


Introduction: When LLM Scale Meets Network Bottlenecks
Imagine trying to run a large language model with trillions of parameters, such as DeepSeek V3 (671 billion parameters) or Kimi K2 (1 trillion parameters). These models can no longer be fully deployed on a single 8-GPU server and must be distributed across multiple computing nodes. This reveals a surprising reality: the main constraint on performance is no longer computational power (FLOPs), but rather the efficiency of network communication between GPUs.
This is the core challenge facing modern large language model systems. As model sizes explode, traditional collective communication libraries (like NCCL) struggle to handle dynamic, sparse communication patterns. Complicating matters further, different cloud providers employ different RDMA network hardware—NVIDIA ConnectX-7 uses ordered transmission, while AWS Elastic Fabric Adapter (EFA) employs an unordered transmission protocol. This hardware fragmentation means existing communication libraries either suffer severe performance degradation or simply don’t work in cross-provider environments.
Perplexity AI’s research team states clearly in their technical paper: “Before this work, there was no viable cross-provider solution for LLM inference.” This statement reveals the harsh reality facing the industry: either get locked into a single hardware vendor or accept significant performance penalties.
RDMA Networking: The Invisible Backbone of LLM Systems
What is RDMA and Why is it Crucial for LLMs?
Remote Direct Memory Access (RDMA) is a core technology in modern high-performance computing. It allows network adapters to directly access remote host memory without CPU involvement, enabling high-throughput, low-latency data transfer. In current deployments, RDMA network interface cards (NICs) can provide 400 Gbps bandwidth with microsecond-level latency.
For large language model systems, particularly Mixture of Experts (MoE) and disaggregated inference architectures, RDMA’s value is even more pronounced:
-
Mixture of Experts Models: Each input token only activates a few experts, creating sparse but precisely routed communication patterns -
Disaggregated Inference: Prefill and decoding stages run on separate devices, requiring efficient key-value cache (KvCache) transfer -
Asynchronous Reinforcement Learning: Training and inference nodes are separated, requiring rapid updates of trillion-level parameters
The Challenge of Network Fragmentation in Cloud Environments
Major cloud providers currently deploy different RDMA implementations:
-
NVIDIA ConnectX Series: Uses traditional Reliable Connection (RC) transport, guaranteeing ordered delivery -
AWS Elastic Fabric Adapter (EFA): Implements proprietary Scalable Reliable Datagram (SRD) protocol, providing reliable but unordered delivery -
Alibaba Cloud eRDMA and Google Falcon: Custom solutions from other cloud providers
This diversity creates serious compatibility issues. High-performance libraries like DeepEP rely on ConnectX-specific GPU-initiated RDMA (IBGDA), which doesn’t work on EFA. NVSHMEM, while API-compatible on EFA, suffers severe performance degradation on critical workloads like MoE routing. Newer libraries like Mooncake and NIXL either lack EFA support or remain in preliminary stages.
TransferEngine: A Breakthrough in Portable RDMA Communication
Core Design Insight: Establishing Order in Disorder
Perplexity AI’s TransferEngine is built on a key insight: while different RDMA hardware varies in message ordering guarantees, they all provide reliability guarantees. ConnectX’s RC transport can be configured to ignore ordering, while EFA’s SRD is inherently unordered. By relying only on reliability without assuming any ordering, TransferEngine can build a unified abstraction layer across heterogeneous hardware.
This design decision makes TransferEngine the first truly cross-provider RDMA communication library, delivering near-hardware peak performance on both NVIDIA ConnectX-7 and AWS EFA.
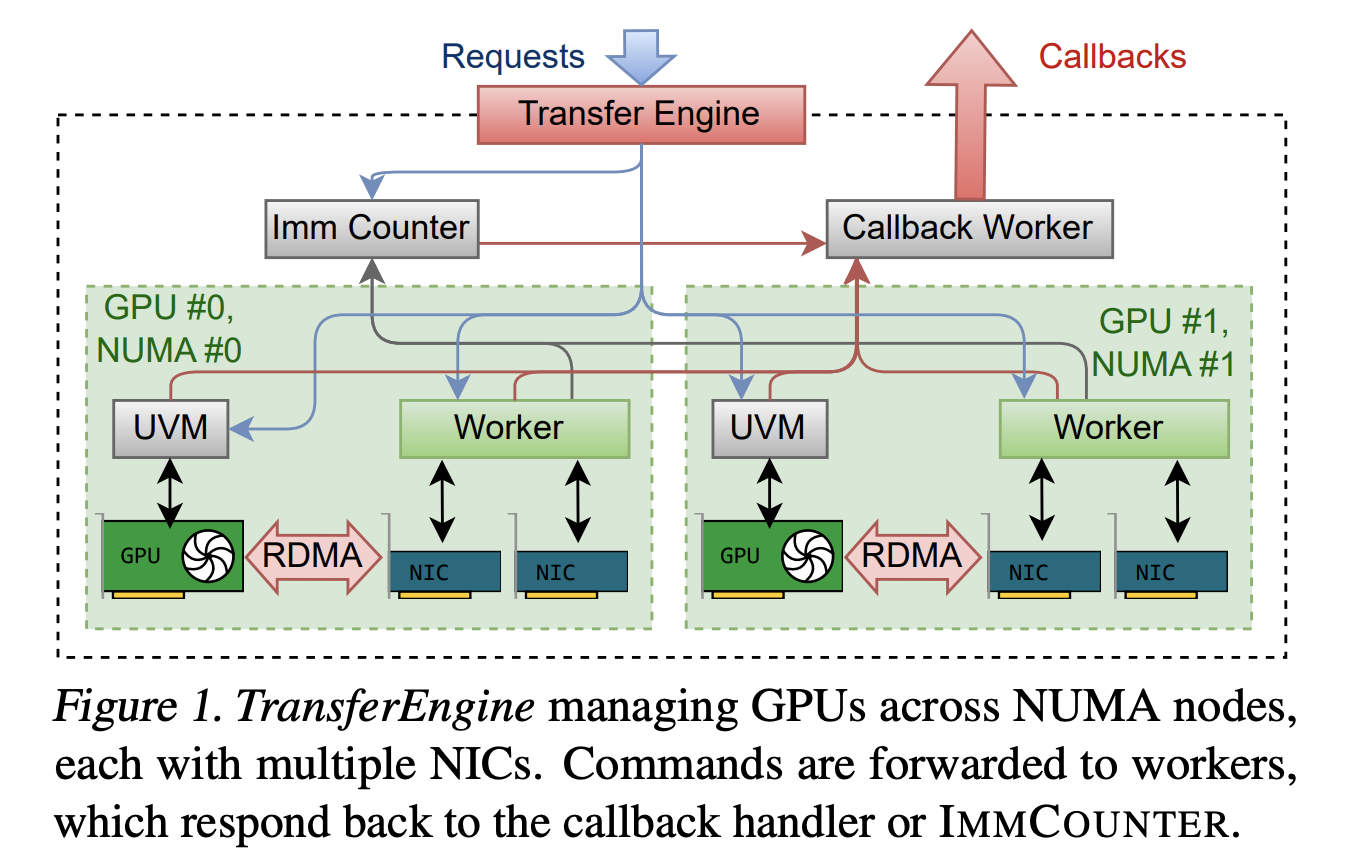
Architecture Overview: Hardware Diversity Under Unified Abstraction


TransferEngine’s architecture is carefully designed to handle hardware diversity. Its core components include:
-
DomainGroup: One per GPU, coordinating all associated RDMA NICs -
Domain: Manages a single NIC, handling queue pair management, work submission, and completion polling -
Worker Threads: One worker thread per DomainGroup, pinned to corresponding NUMA node CPU cores
This architecture transparently handles differences in NIC counts across hardware platforms. A single ConnectX-7 NIC provides 400 Gbps bandwidth, while on AWS p5 instances, four 100 Gbps EFA NICs (or two 200 Gbps EFA NICs on p5en instances) must be aggregated to achieve equivalent bandwidth.
Core API Design: Simple Yet Powerful
TransferEngine exposes its functionality through a carefully designed Rust API, with main operations including:
-
Memory Region Management: reg_mrregisters memory regions, returning serializable descriptors -
Two-sided Send/Receive: submit_sendandsubmit_recvsimplement RPC-style communication -
One-sided Writes: submit_single_writeandsubmit_paged_writesfor bulk data transfer -
Scatter Operations: submit_scattersends data slices to a group of peers -
Barrier Synchronization: submit_barrierfor peer notification
A key characteristic of these APIs is that they provide no ordering guarantees across operations, reflecting the reality of underlying hardware.
ImmCounter: Completion Notification in Unordered Environments
Traditional RDMA implementations heavily rely on message ordering for completion notification, which isn’t feasible in unordered transports. TransferEngine introduces the innovative ImmCounter primitive to address this challenge.
ImmCounter tracks per-immediate-value counters that are incremented by events retrieved from the underlying devices’ completion queues. Regardless of message arrival order, notifications trigger when counts for specific immediate values reach expected thresholds. This approach ensures reliable completion detection in unordered network environments.
Hardware-Specific Optimizations: Maximizing Performance
TransferEngine implements specialized optimizations for different hardware platforms:
AWS EFA Support:
-
Implemented using libfabric, with one fabric domain per NIC -
Enforces valid descriptors for all transfers, even for immediate-only zero-sized writes -
Employs work request (WR) templating, pre-populating and retaining common fields in libfabric descriptors
NVIDIA ConnectX-7 Support:
-
Implemented through libibverbs, using UD queue pairs per peer for RC handshake exchange -
Creates 2 RC queue pairs per peer: one for two-sided operations, another for one-sided operations -
Enables WR chaining by linking up to 4 work requests, reducing doorbell ringing count -
Enables IBV_ACCESS_RELAXED_ORDERING to permit out-of-order PCIe transactions between NIC and GPU memory
Production System Case Studies
Case Study 1: KvCache Transfer for Disaggregated Inference

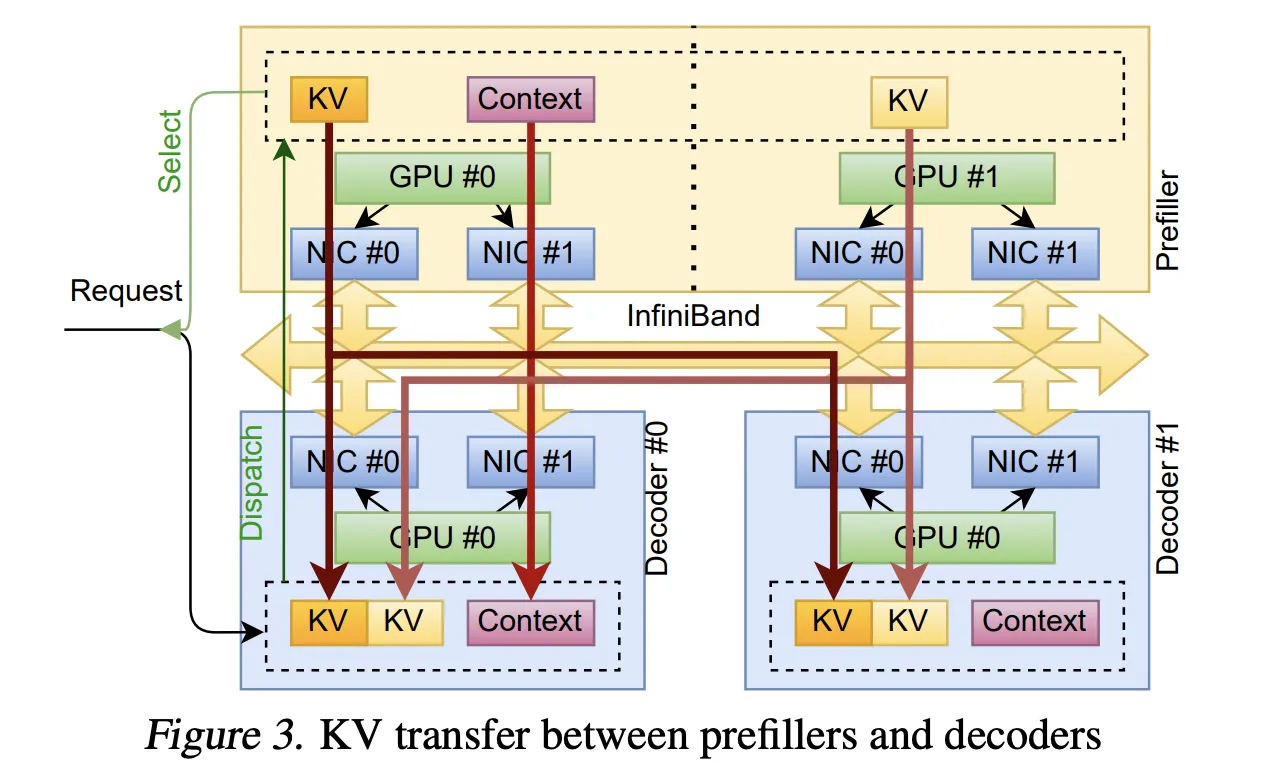
Disaggregated inference architectures separate prefill and decoding stages to different devices, optimizing resource utilization. In this mode, prefill nodes process input tokens and generate key-value caches (KvCache), which are then transferred to decoder nodes for autoregressive token generation.
TransferEngine enables efficient KvCache transfer through:
-
Dynamic Scheduling: A global scheduler selects prefill and decoder nodes, with decoder nodes pre-allocating KvCache pages and dispatching requests to designated prefillers using
submit_send -
Layer-by-Layer Streaming: During chunked prefill, the model increments UVM watcher values after each layer’s attention output projection. When TransferEngine detects changes, it initiates layer transfers via
submit_paged_writes -
Completion Notification: Decoder nodes know the expected number of transfers in advance, using
expect_imm_countto receive notifications when transfers complete and begin decoding -
Error Handling: Transport layer failures are detected through heartbeat messages, with fine-grained cancellation and acknowledgment mechanisms
This approach avoids the fixed membership and synchronized initialization overhead of collective communication, enabling true elastic scaling.
Case Study 2: Reinforcement Learning Weight Updates

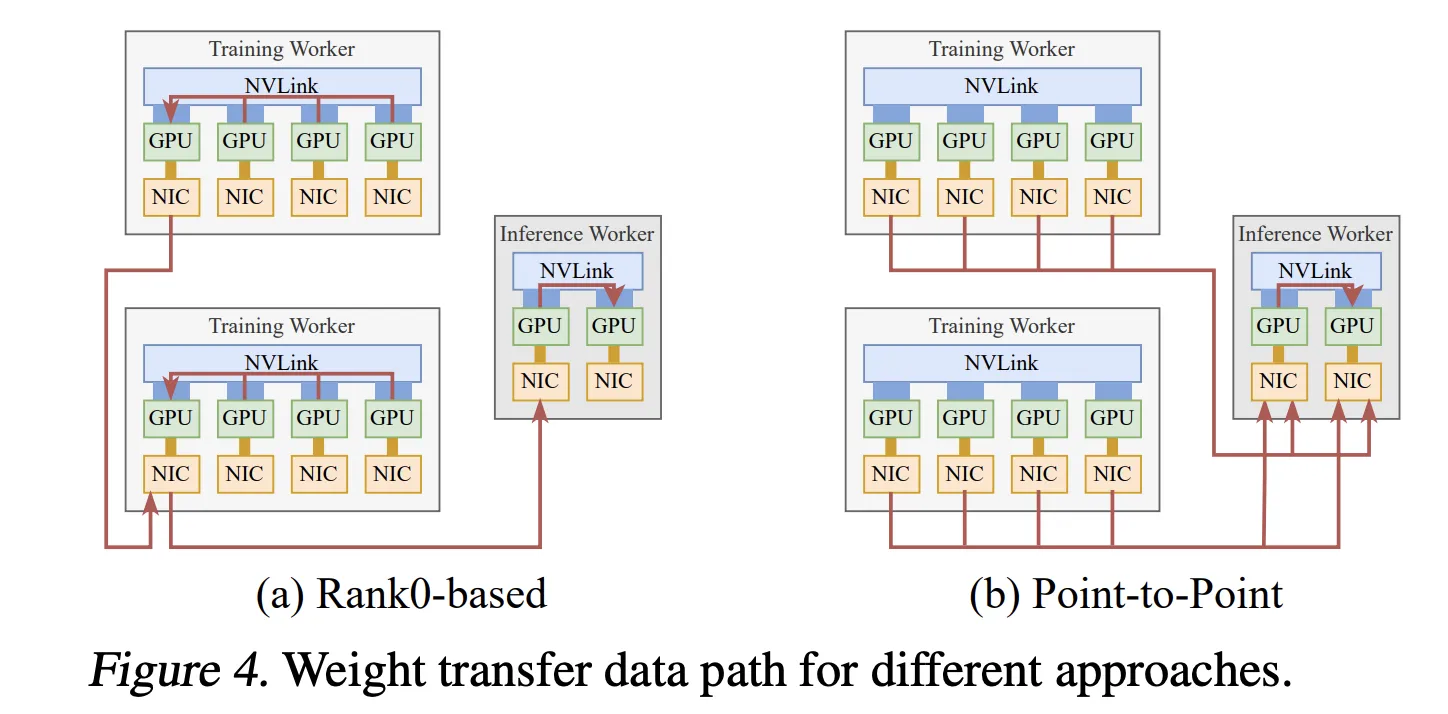
In asynchronous reinforcement learning fine-tuning, training and inference run on separate GPUs. Traditional designs use collective communication, gathering all updated parameters to training subgroup Rank0, then broadcasting to each inference subgroup’s Rank0, making the training Rank0’s NIC the bottleneck.
TransferEngine’s point-to-point approach revolutionizes this paradigm:
-
Direct Weight Transfer: Each training GPU uses one-sided RDMA writes to directly send its parameter shard to corresponding inference GPUs, utilizing full cluster bandwidth across all NICs
-
Pipelined Execution: Each tensor transfer task splits into four overlapping stages:
-
Stage 1: Host-to-device memory copy if FSDP offloads weights to CPU -
Stage 2: Parameter preparation, including full weight reconstruction with full_tensor(), projection fusion application, and quantization if needed -
Stage 3: RDMA transfer, zero-copy write from local GPU memory to remote inference GPU memory -
Stage 4: Global barrier synchronization across mesh groups using GLOO via Ethernet after all full_tensor()calls complete
-
-
Memory Management: Configurable watermarks control temporary GPU memory usage to avoid out-of-memory errors
In production, this solution delivers breakthrough performance: for models like Kimi-K2 (1T parameters), DeepSeek V3 (671B), and Qwen3 (235B), parameter updates from 256 training GPUs (bf16) to 128 inference GPUs (fp8) take approximately 1.3 seconds—over 100× faster than existing RL frameworks.
Case Study 3: Mixture of Experts Routing


Token routing in mixture of experts models requires efficient all-to-all communication patterns. TransferEngine’s MoE kernels deliver state-of-the-art performance while maintaining portability:
Architecture Characteristics:
-
Uses NVLink for intra-node communication, RDMA for inter-node communication -
Splits dispatch and combine into separate send and receive phases, enabling micro-batching and communication-computation overlap -
Host proxy threads poll GPU state via GDRCopy and invoke TransferEngine when source buffers are ready
Dispatch Optimizations:
-
Route Exchange: Peers first exchange routing information (token counts per expert) to determine unique ranges in contiguous receive buffers -
Private Buffers: Speculatively dispatch small numbers of tokens to private per-source buffers, hiding device-to-host and network latency -
Bulk Transfers: Once routes are determined, remaining tokens are scattered to peers, placed contiguously into shared receiver buffers
Memory Efficiency:
Receiver buffers are sized to account for all tokens sent to the current rank. Assuming N ranks hosting E experts, each dispatching T tokens to R experts, the upper bound is N·T·max(R, E/N). Senders pack writes into such contiguous buffers instead of relying on larger per-rank receiver buffers.
Performance Evaluation
Point-to-Point Communication Performance


TransferEngine delivers excellent point-to-point communication performance, achieving near-hardware throughput limits on both NVIDIA ConnectX-7 and AWS EFA:
| Operation Type | Message Size | EFA Performance | ConnectX-7 Performance |
|---|---|---|---|
| Single Write | 64 KiB | 16 Gbps | 44 Gbps |
| Single Write | 256 KiB | 54 Gbps | 116 Gbps |
| Single Write | 1 MiB | 145 Gbps | 245 Gbps |
| Single Write | 32 MiB | 336 Gbps | 378 Gbps |
| Paged Write | 1 KiB | 17 Gbps (2.11M op/s) | 91 Gbps (11.10M op/s) |
| Paged Write | 8 KiB | 138 Gbps (2.10M op/s) | 320 Gbps (4.89M op/s) |
| Paged Write | 16 KiB | 274 Gbps (2.08M op/s) | 367 Gbps (2.80M op/s) |
| Paged Write | 64 KiB | 364 Gbps (0.69M op/s) | 370 Gbps (0.71M op/s) |
These results demonstrate that TransferEngine can deliver high performance across both major hardware platforms while maintaining abstraction layer simplicity.
MoE Dispatch and Combine Performance
Decode Latency (128 tokens):
| Expert Count | pplx-EFA Dispatch | pplx-CX7 Dispatch | DeepEP-CX7 Dispatch | pplx-EFA Combine | pplx-CX7 Combine | DeepEP-CX7 Combine |
|---|---|---|---|---|---|---|
| EP64 | 266.7 μs | 187.5 μs | 177.9 μs | 391.2 μs | 309.1 μs | 325.0 μs |
| EP32 | 229.1 μs | 153.9 μs | 159.1 μs | 335.0 μs | 266.3 μs | 285.0 μs |
| EP16 | 214.8 μs | 110.2 μs | 123.9 μs | 241.5 μs | 185.5 μs | 203.0 μs |
| EP8 | 49.7 μs | 50.5 μs | 42.6 μs | 64.2 μs | 65.3 μs | 72.0 μs |
Prefill Latency (4096 tokens):
| Expert Count | pplx-EFA Dispatch | pplx-CX7 Dispatch | DeepEP-CX7 Dispatch | pplx-EFA Combine | pplx-CX7 Combine | DeepEP-CX7 Combine |
|---|---|---|---|---|---|---|
| EP64 | 5334.3 μs | 4665.2 μs | 5071.6 μs | 9779.3 μs | 8771.1 μs | 5922.7 μs |
| EP32 | 4619.0 μs | 4011.8 μs | 3680.2 μs | 8271.5 μs | 7526.8 μs | 3565.4 μs |
| EP16 | 3196.7 μs | 2734.8 μs | 2481.9 μs | 5379.1 μs | 1062.2 μs | 1863.9 μs |
| EP8 | 1052.4 μs | 5071.1 μs | 1810.3 μs | 1396.7 μs | 1405.1 μs | 962.9 μs |
These results show that on ConnectX-7, TransferEngine’s MoE kernels deliver performance comparable to or better than specially optimized DeepEP, while providing the first viable MoE implementation on EFA.
Impact of Private Buffer Size on Performance

Private buffers are designed to hide the latency of routing information exchange. Evaluation shows performance degradation as private buffer size decreases:
-
In intra-node cases, at least ~32 tokens are needed to hide route exchange latency across both NIC types -
In inter-node cases, ConnectX-7 NICs allow as few as 24 tokens, while EFA NICs show performance drop-offs below 32 tokens already
This demonstrates the importance of latency reduction strategies in achieving high-performance MoE routing.
Practical Implementation Guide
System Requirements
To use TransferEngine and pplx garden, your system must meet these requirements:
-
Linux Kernel 5.12 or higher (recommended, for DMA-BUF support) -
CUDA 12.8 or higher -
libfabric, libibverbs, and GDRCopy libraries -
SYS_PTRACEandSYS_ADMINLinux capabilities (forpidfd_getfd) -
RDMA network with GPUDirect RDMA support, with at least one dedicated RDMA NIC per GPU
Docker Development Environment
For development convenience, the project provides a Docker image:
# Build image
docker build -t pplx-garden-dev - < docker/dev.Dockerfile
# Run container
./scripts/run-docker.sh
Building and Installation
Inside the container, build and install the Python package with these steps:
cd /app
export TORCH_CMAKE_PREFIX_PATH=$(python3 -c "import torch; print(torch.utils.cmake_prefix_path)")
python3 -m build --wheel
python3 -m pip install /app/dist/*.whl
Running Benchmarks
Network Debugging:
# Server side
/app/target/release/fabric-debug 0,1,2,3,4,5,6,7 2
# Client side
/app/target/release/fabric-debug 0,1,2,3,4,5,6,7 2 <server-address>
All-to-All Benchmark:
# Set environment variables
NUM_NODES=...
NODE_RANK=... # [0, NUM_NODES)
MASTER_IP=...
# Run on all nodes
cd /app
python3 -m benchmarks.bench_all_to_all \
--world-size $((NUM_NODES * 8)) --nets-per-gpu 2 --init-method=tcp://$MASTER_IP:29500 \
--node-rank=$NODE_RANK --nvlink=8
Note: Remove the --nvlink flag to use RDMA only; set --nets-per-gpu according to your VM instance type.
Comparison with Alternative Solutions
| Key Aspect | TransferEngine (pplx garden) | DeepEP | NVSHMEM (Generic MoE Use) | Mooncake |
|---|---|---|---|---|
| Primary Role | Portable RDMA point-to-point for LLM systems | MoE all-to-all dispatch and combine | General GPU shared memory and collectives | Distributed KV cache for LLM inference |
| Hardware Focus | NVIDIA ConnectX-7 and AWS EFA, multiple NICs per GPU | NVIDIA ConnectX with GPU-initiated RDMA IBGDA | NVIDIA GPUs on RDMA fabrics including EFA | RDMA NICs in KV-centric serving stacks |
| EFA Status | Full support, reported 400 Gbps peak | No support, requires IBGDA on ConnectX | API works but MoE use shows severe degradation on EFA | Paper reports no EFA support in its RDMA engine |
| Portability for LLM Systems | Cross-vendor, single API across ConnectX-7 and EFA | Vendor-specific and ConnectX-focused | NVIDIA-centric, not viable for EFA MoE routing | Focused on KV sharing, no cross-provider support |
Frequently Asked Questions
How does TransferEngine differ from traditional collective communication libraries like NCCL?
Collective communication libraries excel at structured data exchange patterns like tensor or data parallelism, but impose constraints unsuitable for emerging workloads: fixed membership prevents dynamic scaling, synchronized initialization adds overhead, and uniform buffer sizes force dense communication even for sparse patterns. TransferEngine’s point-to-point approach provides flexibility while maintaining high performance through RDMA primitives.
Does TransferEngine support GPU-direct initiated RDMA?
Currently, GPUDirect Async (IBGDA) is only supported on ConnectX NICs. TransferEngine transparently handles this situation, using GPU-direct initiation on ConnectX (when available) and falling back to host proxy methods on EFA. This design ensures portability across hardware while optimizing performance on different platforms.
What are the requirements for deploying TransferEngine in mixed hardware environments?
All peers must use the same number of NICs per GPU. This restriction allows TransferEngine to have full knowledge of NICs between source and destination domains, enabling request sharding or load balancing. For EFA, this is crucial for achieving full 400Gbps bandwidth using multiple adapters.
How does TransferEngine handle network reliability and error recovery?
TransferEngine relies on the underlying RDMA hardware’s reliability guarantees. For application-level error handling, it provides heartbeat mechanisms to detect transport layer failures and fine-grained cancellation capabilities. In the KvCache transfer case, cancellations triggered by decoders must be explicitly acknowledged by prefill nodes, ensuring KV pages aren’t reused while remote writes might overwrite them.
What is TransferEngine’s memory footprint?
For MoE routing, receiver buffer sizes are bounded by N·T·max(R, E/N), where N is the number of ranks hosting E experts, each dispatching T tokens to R experts. By reusing dispatch receive buffers for combine, and using private buffers for initial token transfers, TransferEngine minimizes memory overhead while maintaining low latency.
Conclusion
The release of Perplexity AI’s TransferEngine and pplx garden represents a significant advancement in LLM infrastructure. By providing portable point-to-point communication abstractions that work across heterogeneous RDMA hardware, it enables teams to run trillion-parameter models on existing mixed GPU clusters without expensive hardware upgrades or deep vendor lock-in.
Three production systems—disaggregated inference with dynamic scaling, reinforcement learning weight updates in 1.3 seconds, and portable MoE routing across ConnectX-7 and EFA—demonstrate the approach’s effectiveness. By avoiding vendor lock-in while maintaining performance, TransferEngine lays a solid foundation for cloud-native LLM deployment.
As model sizes continue to outgrow single-node capabilities, solutions like TransferEngine that provide efficient, portable communication will become increasingly critical. Its open-source availability (MIT license) ensures this technological advancement can be widely adopted, driving the entire industry forward.
References and Resources
-
Research Paper: RDMA Point-to-Point Communication for LLM Systems -
GitHub Repository: pplx-garden -
Technical Report: Deepseek-v3 Technical Report -
Kimi K2: Open Agentic Intelligence
Citation Information:
@misc{pplx-rdma-p2p,
title={RDMA Point-to-Point Communication for LLM Systems},
author={Nandor Licker and Kevin Hu and Vladimir Zaytsev and Lequn Chen},
year={2025},
eprint={2510.27656},
archivePrefix={arXiv},
primaryClass={cs.DC},
url={https://arxiv.org/abs/2510.27656},
}

