In the rapidly evolving landscape of artificial intelligence, large language models (LLMs) are advancing at an unprecedented pace. The recently released Qwen3-Next-80B series by the Qwen team represents a significant milestone in this journey. This new generation of models not only substantially enhances capabilities and efficiency but also introduces deep optimizations for long-context processing, complex reasoning, and agent-based applications. This article provides a systematic overview of the core features, performance metrics, and practical deployment methods of these models, offering a comprehensive reference for researchers and engineers.
1. Model Architecture and Core Innovations
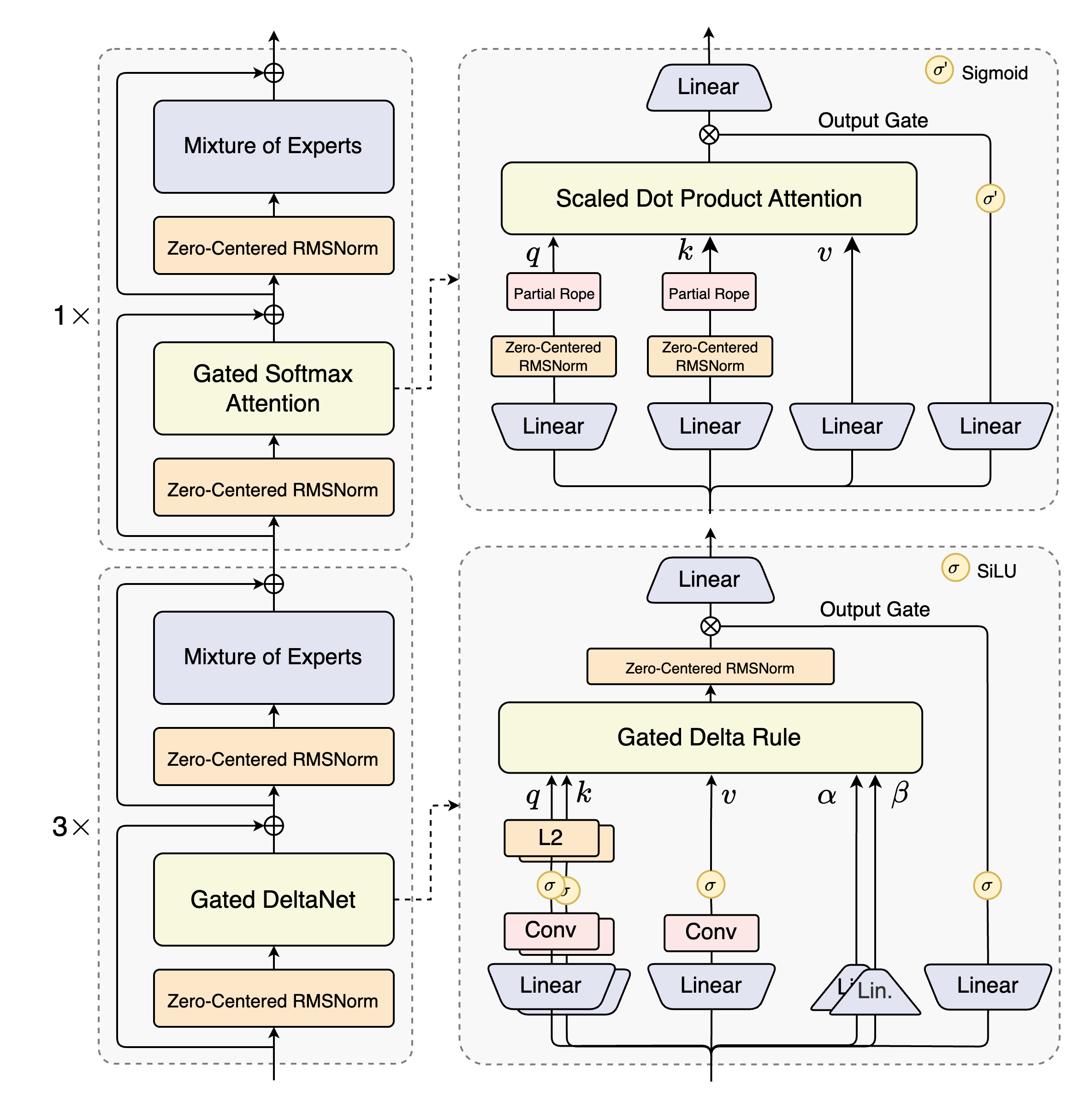
The Qwen3-Next-80B series includes two main versions: Qwen3-Next-80B-A3B-Instruct and Qwen3-Next-80B-A3B-Thinking. Both are built on the same underlying architecture but are optimized for different functional priorities. The Instruct version is designed for instruction-following and content generation, while the Thinking version emphasizes complex reasoning and chain-of-thought capabilities.
1.1 Key Architectural Innovations
The series introduces several cutting-edge technologies that significantly improve training and inference efficiency without compromising performance:
- •
Hybrid Attention Mechanism:
This approach combines Gated DeltaNet and Gated Attention, replacing the standard attention mechanism. This design dramatically improves the efficiency of modeling long-context information, natively supporting up to 262,144 tokens, and can be extended to handle over 1 million tokens using the YaRN extension technique. - •
High-Sparsity Mixture-of-Experts (MoE):
The total parameter count reaches 80 billion, but only 3 billion parameters are activated during each inference step. This extremely low activation ratio (approximately 3.75%) maintains nearly full model capacity while substantially reducing computational overhead. - •
Multi-Token Prediction (MTP):
During pre-training, the model predicts multiple subsequent tokens simultaneously, accelerating both training and inference. - •
Stability Optimizations:
Techniques such as zero-centered weight-decayed LayerNorm enhance training stability and ensure model robustness across diverse tasks.
2. Model Performance Overview
The Qwen3-Next-80B demonstrates strong performance across multiple standard benchmarks. Below are some key comparative results (in percentages or specific scores):
Knowledge Capabilities
| Model | MMLU-Pro | MMLU-Redux | GPQA | SuperGPQA |
|---|---|---|---|---|
| Qwen3-Next-80B-Instruct | 80.6 | 90.9 | 72.9 | 58.8 |
| Qwen3-Next-80B-Thinking | 82.7 | 92.5 | 77.2 | 60.8 |
Reasoning Capabilities
| Model | AIME25 | HMMT25 | LiveBench |
|---|---|---|---|
| Qwen3-Next-80B-Instruct | 69.5 | 54.1 | 75.8 |
| Qwen3-Next-80B-Thinking | 87.8 | 73.9 | 76.6 |
Coding Capabilities
| Model | LiveCodeBench | MultiPL-E | CFEval |
|---|---|---|---|
| Qwen3-Next-80B-Instruct | 56.6 | 87.8 | – |
| Qwen3-Next-80B-Thinking | 68.7 | – | 2071 |
Long-Context Performance
In the RULER benchmark with context lengths of up to 1 million tokens, Qwen3-Next-80B also demonstrates excellent stability, maintaining accuracy above 90% in the 128K–256K token range.
3. How to Use Qwen3-Next-80B
Environment Setup and Model Loading
It is recommended to use the latest version of the Hugging Face transformers library and load the model from ModelScope:
pip install git+https://github.com/huggingface/transformers.git@main
Below is a basic code example showing how to load the model and generate text:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct" # or the Thinking version
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto"
)
prompt = "Please briefly introduce large language models."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(output)
Handling Thinking Content (Thinking Version)
When using the Thinking version, the model’s output may include “thinking process” content within <think>…</think> tags, which requires additional parsing:
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:
index = len(output_ids) - output_ids[::-1].index(151668) # 151668 is the token for </think>
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip()
final_output = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip()
print("Thinking content:", thinking_content)
print("Final response:", final_output)
4. Efficient Deployment and Serving
To fully leverage the model’s capabilities, it is recommended to use dedicated inference frameworks like vLLM or SGLang to deploy an OpenAI-compatible API service.
Deployment with vLLM
pip install git+https://github.com/vllm-project/vllm.git
VLLM_USE_MODELSCOPE=true VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144
Deployment with SGLang
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
SGLANG_USE_MODELSCOPE=true SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 \
python -m sglang.launch_server \
--model-path Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 30000 \
--tp-size 4 \
--context-length 262144 \
--mem-fraction-static 0.8
5. Agent and Tool Calling
The Qwen3 series excels in tool calling and agent behavior. It is recommended to use the Qwen-Agent framework to significantly reduce coding complexity:
from qwen_agent.agents import Assistant
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Thinking',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
}
tools = ['code_interpreter', {'mcpServers': {...}}]
bot = Assistant(llm=llm_cfg, function_list=tools)
messages = [{'role': 'user', 'content': 'Analyze the latest content from https://qwenlm.github.io/blog/'}]
for response in bot.run(messages):
print(response)
6. Ultra-Long Text Processing with YaRN Extension
For processing texts exceeding 262,144 tokens, the YaRN method can be used to extend the context window. Below is an example of enabling YaRN in vLLM:
VLLM_USE_MODELSCOPE=true VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct \
--rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' \
--max-model-len 1010000
7. Optimization Recommendations and Configurations
-
Sampling Parameters:
- •
Instruct version: Temperature=0.7, TopP=0.8, TopK=20 - •
Thinking version: Temperature=0.6, TopP=0.95, TopK=20
- •
-
Output Length:
- •
For general tasks, 16,384 tokens are recommended; - •
For complex tasks like math or coding, 32,768 tokens or more are suggested.
- •
-
Prompt Design:
- •
For math problems: include “Please reason step by step and put your final answer within \boxed{}.” - •
For multiple-choice questions: request output in JSON format, e.g., {"answer": "C"}.
- •
Conclusion
The Qwen3-Next-80B series represents a substantial leap forward in model scale, reasoning efficiency, and application versatility through multiple technological innovations. Whether handling long contexts, performing complex reasoning, or building agent-based applications, this model offers a powerful and efficient foundation for developers. We hope the technical details and practical guidance provided in this article will help readers better understand and apply this advanced model.
Image credits: Unsplash, Pexels (for illustrative purposes only).
References:
If you find this content helpful, you may cite the following sources:
- •
Qwen Team. (2025). Qwen3 Technical Report. arXiv:2505.09388. - •
Yang, A., et al. (2025). Qwen2.5-1M Technical Report. arXiv:2501.15383.
