen3-TTS is a text-to-speech model covering 10 major languages: Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian, along with various dialectal voice profiles. It is not merely a reading tool but an intelligent speech generation system with strong contextual understanding. It can adaptively control tone, speaking rate, and emotional expression based on instructions and text semantics, significantly improving robustness against noisy text.

To meet the demands of different scenarios, Qwen3-TTS achieves breakthroughs in four key technical dimensions:
1. Robust Speech Representation
The model is powered by the self-developed Qwen3-TTS-Tokenizer-12Hz. This component achieves efficient acoustic compression and high-dimensional semantic modeling of speech signals. It fully preserves paralinguistic information (like breathing and pauses) and acoustic environmental features, enabling high-speed, high-fidelity speech reconstruction through a lightweight non-DiT (Diffusion Transformer) architecture. This means the generated voice is not only clear but also rich in “human-like” characteristics.
2. Universal End-to-End Architecture
Qwen3-TTS utilizes a discrete multi-codebook Large Language Model (LLM) architecture. This design realizes full-information end-to-end speech modeling, completely bypassing the information bottlenecks and cascading errors common in traditional LM+Diffusion model schemes. This significantly enhances the model’s versatility, generation efficiency, and performance ceiling, allowing a single model to handle various complex speech generation tasks.
3. Extreme Low-Latency Streaming Generation
For real-time interaction scenarios (such as live conversational assistants), latency is a critical metric. Based on an innovative “Dual-Track” hybrid streaming generation architecture, a single Qwen3-TTS model supports both streaming and non-streaming generation. In practice, it can output the first audio packet immediately after inputting a single character, with end-to-end synthesis latency as low as 97ms. This performance meets the rigorous demands of real-time interactive applications.
4. Intelligent Text Understanding and Voice Control
The model supports speech generation driven by natural language instructions. Users can flexibly control multi-dimensional acoustic attributes such as timbre, emotion, and prosody through text. By deeply integrating text semantic understanding, the model adaptively adjusts tone, rhythm, and emotional expression, truly realizing a “what you imagine is what you hear” anthropomorphic output.
Model Architecture and Version Selection
Architecture Design
Qwen3-TTS’s architecture is designed to balance generation quality with inference efficiency. Its core lies in combining high-dimensional semantic modeling with the advantages of a lightweight vocoder, using discrete codebooks as an intermediate representation. This allows the language model to directly predict speech units, significantly reducing computational costs while maintaining high audio quality.

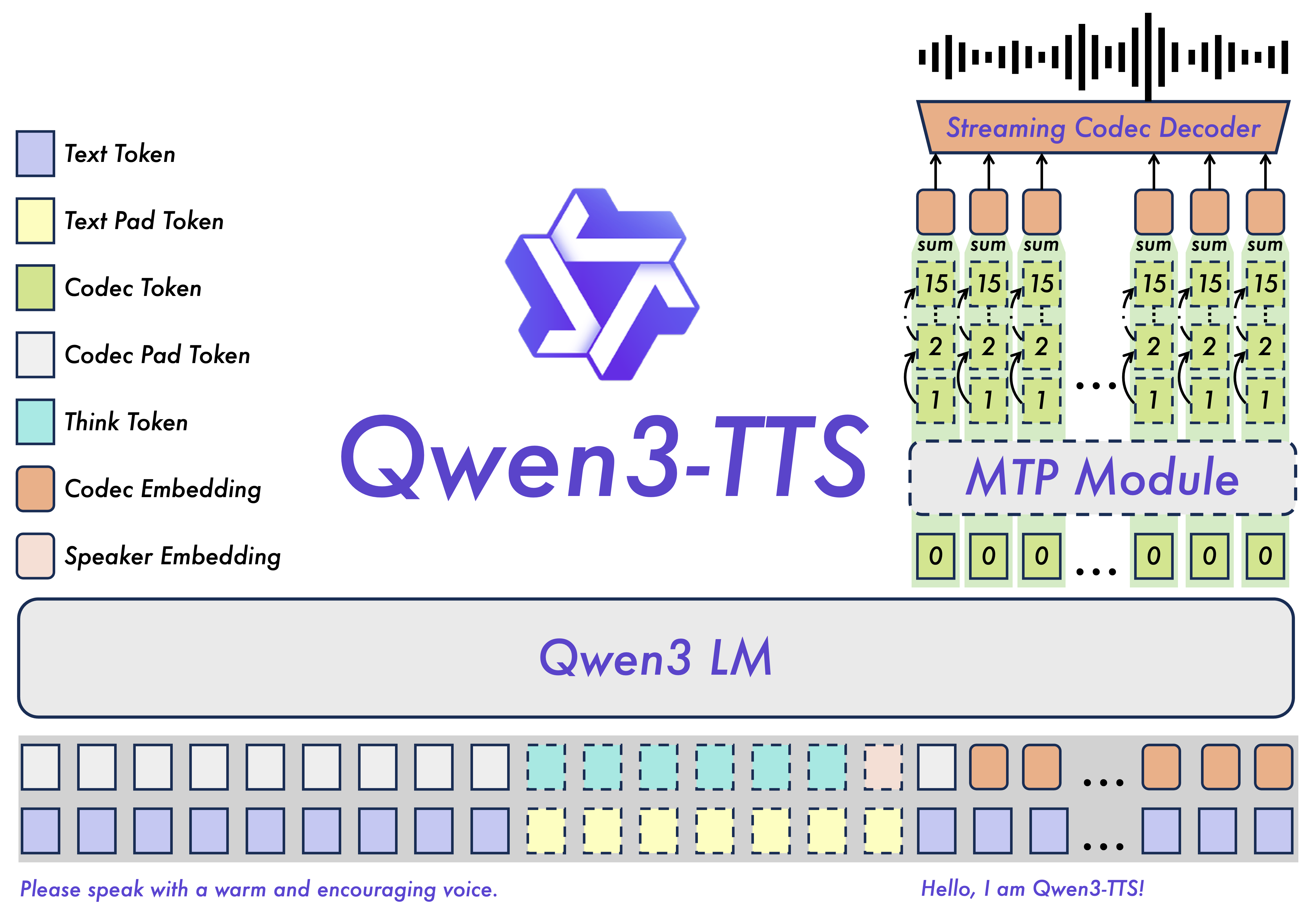
Available Model Versions and Download Guide
To accommodate different development needs, Qwen3-TTS has released multiple models of varying specifications. Below is a detailed introduction to the released models. You can choose the most suitable version based on your specific application scenario.
Tokenizer
The foundation for speech encoding and decoding for all models.
- •
Qwen3-TTS-Tokenizer-12Hz: Responsible for encoding input speech into codebooks and decoding codebooks back to speech.
Main Generation Model Comparison Table
| Model Name | Key Features | Language Support | Streaming | Instruction Control |
|---|---|---|---|---|
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | Performs voice design based on user-provided descriptions (e.g., timbre, age, personality). | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ Supported | ✅ Supported |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | Control target timbres via user instructions; supports 9 premium timbres covering various gender, age, language, and dialect combinations. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ Supported | ✅ Supported |
| Qwen3-TTS-12Hz-1.7B-Base | Base model capable of 3-second rapid voice cloning from user audio input; can be used for fine-tuning other models. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ Supported | – |
| Qwen3-TTS-12Hz-0.6B-CustomVoice | Supports 9 premium timbres. Smaller model size. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ Supported | – |
| Qwen3-TTS-12Hz-0.6B-Base | Base model capable of 3-second rapid voice cloning; can be used for fine-tuning. Smaller model size. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ Supported | – |
How to Download:
When loading a model in the qwen-tts package or vLLM, weights are downloaded automatically. However, if your runtime environment is not suitable for downloading during execution, you can use the following commands to download manually.
Download via ModelScope (Recommended for users in Mainland China):
pip install -U modelscope
modelscope download --model Qwen/Qwen3-TTS-Tokenizer-12Hz --local_dir ./Qwen3-TTS-Tokenizer-12Hz
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local_dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-Base --local_dir ./Qwen3-TTS-12Hz-1.7B-Base
modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-Base --local_dir ./Qwen3-TTS-12Hz-0.6B-Base
Download via Hugging Face:
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-TTS-Tokenizer-12Hz --local_dir ./Qwen3-TTS-Tokenizer-12Hz
huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local_dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-Base --local_dir ./Qwen3-TTS-12Hz-1.7B-Base
huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-Base --local_dir ./Qwen3-TTS-12Hz-0.6B-Base
Quick Start: Environment Setup and Usage Guide
Environment Setup
The fastest way to get started is by installing the qwen-tts Python package from PyPI. To avoid dependency conflicts, it is highly recommended to set up a fresh, isolated environment.
Create a Python 3.12 environment:
conda create -n qwen3-tts python=3.12 -y
conda activate qwen3-tts
Install the core package:
pip install -U qwen-tts
If you plan to develop locally or modify the code, install from source:
git clone https://github.com/QwenLM/Qwen3-TTS.git
cd Qwen3-TTS
pip install -e .
Performance Optimization Tip:
It is recommended to install FlashAttention 2 to reduce VRAM usage and boost inference speed.
pip install -U flash-attn --no-build-isolation
Note: If your machine has less than 96GB of RAM and many CPU cores, it is advisable to limit concurrent jobs:
MAX_JOBS=4 pip install -U flash-attn --no-build-isolation
FlashAttention 2 is only available when the model is loaded in torch.float16 or torch.bfloat16.
Python Package Usage Guide
1. Custom Voice Generation
Suitable for Qwen3-TTS-12Hz-1.7B/0.6B-CustomVoice models. You can specify the language, speaker, and emotion instructions.
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# Single inference
wavs, sr = model.generate_custom_voice(
text="其实我真的有发现,我是一个特别善于观察别人情绪的人。",
language="Chinese", # Can also be set to "Auto" or omitted for auto-adaptation; if the target language is known, set it explicitly.
speaker="Vivian",
instruct="用特别愤怒的语气说", # Omit if not needed.
)
sf.write("output_custom_voice.wav", wavs[0], sr)
List of Supported Preset Speakers:
| Speaker | Voice Description | Native Language |
|---|---|---|
| Vivian | Bright, slightly edgy young female voice. | Chinese |
| Serena | Warm, gentle young female voice. | Chinese |
| Uncle_Fu | Seasoned male voice with a low, mellow timbre. | Chinese |
| Dylan | Youthful Beijing male voice with a clear, natural timbre. | Chinese (Beijing Dialect) |
| Eric | Lively Chengdu male voice with a slightly husky brightness. | Chinese (Sichuan Dialect) |
| Ryan | Dynamic male voice with strong rhythmic drive. | English |
| Aiden | Sunny American male voice with a clear midrange. | English |
| Ono_Anna | Playful Japanese female voice with a light, nimble timbre. | Japanese |
| Sohee | Warm Korean female voice with rich emotion. | Korean |
2. Voice Design
Suitable for the Qwen3-TTS-12Hz-1.7B-VoiceDesign model. You can create voices using natural language descriptions, such as “young female voice” or “deep male voice.”
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
wavs, sr = model.generate_voice_design(
text="哥哥,你回来啦,人家等了你好久好久了,要抱抱!",
language="Chinese",
instruct="体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
)
sf.write("output_voice_design.wav", wavs[0], sr)
3. Voice Cloning
Suitable for Qwen3-TTS-12Hz-1.7B/0.6B-Base models. You only need to provide a reference audio clip and its transcript to clone the timbre.
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
ref_audio = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone.wav"
ref_text = "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you."
wavs, sr = model.generate_voice_clone(
text="I am solving the equation: x = [-b ± √(b²-4ac)] / 2a? Nobody can — it's a disaster (◍•͈⌔•͈◍), very sad!",
language="English",
ref_audio=ref_audio,
ref_text=ref_text,
)
sf.write("output_voice_clone.wav", wavs[0], sr)
Advanced Usage: Reusing Prompt Features
If you need to use the same reference timbre multiple times (to avoid recomputing features), you can build the prompt once.
prompt_items = model.create_voice_clone_prompt(
ref_audio=ref_audio,
ref_text=ref_text,
x_vector_only_mode=False,
)
wavs, sr = model.generate_voice_clone(
text=["Sentence A.", "Sentence B."],
language=["English", "English"],
voice_clone_prompt=prompt_items,
)
4. Voice Design then Clone
This is a highly practical combined workflow:
-
Use the VoiceDesign model to synthesize a short reference audio clip that matches your target persona. -
Feed that audio into the Base model’s create_voice_clone_promptto build a reusable prompt. -
Call generate_voice_cloneto generate new content without re-extracting features every time. This is extremely useful for maintaining character consistency across long texts.
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# Step 1: Create reference audio using VoiceDesign model
design_model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
ref_text = "H-hey! You dropped your... uh... calculus notebook? I mean, I think it's yours? Maybe?"
ref_instruct = "Male, 17 years old, tenor range, gaining confidence - deeper breath support now, though vowels still tighten when nervous"
ref_wavs, sr = design_model.generate_voice_design(
text=ref_text,
language="English",
instruct=ref_instruct
)
sf.write("voice_design_reference.wav", ref_wavs[0], sr)
# Step 2: Build cloning prompt using Base model
clone_model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
voice_clone_prompt = clone_model.create_voice_clone_prompt(
ref_audio=(ref_wavs[0], sr), # or use file path "voice_design_reference.wav"
ref_text=ref_text,
)
# Step 3: Reuse prompt to generate multiple lines
sentences = [
"No problem! I actually... kinda finished those already? If you want to compare answers or something...",
"What? No! I mean yes but not like... I just think you're... your titration technique is really precise!",
]
wavs, sr = clone_model.generate_voice_clone(
text=sentences,
language=["English", "English"],
voice_clone_prompt=voice_clone_prompt,
)
for i, w in enumerate(wavs):
sf.write(f"clone_batch_{i}.wav", w, sr)
5. Tokenizer Encode and Decode
If you only need to encode and decode audio for transport or training, you can use Qwen3TTSTokenizer.
import soundfile as sf
from qwen_tts import Qwen3TTSTokenizer
tokenizer = Qwen3TTSTokenizer.from_pretrained(
"Qwen/Qwen3-TTS-Tokenizer-12Hz",
device_map="cuda:0",
)
enc = tokenizer.encode("https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/tokenizer_demo_1.wav")
wavs, sr = tokenizer.decode(enc)
sf.write("decode_output.wav", wavs[0], sr)
Local Web UI Demo Deployment
After installing the qwen-tts package, you can run qwen-tts-demo to launch the Web UI.
Startup command examples:
# CustomVoice model
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --ip 0.0.0.0 --port 8000
# VoiceDesign model
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --ip 0.0.0.0 --port 8000
# Base model
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base --ip 0.0.0.0 --port 8000
Then visit http://<your-ip>:8000 in your browser.
HTTPS Notes for Base Model:
To prevent microphone permission issues in modern browsers when accessing remotely, Base model deployments should/must run over HTTPS. You can enable HTTPS using --ssl-certfile and --ssl-keyfile.
Generate a self-signed certificate (valid for 365 days):
openssl req -x509 -newkey rsa:2048 \
-keyout key.pem -out cert.pem \
-days 365 -nodes \
-subj "/CN=localhost"
Run the demo with HTTPS:
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base \
--ip 0.0.0.0 --port 8000 \
--ssl-certfile cert.pem \
--ssl-keyfile key.pem \
--no-ssl-verify
Then visit https://<your-ip>:8000.
vLLM Integration and Inference Optimization
vLLM provides Day-0 support for Qwen3-TTS. You can use vLLM-Omni for efficient deployment and inference. Currently, offline inference is supported, with online serving coming in future updates.
Offline Inference Example
First, clone the vLLM-Omni repository and navigate to the examples directory:
git clone https://github.com/vllm-project/vllm-omni.git
cd vllm-omni/examples/offline_inference/qwen3_tts
Execute different tasks:
# Single sample CustomVoice task
python end2end.py --query-type CustomVoice
# Batch sample CustomVoice task
python end2end.py --query-type CustomVoice --use-batch-sample
# Single sample VoiceDesign task
python end2end.py --query-type VoiceDesign
# Batch sample VoiceDesign task
python end2end.py --query-type VoiceDesign --use-batch-sample
# Single sample Base task (in-context learning mode)
python end2end.py --query-type Base --mode-tag icl
In-Depth Performance Evaluation
To objectively measure Qwen3-TTS’s performance, the team conducted extensive evaluations on multiple benchmark datasets. All inferences were run with dtype=torch.bfloat16 and max_new_tokens=2048.
1. Speech Generation Benchmarks
Zero-Shot Speech Generation on Seed-TTS Test Set
Metric: Word Error Rate (WER), lower is better.
| Model | Chinese WER | English WER |
|---|---|---|
| Seed-TTS (Anastassiou et al., 2024) | 1.12 | 2.25 |
| MaskGCT | 2.27 | 2.62 |
| E2 TTS | 1.97 | 2.19 |
| F5-TTS | 1.56 | 1.83 |
| Spark TTS | 1.20 | 1.98 |
| Llasa-8B | 1.59 | 2.97 |
| KALL-E | 0.96 | 1.94 |
| FireRedTTS 2 | 1.14 | 1.95 |
| CosyVoice 3 | 0.71 | 1.45 |
| MiniMax-Speech | 0.83 | 1.65 |
| Qwen3-TTS-25Hz-0.6B-Base | 1.18 | 1.64 |
| Qwen3-TTS-25Hz-1.7B-Base | 1.10 | 1.49 |
| Qwen3-TTS-12Hz-0.6B-Base | 0.92 | 1.32 |
| Qwen3-TTS-12Hz-1.7B-Base | 0.77 | 1.24 |
Analysis: On the Seed-TTS test set, Qwen3-TTS-12Hz-1.7B-Base achieved the best performance in English and was second only to CosyVoice 3 in Chinese, demonstrating extremely strong consistency and low error rates.
2. Multilingual Speech Generation
TTS Multilingual Test Set
Metric: WER (Content Consistency, lower is better) and Cosine Similarity (SIM, Speaker Similarity, higher is better).
| Language | Qwen3-TTS-12Hz-1.7B-Base WER | Qwen3-TTS-12Hz-1.7B-Base SIM | MiniMax WER | ElevenLabs SIM |
|---|---|---|---|---|
| Chinese | 0.777 | 0.799 | 2.252 | 0.677 |
| English | 0.934 | 0.775 | 2.164 | 0.613 |
| German | 1.235 | 0.775 | 1.906 | 0.614 |
| Italian | 0.948 | 0.817 | 1.543 | 0.579 |
| Portuguese | 1.526 | 0.817 | 1.877 | 0.711 |
| Spanish | 1.126 | 0.814 | 1.029 | 0.615 |
| Japanese | 3.823 | 0.788 | 3.519 | 0.738 |
| Korean | 1.755 | 0.799 | 1.747 | 0.700 |
| French | 2.858 | 0.714 | 4.099 | 0.535 |
| Russian | 3.212 | 0.792 | 4.281 | 0.676 |
Analysis: Qwen3-TTS-12Hz-1.7B-Base achieves an excellent balance between WER (content accuracy) and SIM (speaker similarity) across most languages. It outperforms comparison models like MiniMax and ElevenLabs in Chinese, English, Italian, Portuguese, and French.
3. Cross-Lingual Speech Generation
Cross-Lingual Benchmark
Metric: Mixed Error Rate (WER for English, CER for others, lower is better).
| Task | Qwen3-TTS-12Hz-1.7B-Base | CosyVoice3 | CosyVoice2 |
|---|---|---|---|
| En-to-Zh | 4.77 | 5.09 | 13.5 |
| Ja-to-Zh | 3.43 | 3.05 | 48.1 |
| Ko-to-Zh | 1.08 | 1.06 | 7.70 |
| Zh-to-En | 2.77 | 2.98 | 6.47 |
| Ja-to-En | 3.04 | 4.20 | 17.1 |
| Ko-to-En | 3.09 | 4.19 | 11.2 |
| Zh-to-Ja | 8.40 | 7.08 | 13.1 |
| En-to-Ja | 7.21 | 6.80 | 14.9 |
| Ko-to-Ja | 3.67 | 3.93 | 5.86 |
| Zh-to-Ko | 4.82 | 14.4 | 24.8 |
| En-to-Ko | 5.14 | 5.87 | 21.9 |
| Ja-to-Ko | 5.59 | 7.92 | 21.5 |
Analysis: In 12 cross-lingual tasks, Qwen3-TTS-12Hz-1.7B-Base achieved the best score in 9, significantly outperforming the CosyVoice series, demonstrating powerful cross-lingual transfer capabilities.
4. Controllable Speech Generation
InstructTTSEval Evaluation
Metric: Attribute Perception and Synthesis accuracy (APS), Description-Speech Consistency (DSD), and Response Precision (RP).
| Type | Model | English APS | English DSD | English RP |
|---|---|---|---|---|
| Voice Design | Qwen3TTS-12Hz-1.7B-VD | 82.9 | 82.4 | 68.4 |
| Voice Design | Mimo-Audio-7B-Instruct | 80.6 | 77.6 | 59.5 |
| Voice Design | Hume | 83.0 | 75.3 | 54.3 |
| Target Speaker | Qwen3TTS-12Hz-1.7B-CustomVoice | 77.3 | 77.1 | 63.7 |
| Target Speaker | Gemini-flash | 92.3 | 93.8 | 80.1 |
Analysis: In voice design tasks, Qwen3-TTS performs excellently, significantly leading models like Mimo and Hume across all metrics. While Gemini-flash excels in target speaker tasks, Qwen3-TTS, as a specialized TTS model, remains highly competitive in controllability.
5. Speech Tokenizer Benchmarks
Semantic Speech Tokenizer Comparison
Metric: PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility), UTMOS (Subjective MOS Prediction), SIM (Similarity).
| Model | PESQ_WB | STOI | UTMOS | SIM |
|---|---|---|---|---|
| SpeechTokenizer | 2.60 | 0.92 | 3.90 | 0.85 |
| X-codec 2 | 2.43 | 0.92 | 4.13 | 0.82 |
| Mimi | 2.88 | 0.94 | 3.87 | 0.87 |
| Qwen-TTS-Tokenizer-12Hz | 3.21 | 0.96 | 4.16 | 0.95 |
Analysis: The self-developed Qwen-TTS-Tokenizer-12Hz significantly outperforms industry mainstream tokenizers (like Mimi and X-codec 2) across all key metrics, laying a solid foundation for the high-fidelity reconstruction of Qwen3-TTS.
DashScope API Usage
For convenient user access, Qwen3-TTS is also available via the DashScope API.
- •
Real-time API for Custom Voice Model: Documentation (China) | Documentation (International) - •
Real-time API for Voice Clone Model: Documentation (China) | Documentation (International) - •
Real-time API for Voice Design Model: Documentation (China) | Documentation (International)
Frequently Asked Questions (FAQ)
Q: What languages does Qwen3-TTS support?
A: Currently, it supports 10 major languages: Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian, along with various dialectal voice profiles.
Q: What is the difference between the Base model and the CustomVoice model?
A: The Base model is primarily designed for voice cloning, where you input a reference audio clip to mimic its timbre. The CustomVoice model includes several built-in premium preset voices (like Vivian, Ryan) and supports changing emotions and tones via instructions, making it more suitable for scenarios requiring direct use of fixed characters.
Q: Which produces better results: Voice Design or Voice Cloning?
A: It depends on your specific needs. If you have a specific target audio sample, voice cloning can reproduce that timbre to the greatest extent. If you want to create a character image that doesn’t exist (e.g., “a young, lively American girl”), the Voice Design model can generate a corresponding voice based on text descriptions. You can even combine both: first use the design model to generate reference audio, then use the clone model to generate content in batches.
Q: What hardware specifications are required for inference?
A: It is recommended to use a CUDA-compatible GPU. While the documentation does not specify a minimum VRAM requirement, considering the 1.7B parameter count and the use of FlashAttention, it is recommended to have at least 8GB of VRAM for a smooth experience. Using bfloat16 precision can further save memory.
Q: How can I implement streaming generation?
A: Qwen3-TTS’s model architecture natively supports streaming generation. When using vLLM or the qwen-tts package, simply calling the relevant interfaces allows you to leverage its low-latency streaming output capability.
Q: Why does the Web UI deployment for the Base model require HTTPS?
A: This is because the Base model’s Web UI needs to access the browser’s microphone to record reference audio. Modern browsers, for security reasons, typically only allow microphone access over HTTPS (or localhost). Therefore, SSL certificates must be configured for remote access.
Q: What is the difference between the 12Hz and 25Hz models?
A: The 12Hz models utilize the more advanced 12Hz Tokenizer (Qwen-TTS-Tokenizer-12Hz), which offers higher compression ratios and semantic modeling capabilities. According to evaluation data, the 12Hz models generally outperform the 25Hz models in terms of audio quality (PESQ, STOI) and most WER metrics.

