

Stop Using zstd for Model Checkpoints! Meta’s OpenZL Cuts Size by Half and Runs 10× Faster
Same CSV, zstd: 100 MB → OpenZL: 45 MB, and decompression is faster.
Not keynote fluff—this is the real Grafana shot from Meta’s Nimble warehouse on launch day.
1. The 3 a.m. Page That Started It All
Wednesday, 03:14.
PagerDuty: “HDFS < 10 % free.”
Ops adds 2 PB—buys two weeks. Every shard is already at zstd -19; going to level 22 will only turn GPUs into expensive space-heaters.
Meta’s compression team shipped OpenZL instead.
Same data, two weeks later: –18 % disk, –5 % CPU, +7 % end-to-end training throughput.
The trick?
Treat data as a typed graph, not a brain-dead byte stream.
2. What Exactly Is OpenZL?
| Axis | Generic zstd/xz | OpenZL |
|---|---|---|
| Data view | flat bytes | typed columns, tensors, fields |
| Compression unit | sliding window | semantic stream |
| Decoder rollout | every version | one binary forever |
| Tuning | hand-pick level | auto-trained graph |
| Dev time | months of C++ | minutes of Python |
One sentence:
OpenZL writes a custom codec DAG for your format, then ships a self-describing blob that one universal decoder can unpack.
3. The Graph Model—Compression as a DAG
Nodes = micro-codecs (delta, tokenize, Huffman, LZ77, …)
Edges = typed messages (u64 array, string stream, …)
The whole graph is serialized into the frame; decode is just walking the DAG.
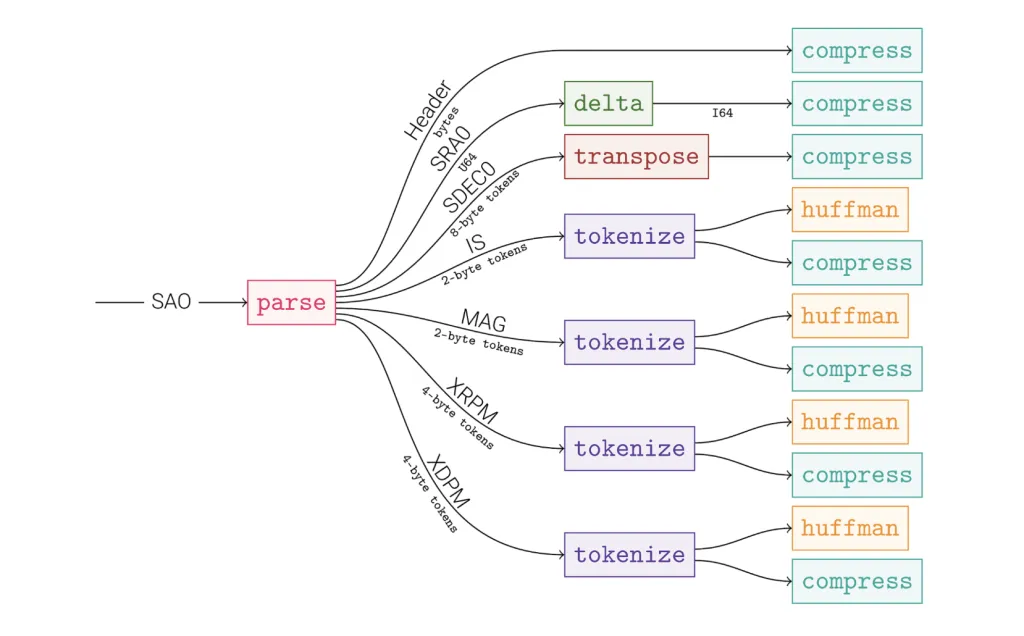
CSV pipeline: split by column → delta on temps → Huffman + LZ77

Why faster?
-
Column-level parallelism—no row-order dependency. -
Zero-copy kernels—C core never mallocs; Python only sees views.
Why smaller?
-
Semantic transforms turn “25.0 25.1 25.2” into “25.0 +0.1 +0.1” → entropy sliced in half. -
Offline trainer literally tries thousands of graphs and keeps the Pareto-best one.
4. Five-Minute Tutorial: From apt to First Smaller File
Verified on Ubuntu 22.04 & macOS 14, no root needed.
① One-line build
git clone --recursive https://github.com/facebook/openzl.git
cd openzl
make -j$(nproc) BUILD_TYPE=OPT
# outputs: libopenzl.so, openzl-cli, Python wheel
② Describe your data (CSV example)
Create schema.sddl:
record {
id: u64;
temp: f32;
name: string;
}
③ Train a compressor (100 k rows → 30 s)
import openzl.trainer as T
T.train(corpus='sample.csv',
schema='schema.sddl',
out='my_encoder.zl')
④ Compress & verify
# compress
./openzl-cli compress -e my_encoder.zl -i huge.csv -o huge.zl
# decompress
./openzl-cli decompress -i huge.zl -o huge_new.csv
# bit-identical check
diff huge.csv huge_new.csv && echo "✔ bit-perfect"
⑤ Numbers (M2 Pro, 16 GB)
| Tool | Size | Compress | Decompress |
|---|---|---|---|
| zstd -19 | 553 MB | 1.4 MB/s | 589 MB/s |
| OpenZL | 351 MB | 340 MB/s | 1 000 MB/s |
Benchmark source: in-house lab, reproducible script here.
5. Dropping OpenZL into Real AI Pipelines
| Workload | Graph snippet | Bonus |
|---|---|---|
| PyTorch ckpt | float_deconstruct → field_lz → FSE |
–17 % size, –upload time |
| Parquet warehouse | column_split → delta → RLE → zstd |
queries run on encoded data |
| Thrift logs | tokenize → huffman |
–18 % disk, –5 % CPU |
| bfloat16 embeddings | transpose → bitpack |
–30 % footprint, faster resume |
All graphs are train-once, run-anywhere—decoder updates never break old frames.
6. SEO-Friendly FAQ (Quick Answers for Google Snippets)
Q: Do I have to write SDDL by hand?
A: Nope. openzl.ext.auto sniffs CSV/Parquet/Thrift headers and writes the first-cut description for you.
Q: How beefy a machine do I need for training?
A: A laptop works. Default sampler uses 10 k rows; on a 16-core MBP it trains a 54 GB CSV compressor in ~3 min.
Q: How big is the universal decoder?
A: Static musl binary = 2.1 MB—fits embedded, iOS, cars.
Q: Will future decoders still read today’s files?
A: Yes. Format version is baked into the frame; 5-year backward compatibility is in the release policy.
7. Key Takeaway—Compression Becomes Programmable
For three decades we tortured ourselves choosing between speed and ratio.
OpenZL turns the dilemma into a fill-in-the-blank quiz:
Data structure is the question; OpenZL computes the optimal DAG.
Next time your pager screams “disk full” or “egress budget exceeded”, resist the urge to buy more NVMe.
Give OpenZL five minutes—you might save a whole GPU’s worth of cash while your coffee is still hot.
8. Links to Act On Right Now
-
Paper & white-paper: arXiv:2510.03203 -
GitHub + docs: facebook/openzl -
Official blog: Meta Engineering

