



Introduction
In the fast-paced world of AI, it feels like every few months we hear about a new “king of large language models.” OpenAI, Anthropic, Google DeepMind, Mistral — these names dominate headlines.
But this time, the spotlight shifts to Qwen3-Max, Alibaba’s trillion-parameter giant.
Naturally, the first questions developers and AI enthusiasts will ask are:
-
How does Qwen3-Max compare to GPT-5? -
What makes it different from Claude Opus 4? -
Is it just a research prototype, or can developers actually use it?
This article breaks it down in plain English, with benchmarks, API examples, and a practical multi-model benchmark script so you can test it yourself.
Qwen3-Max at a Glance
If I had to summarize Qwen3-Max in one sentence:
👉 It’s the largest, most capable model in the Qwen3 family — built for scale, stability, and real-world developer use.
-
Parameters: ~ 1 trillion -
Training data: ~ 36 trillion tokens -
Architecture: Built on a Mixture of Experts (MoE) design with global-batch load balancing
Think of it as a “super team” of specialized experts inside one model. When you ask it a question, the system dispatches the right expert to solve it.
Why does “training stability” matter?
In older mega-models, training often went off the rails — loss spikes, crashes, or needing to roll back to earlier checkpoints. Qwen3-Max solved this with a consistently smooth training curve. In plain terms: imagine driving a car on the highway and hitting zero traffic lights. That’s the Qwen3-Max training story.
Key Innovations
1. Stability
-
MoE architecture: lets different experts handle different inputs. -
Smooth training curve: no rollback, no “emergency patching.” -
Consistent scaling: stability at trillion-parameter scale.
2. Training Efficiency
Qwen3-Max brings several tricks to maximize efficiency:
-
PAI-FlashMoE parallelism → 30% higher Model FLOPs Utilization (MFU) compared to Qwen2.5. -
ChunkFlow → 3× throughput boost for 1M-token long context training. -
Resilience tools: SanityCheck, EasyCheckpoint reduce hardware failure downtime to just 20% of what Qwen2.5-Max suffered.
For developers, this means you can feed Qwen3-Max entire books, contracts, or large codebases, and it still sees the whole picture instead of “forgetting the beginning.”
Qwen3-Max-Instruct

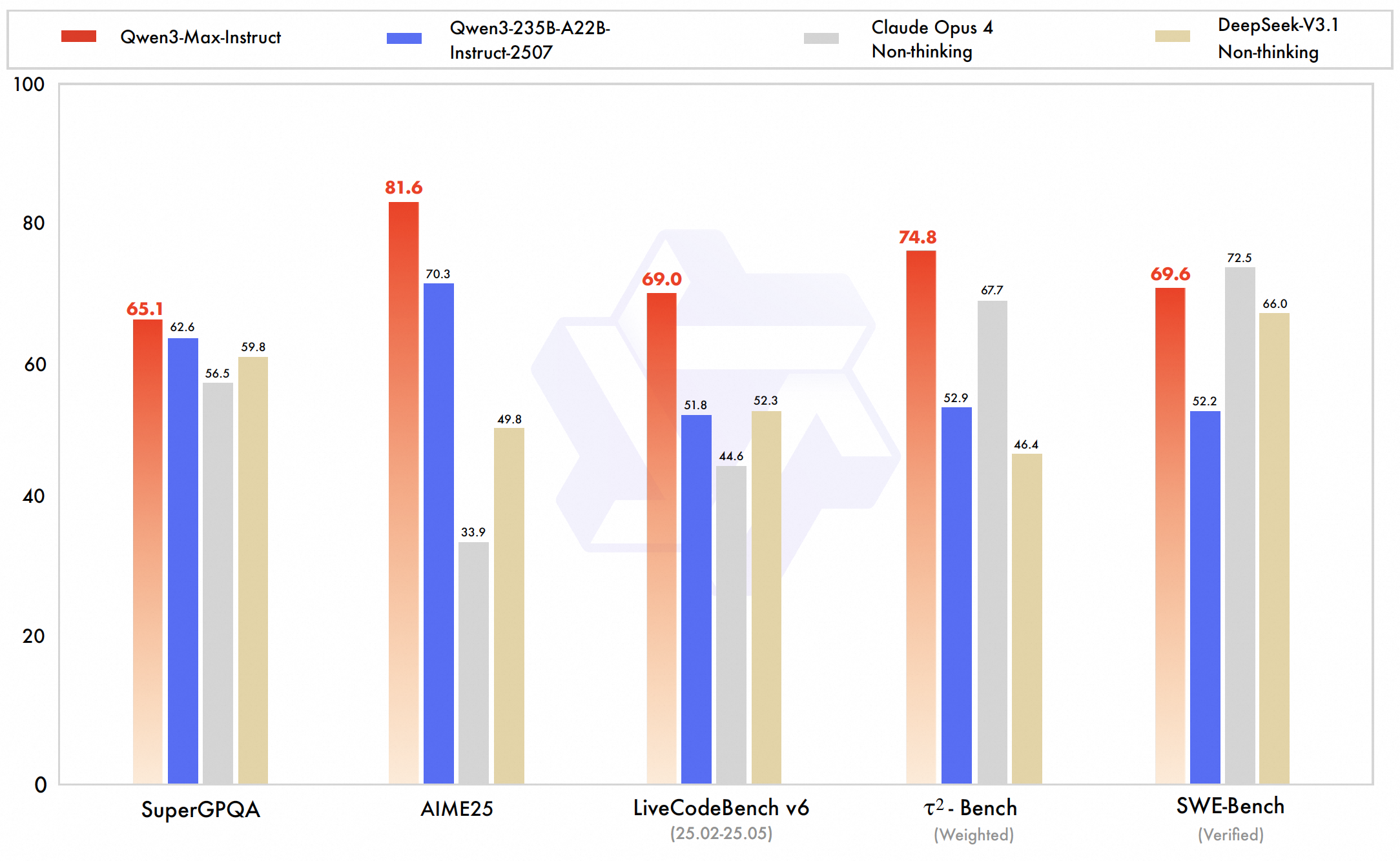
The Instruct version is what most developers will use. Its highlights:
Leaderboard Performance
-
Top 3 on the LMArena global leaderboard -
Surpassed GPT-5-Chat in key benchmarks
Coding Capabilities
-
SWE-Bench Verified: 69.6 score -
That means it can automatically fix bugs, generate tests, and patch real-world repositories.
Agent Abilities
-
Tau2-Bench: 74.8 score, outperforming Claude Opus 4 and DeepSeek V3.1. -
Translation: it’s not just a chatbot, it’s an AI agent that can plan, call tools, and chain tasks.
Qwen3-Max-Thinking

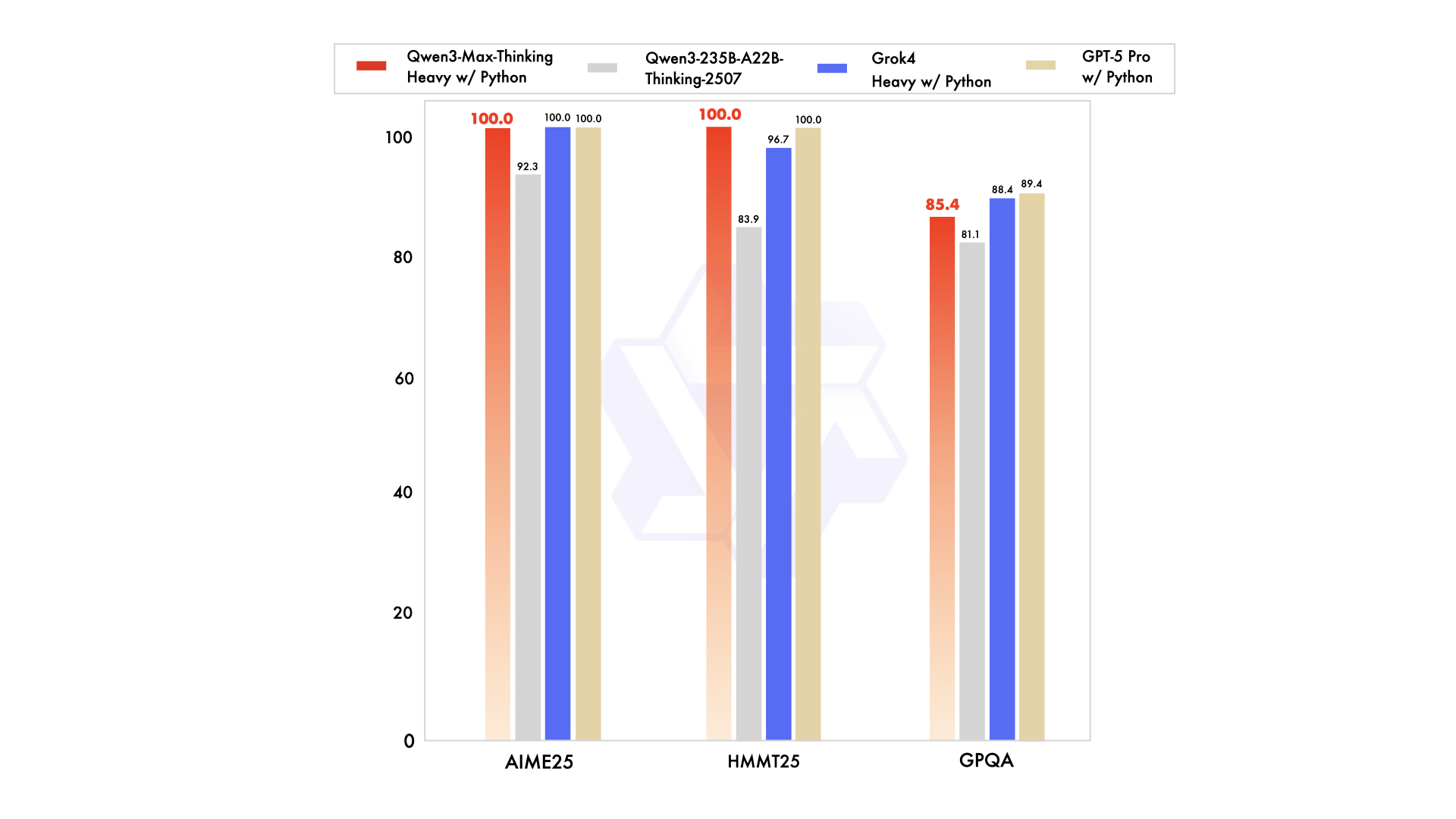
If Instruct is the “workhorse,” then Thinking is the “math Olympiad champion.”
-
Integrated code interpreter to verify reasoning -
Uses parallel compute at inference time -
Perfect 100/100 scores on AIME 25 and HMMT math benchmarks
This variant shows promise as a scientific research assistant, not just a conversational AI.
How to Use Qwen3-Max
Option 1: Try in Browser
Go to Qwen Chat and interact with it directly.
Option 2: API Access
Qwen3-Max is OpenAI API-compatible, so if you’ve used GPT APIs, you already know how to use this one.
Quick How-To
-
Register on Alibaba Cloud -
Activate Model Studio -
Create an API key -
Use with Python (same style as OpenAI SDK)
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
resp = client.chat.completions.create(
model="qwen3-max",
messages=[{"role":"user","content":"Write a quicksort function in Python"}]
)
print(resp.choices[0].message["content"])
Qwen3-Max vs GPT-5 vs Claude Opus 4
Here’s a quick comparison table across three of today’s most discussed frontier models:
| Dimension | Qwen3-Max | GPT-5 (OpenAI) | Claude Opus 4 (Anthropic) |
|---|---|---|---|
| Parameters | ~1T (disclosed) | Not disclosed | Not disclosed |
| Training Data | 36T tokens | Not disclosed | Not disclosed |
| Architecture | MoE + ChunkFlow | Proprietary Transformer | Proprietary Transformer |
| Long Context | 1M tokens | Improved, limit varies | Marathon tasks, limit not disclosed |
| Coding Benchmark | SWE-Bench 69.6 | Strong, no public score | SWE-Bench 72.5 |
| Agent Benchmark | Tau2-Bench 74.8 | Good tool use | Long-running stability |
| Access | Qwen Chat + API | OpenAI API + MS Copilot | Anthropic API |
| Strength | Scale, context, math | Ecosystem & multimodal | Long-term agents |
👉 The key takeaway:
-
Qwen3-Max is the most transparent in size and training. -
GPT-5 wins in ecosystem integration. -
Claude Opus 4 shines in long-duration agent tasks.
How to Benchmark Models Yourself (Step-by-Step)
The best way to decide? Run a PoC with your own tasks.
Step 1: Define Your Use Case
-
Code automation? → Bug fixing & test generation -
Enterprise docs? → Long contract summarization -
Research? → Math and reasoning benchmarks
Step 2: Use Our Python Benchmark Framework
We’ve prepared a multi-model benchmark script (multi_model_benchmark.py) that:
-
Calls multiple APIs (Qwen, GPT, Claude) -
Measures latency, accuracy, cost -
Runs unit tests on generated code -
Exports results to CSV
👉 Example config for Qwen and GPT-5 included.
Step 3: Evaluate with 4 Metrics
| Metric | What it means | How to measure |
|---|---|---|
| Accuracy | Correctness of answers | Auto-check math, code tests |
| pass@k | Probability code works in k tries | Run multiple generations |
| Latency | Response time | Log seconds per request |
| Cost | Token usage × price | Extract usage field from API |
Example Benchmark Prompts
-
Math: Solve 2x+3=11 -
Code: Write quicksort in Python + run tests -
Summary: Summarize a 20-page contract for risks
The script runs these against each model and logs results.
FAQ
Q: Which is better — Qwen3-Max or GPT-5?
A: On some benchmarks, Qwen3-Max-Instruct is ahead (especially coding & agents). GPT-5 still has the strongest ecosystem.
Q: Can I use Qwen3-Max for free?
A: Yes, try it on Qwen Chat. For API, pricing depends on Alibaba Cloud.
Q: Is Claude Opus 4 good for coding?
A: Yes, it leads on SWE-Bench with 72.5, though Qwen is close.
Q: How do I test which model is cheapest?
A: Run the benchmark script, log token usage, multiply by vendor prices.
Conclusion
Qwen3-Max marks a significant step forward in scaling large language models:
-
1 trillion parameters and 36T tokens make it a serious player. -
Stable training and efficient parallelism solved problems that plagued earlier giants. -
Instruct excels in real-world coding & agent tasks. -
Thinking variant sets new records in reasoning. -
API compatibility lowers the barrier for developers.
If you’re choosing between Qwen3-Max, GPT-5, and Claude Opus 4:
-
Pick Qwen3-Max for long context + reasoning. -
Pick GPT-5 for ecosystem + multimodal support. -
Pick Claude Opus 4 for long-duration agent workflows.
👉 And the golden rule: Don’t just trust benchmarks. Run your own tests.
With the provided framework, you can now measure accuracy, latency, and cost yourself — and choose the AI that fits your business best.

