How MIT Taught AI to Plan with 94% Accuracy: A Deep Dive into PDDL-Instruct
Imagine asking a powerful AI like ChatGPT to devise a plan for building a piece of furniture. It might produce a list of steps that sound perfectly logical: “Attach leg A to panel B using screw C.” It looks right. It sounds right. But if you try to follow it, you might find that step 3 requires a tool you don’t have, or step 7 tells you to attach a part you already sealed away inside the structure in step 2. The plan is plausible-sounding nonsense.
This is a well-known failure mode of Large Language Models (LLMs). They are masters of syntax and pattern matching but often struggle with deep, multi-step logical reasoning. This becomes a critical issue when we want to use AI for real-world tasks like robotics, autonomous vehicle navigation, or complex workflow automation—where a logical flaw isn’t an annoyance; it’s a potential disaster.
A research team from MIT CSAIL has tackled this problem head-on. In their groundbreaking paper, “Teaching LLMs to Plan: Logical Chain-of-Thought Instruction Tuning for Symbolic Planning“, they introduce PDDL-Instruct, a novel instruction-tuning framework that supercharges the symbolic planning capabilities of LLMs. The results are staggering: their tuned Llama-3-8B model achieved a 94% plan validity rate on classic planning problems and became 64 times better at solving obfuscated, tricky puzzles that utterly baffle standard models.
Let’s peel back the layers and understand how they did it and why it matters.
The Root of the Problem: Why Can’t LLMs Plan Properly?
At their core, LLMs are incredibly sophisticated statistical predictors. Given a sequence of words (a prompt), they predict the most probable next word based on the vast amount of text they’ve been trained on. This is why they are so fluent and creative. However, planning isn’t about probability; it’s about rigorous, deterministic logic.
An LLM might have seen thousands of “pick up the block” steps in its training data, so it knows that phrase often follows “the hand is empty.” It’s mimicking a pattern, not reasoning about the preconditions (the hand must actually be empty in the current state of the world) and the effects (after picking it up, the block is no longer on the table, and the hand is no longer empty).
This is the chasm between generating text and generating a valid plan. PDDL-Instruct is designed to build a bridge across this chasm.
PDDL: The Language of Automated Planning (A Quick Primer)
To understand the solution, we need to understand the language of the problem: the Planning Domain Definition Language (PDDL). Developed in 1998, PDDL is the standard language used by AI researchers to formally define planning problems. It’s how we give an AI a “world model.”
A PDDL problem consists of two main parts:
-
Domain: Defines the “rules of the world.”
-
Predicates: The properties and relationships that can be true or false (e.g., (on blockA blockB),(handempty)). -
Actions: The things an agent can do. Each action has: -
Preconditions: What must be true for the action to be executed. (e.g., to pick-upa block, it must be(clear),(ontable), and the hand must be(handempty)). -
Effects: How the action changes the world. This includes Add effects (new facts that become true) and Delete effects (facts that are no longer true).
-
-
-
Problem: Defines a specific scenario within a domain.
-
Objects: The things in the world (e.g., blockA, blockB, blockC). -
Initial State: The starting set of true predicates. -
Goal: The set of conditions that must be true at the end.
-
The planner’s job is to find a sequence of actions that transforms the initial state into a state where the goal conditions are all true.
A Simple Blocksworld Example:
| Action: | (pick-up blockA) |
|---|---|
| Preconditions: | (clear blockA), (ontable blockA), (handempty) |
| Effects (Add): | (holding blockA) |
| Effects (Delete): | (ontable blockA), (clear blockA), (handempty) |
PDDL-Instruct teaches LLMs to reason explicitly in these terms.
Deconstructing PDDL-Instruct: MIT’s Two-Stage Teaching Method
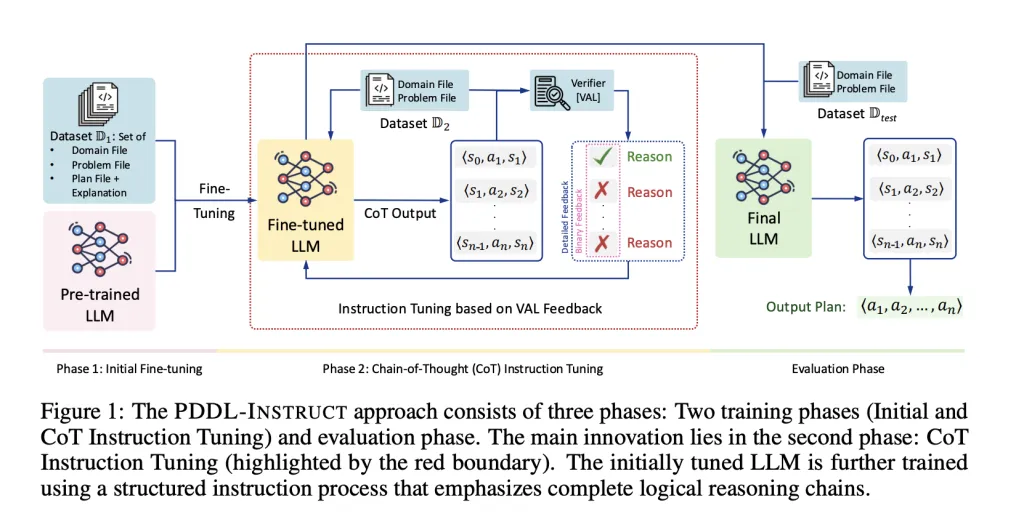
The PDDL-Instruct framework is elegantly structured into three phases, as shown in the diagram above. The magic happens in the second phase.
Phase 1: Initial Instruction Tuning – Laying the Foundation
You can’t run before you can walk. In this first phase, the researchers take a pre-trained LLM and fine-tune it on a dataset (D1) of PDDL problems and plans. The key here is that they don’t just show correct plans; they also show deliberately incorrect plans with detailed explanations of why they fail.
-
For a correct plan, the model learns to generate explanations like: “Action pick-up Bis valid because preconditions(clear B),(ontable B), and(handempty)are all satisfied in the current state.” -
For an incorrect plan, it learns to identify errors: “Action stack A Bis invalid because precondition(holding A)is not satisfied; the hand is empty.”
This phase builds the model’s foundational knowledge of PDDL syntax and basic action semantics, teaching it to distinguish valid from invalid steps.
Phase 2: CoT Instruction Tuning – The Masterclass
This is the core innovation. The model from Phase 1 is now further trained using a more demanding process that emphasizes Logical Chain-of-Thought (CoT) Reasoning.
-
CoT Generation: For a given problem, the model is prompted to generate a plan not just as a action list, but as a detailed, step-by-step reasoning chain:
⟨s₀, a₁, s₁⟩, ⟨s₁, a₂, s₂⟩, ..., ⟨sₙ₋₁, aₙ, sₙ⟩. For each step, it must:-
State the current world state ( s_i). -
Propose an action ( a_i+1). -
Explicitly verify all preconditions against the current state. -
Apply the action’s effects to compute the next state ( s_i+1).
-
-
External Verification (The “Truth”): The generated reasoning chain is fed to the VAL plan validator, a classic, deterministic tool that checks every single state transition for logical correctness. VAL is the unforgiving referee; it doesn’t care if the reasoning sounds smart, only if it’s logically sound.
-
Feedback Loop: VAL provides feedback on the model’s reasoning. The researchers tested two types:
-
Binary Feedback: Simply “Valid” or “Invalid.” -
Detailed Feedback: “Invalid. Precondition (holding A)for actionstackwas not satisfied in states₂.”
Unsurprisingly, detailed feedback proved far more effective, acting as a precise tutorial for the model on its specific mistakes.
-
-
Two-Stage Optimization: The model’s parameters are updated in two distinct stages based on this feedback:
-
Stage 1 (Reasoning Chain Optimization): The loss function penalizes errors in the intermediate reasoning steps (e.g., incorrect state transitions). This teaches the model how to think. -
Stage 2 (Final Performance Optimization): The loss function then focuses on whether the entire final plan is valid. This teaches the model to apply its improved reasoning to produce correct answers.
-
This iterative process of generate-validate-learn is repeated for a set number of cycles (η), with the model getting smarter with each iteration.
Phase 3: The Evaluation
After training, the model is put to the test on a completely unseen set of problems (D_test). It must generate plans with CoT reasoning from scratch, and these plans are validated by VAL—this time, only for assessment, with no feedback given to the model.
The Proof is in the Planning: Experimental Results and Analysis
The team evaluated their method using PlanBench, a standardized benchmark for evaluating LLM planning capabilities, across three domains of increasing difficulty:
-
Blocksworld: The classic stacking domain. Tests basic reasoning. -
Mystery Blocksworld: A fiendish variant where predicate names are obfuscated (e.g., (on)becomes(foobar)). This breaks an LLM’s reliance on pattern-matching and forces true understanding of semantics. It’s the ultimate test of logical reasoning. -
Logistics: A transportation domain involving moving packages between cities using trucks and planes. Tests more complex, multi-step reasoning.
The results, detailed in Table 1 of the paper, speak for themselves. Here’s a summary for the Llama-3-8B model:
| Domain | Baseline | Only Phase 1 | PDDL-Instruct (Detailed, η=15) | Improvement (Absolute) |
|---|---|---|---|---|
| Blocksworld | 28% | 78% | 94% | +66% |
| Mystery BW | 1% | 32% | 64% | +63% (64x) |
| Logistics | 11% | 23% | 79% | +68% |
Table: Plan Accuracy (%) across different domains and training phases.
The takeaways are profound:
-
Massive Gains: PDDL-Instruct provided enormous absolute improvements over the baseline (up to 66%). -
The Power of CoT: The two-phase process is crucial. Models with “Only Phase 2” performed worse, showing that the foundational knowledge from Phase 1 is essential. -
Detailed Feedback Wins: Detailed feedback consistently outperformed binary feedback across all domains. -
Generalization: The model didn’t just memorize; it learned general logical reasoning skills that transferred across domains. The stunning improvement on Mystery Blocksworld—from a near-useless 1% to a capable 64%—proves that the model learned to reason based on logic, not just vocabulary.
An error analysis (from the appendix) showed that even the best model still made mistakes, primarily in applying effects incorrectly and violating preconditions in the most complex domains, pointing the way for future research.
Why This Matters: Implications for the Future of AI and Robotics
This work is far more than an academic exercise. It’s a blueprint for building more reliable and trustworthy AI systems.
-
Reliable Autonomous Agents: This technology is a direct path towards robots and virtual agents that can form verifiably correct plans for complex tasks, from warehouse logistics to household chores. -
Bridging the Neuro-Symbolic Gap: PDDL-Instruct beautifully combines the strengths of neural networks (flexibility, generalization, learning from data) with the strengths of symbolic AI (precision, reliability, verifiability). This hybrid approach is considered by many to be the key to robust AI. -
Verifiable and Safe AI: In safety-critical domains like autonomous driving or medical treatment planning, being able to formally verify an AI’s proposed plan before execution is non-negotiable. This work shows a viable path forward.
Limitations, Challenges, and Future Work
No research is without its limitations, and the MIT team is transparent about them:
-
External Verifier Dependency: The framework currently relies on VAL. The long-term goal is to develop LLMs with robust self-verification capabilities, reducing or eliminating this dependency. -
Classical Planning Focus: The current work handles “classical” STRIPS PDDL. Handling more complex features like numerical constraints, time, and conditional effects is a clear next step. -
Computational Cost: The iterative training process with repeated VAL calls is computationally expensive. -
Satisficing vs. Optimal: The framework produces valid plans, not necessarily the shortest or most efficient ones. Guiding models towards optimality is a harder challenge.
FAQ: Your Questions About PDDL-Instruct, Answered
How is this different from standard Chain-of-Thought prompting?
Standard CoT encourages the model to “show its work” but provides no guarantee that the intermediate steps are logically correct. The model often produces “faithful” but incorrect reasoning. PDDL-Instruct uses ground-truth external validation (VAL) to provide definitive feedback, ensuring the model learns correct logical rules, not just persuasive-looking reasoning.
Do I need a verifier like VAL to use this?
For training the model using the PDDL-Instruct method, yes, VAL is essential. However, once the model is trained, it can be used for inference on new problems without VAL. The hope is that the model internalizes the logical rules so well that it generates valid plans independently. The validation at inference time is then only needed if you require 100% certainty.
Can this framework be applied to other reasoning tasks?
Absolutely. The core idea—generating explicit reasoning steps, validating them with a reliable external tool, and using the feedback for instruction tuning—is highly generalizable. It could be applied to mathematical reasoning, code verification, theorem proving, and legal logic analysis.
What are the computational requirements?
According to the paper’s appendix (A4), training was done on 2x NVIDIA RTX 3080 GPUs (24GB VRAM each). Phase 1 took ~12 hours, and Phase 2 took ~18 hours. This is remarkably accessible for a research project of this impact.
Conclusion: A Giant Leap Towards Truly Intelligent AI
The MIT CSAIL team’s PDDL-Instruct isn’t just an incremental improvement; it’s a demonstration of how to fundamentally reshape the capabilities of large language models. By moving beyond pattern recognition to ingrained logical reasoning, they have provided a path forward for creating AI that doesn’t just sound smart—but actually is smart, reliable, and verifiable.
They have given us a powerful recipe: combine the creative power of neural networks with the rigorous truth-telling of symbolic validators. This work gets us significantly closer to a future where we can truly trust the plans that our AI companions devise.
