

MiniCPM-V 4.5: A GPT-4o-Level Multimodal Model That Runs on Smartphones — Complete Breakdown and Practical Guide
If you’re searching for a multimodal model that runs smoothly on smartphones while delivering GPT-4o-level vision-language capabilities, MiniCPM-V 4.5 — the latest release from OpenBMB — might be your top choice. Despite its lightweight design (just 8 billion parameters), this model outperforms well-known alternatives like GPT-4o-latest and Gemini 2.0 Pro in core areas such as vision-language understanding, long video processing, and OCR/document parsing.
In this guide, we’ll break down everything you need to know about this “small yet powerful” edge-side multimodal model: its core architecture, performance benchmarks, key features, step-by-step usage instructions, and deployment options. By the end, you’ll understand exactly what it can do, how to use it, and whether it fits your needs.
1. MiniCPM-V 4.5 Basics: Lightweight Architecture for Edge Devices
Before diving into its capabilities, let’s start with the fundamentals — MiniCPM-V 4.5’s architecture, parameter count, and core dependencies. These details explain why it can run on smartphones and deliver high performance.
1.1 Core Parameter Overview
| Item | Details |
|---|---|
| Model Series | Latest version of the MiniCPM-V lineup (current top-performing edge multimodal model) |
| Base Architecture | Built on Qwen3-8B (language model) and SigLIP2-400M (vision model) |
| Total Parameters | 8 billion (8B) |
| Edge Device Support | Runs on smartphones (e.g., iPhone, iPad M4) and regular PCs (CPU/GPU) |
| Core Design Goal | Achieve GPT-4o-level single-image, multi-image, and video understanding on low-resource hardware |
| Official Resources | GitHub: https://github.com/OpenBMB/MiniCPM-o Online Demo: http://101.126.42.235:30910/ |
The parameters highlight MiniCPM-V 4.5’s biggest advantage: lightweight high performance. With just 8B parameters (far fewer than the 72B parameters of Qwen2.5-VL 72B), it still outperforms larger models — making it ideal for edge devices like smartphones and basic laptops.
2. Performance Benchmarks: 8B Parameters Outperform GPT-4o, Top Among <30B Models
A common question arises: “Can a lightweight model really compete with larger alternatives?” The answer lies in its performance on OpenCompass — a comprehensive evaluation platform covering 8 popular vision-language benchmarks. MiniCPM-V 4.5 scored an average of 77.2, placing it ahead of many industry leaders.
2.1 Key Benchmark Results
-
Outperforms Major Models: Despite its 8B parameter size, it surpasses GPT-4o-latest (OpenAI’s newest multimodal model), Gemini 2.0 Pro (Google’s flagship model), and Qwen2.5-VL 72B (a powerful open-source model). -
Top Performer Under 30B Parameters: Among multimodal models (MLLMs) with fewer than 30 billion parameters, MiniCPM-V 4.5 ranks first — setting a new standard for lightweight model performance.
2.2 Visual Benchmark References
The following charts illustrate MiniCPM-V 4.5’s performance against other models (data source: official MiniCPM-V 4.5 evaluations):
-
Performance Radar Chart (covering multi-dimensional vision-language capabilities):
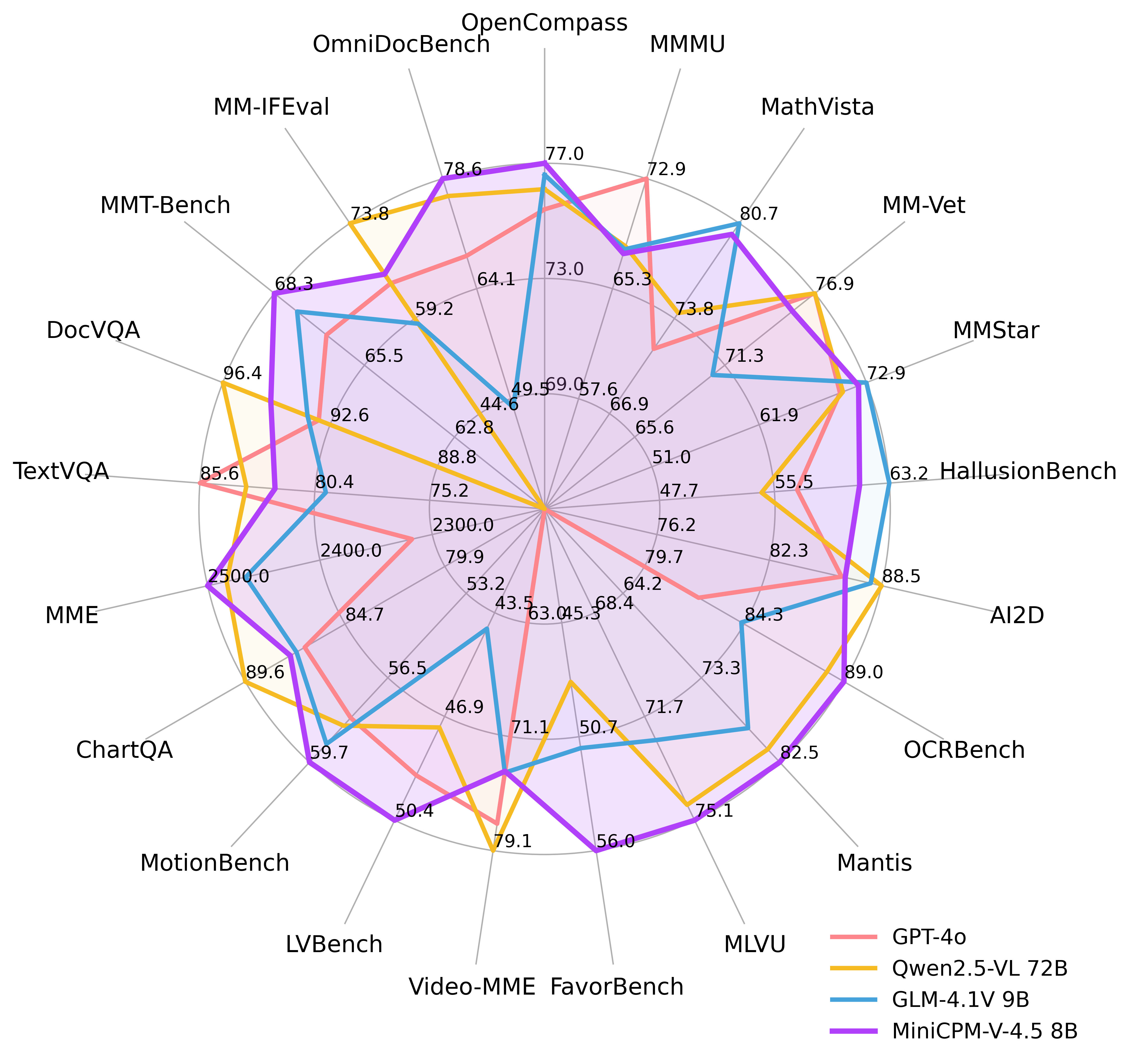
-
Detailed Benchmark Comparison:


These results challenge the myth that “more parameters equal better performance.” MiniCPM-V 4.5 is especially well-suited for scenarios where hardware resources are limited but high-quality multimodal capabilities are required — such as smartphone apps or local processing on basic office computers.
3. Core Feature Breakdown: From Video Understanding to OCR for Real-World Use
MiniCPM-V 4.5’s features are designed for practicality. Whether you need to process daily tasks or tackle complex professional scenarios, it offers solutions tailored to real needs. Let’s break down its key capabilities and how they solve common problems.
3.1 Efficient High-FPS and Long Video Processing: The 3D-Resampler Advantage
Many multimodal models struggle with long or high-frame-rate (FPS) videos: more frames mean more computing power, leading to lag on smartphones or regular PCs. MiniCPM-V 4.5 solves this with 3D-Resampler technology.
How 3D-Resampler Works (Simplified)
3D-Resampler compresses large numbers of video frames into a small number of “tokens” — the basic units models use to process information. For example:
-
Other multimodal models typically require 1,536 tokens to process 6 video frames (448×448 resolution). -
MiniCPM-V 4.5 needs only 64 tokens for the same 6 frames — a 96x compression ratio.
Practical Benefits
-
Processes more video frames without increasing inference costs. -
Supports high-FPS video understanding (up to 10 FPS) — ideal for fast-moving scenes like sports or dynamic events. -
Handles long videos easily (leading performance on video benchmarks like Video-MME, LVBench, and MotionBench).
Use Case Example: Imagine filming a 1-minute sports video on your phone and asking the model to analyze the actions. Or extracting key details from a long security camera clip — MiniCPM-V 4.5 won’t lag, even with high frame rates or extended runtime.
3.2 Controllable Fast/Deep Thinking Modes: Balance Speed and Precision
Different tasks require different trade-offs between speed and accuracy:
-
You need quick answers for simple questions like “What’s in this photo.” -
You need detailed reasoning for complex tasks like “Analyze if this geological structure matches a specific formation.”
MiniCPM-V 4.5 lets you switch between fast and deep thinking modes with one setting, balancing efficiency and performance.
| Mode | Use Case | Advantages | Limitations |
|---|---|---|---|
| Fast Thinking Mode | Daily high-frequency tasks (e.g., image recognition, simple Q&A) | Fast response, efficient for frequent use | Not ideal for complex tasks (e.g., deep reasoning) |
| Deep Thinking Mode | Complex tasks (e.g., professional document parsing, in-depth video analysis) | More accurate reasoning for multi-step problems | Slower response than Fast Thinking Mode |
How to Switch: Control the mode using the enable_thinking parameter when calling the model (enable_thinking=True for Deep Thinking, False for Fast Thinking). We’ll show you exactly how to use this in the “Practical Guide” section below.
3.3 Powerful OCR and Document Parsing: Handle High-Resolution and Complex Formats
OCR (Optical Character Recognition) and document parsing are essential for office and academic work — but many models struggle with high-resolution images, complex tables, or handwritten text. MiniCPM-V 4.5 excels in these areas.
3.3.1 OCR Highlights
-
High-Resolution Support: Processes images of any aspect ratio with up to 1.8 million pixels (e.g., 1344×1344 resolution) using 4x fewer visual tokens than other models — reducing computing pressure. -
Leading Accuracy: Outperforms commercial models like GPT-4o-latest and Gemini 2.5 on OCRBench (the industry’s权威 OCR benchmark). -
Handwritten Text Support: Accurately recognizes both English and Chinese handwritten text (see examples below).
English Handwriting OCR Example:
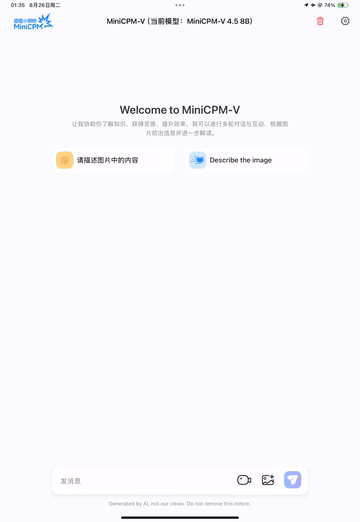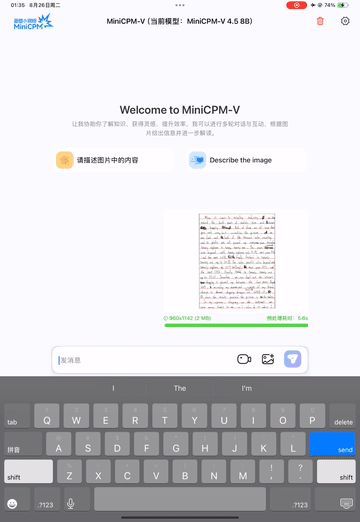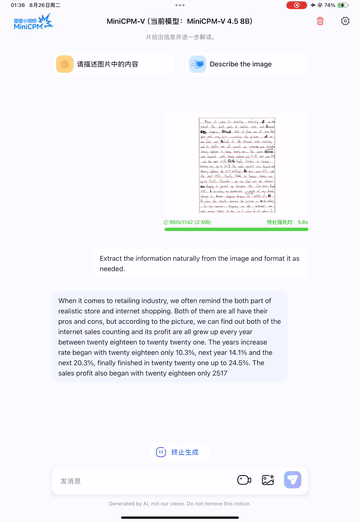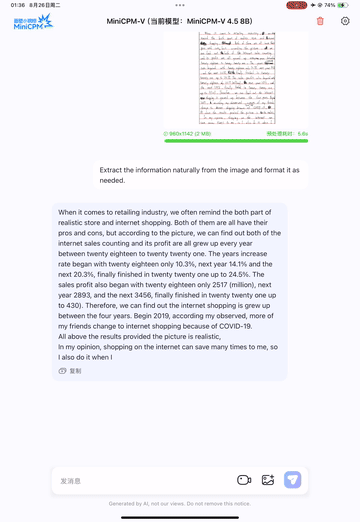
Chinese Handwriting OCR Example:
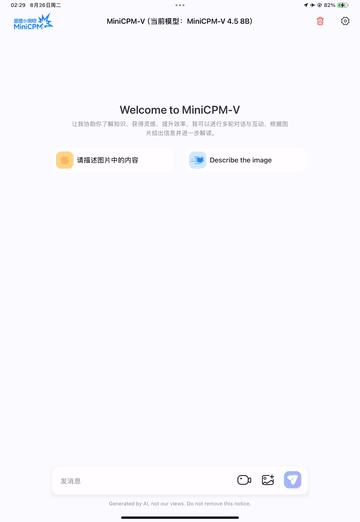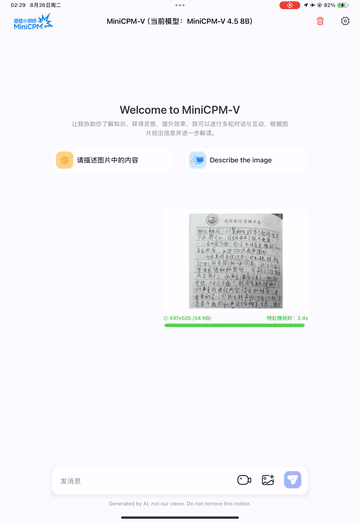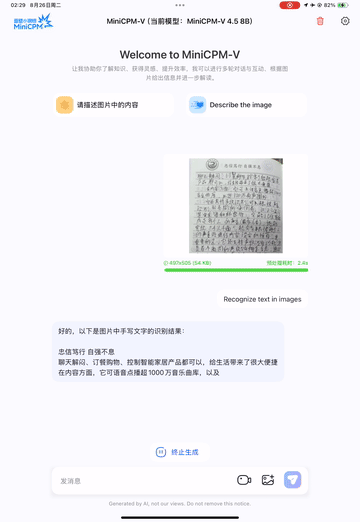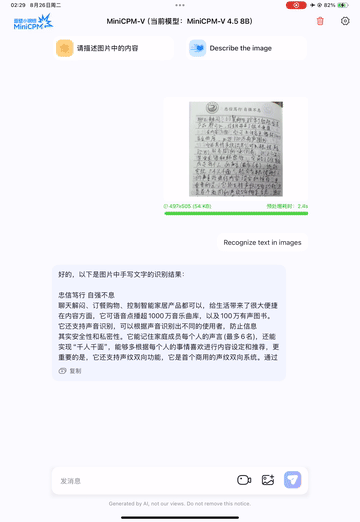
3.3.2 Document Parsing Capabilities
-
Top-Tier PDF Parsing: Ranks first among general multimodal models on OmniDocBench (a key document parsing benchmark). -
Complex Format Support: Handles multi-column documents, complex tables, and mixed text-image PDFs — such as data tables in research papers or formatted financial reports.
Use Case Example: Take a photo of your handwritten notes with your phone, and the model converts it to editable text. Or parse a 50-page research PDF on your laptop to extract table data — MiniCPM-V 4.5 outperforms traditional OCR tools in both scenarios.
3.4 Reliability and Multilingual Support: For Professional and Cross-Border Use
Beyond core features, MiniCPM-V 4.5 prioritizes reliability and language flexibility to meet professional and global needs.
-
Enhanced Reliability: Uses RLAIF-V and VisCPM technologies to reduce “hallucinations” (fictional but confident answers). It outperforms GPT-4o-latest on MMHal-Bench (a reliability benchmark), making it more trustworthy for critical tasks. -
Multilingual Support: Works with 30+ languages, including Chinese, English, Japanese, French, and Spanish. It not only recognizes multilingual images/documents but also supports multilingual conversations.
Use Case Example: A multinational company can use it to parse multilingual contracts. A researcher can analyze academic papers in non-English languages — no language barriers required.
4. Practical Guide: How to Use MiniCPM-V 4.5? (Full Code Included)
Knowing what the model can do is only half the battle — the key is knowing how to use it. MiniCPM-V 4.5 supports multiple usage methods (local CPU/GPU, smartphone, online demo). We’ll focus on the most common scenarios: Python code for image/video interaction and local deployment steps.
4.1 Environment Setup: What Tools Do You Need?
First, install the required Python libraries. The commands below work for Windows, macOS, and Linux:
# Core dependencies (model loading, image processing)
pip install torch pillow transformers
# Video processing dependencies (required for video tasks)
pip install decord scipy numpy
# Quantized model support (for int4/GGUF formats)
pip install autoawq llama-cpp-python
# High-throughput inference support (for SGLang/vLLM)
pip install sglang vllm
4.2 Single-Image/Multi-Image Interaction: Basic Usage Example
Let’s walk through a complete example: analyzing a landscape photo and asking follow-up questions about travel precautions. This includes multi-turn conversations.
4.2.1 Full Code
# 1. Import required libraries
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
# 2. Set random seed (ensures reproducible results)
torch.manual_seed(100)
# 3. Load the model and tokenizer
# Note: trust_remote_code=True loads the model's custom code
model = AutoModel.from_pretrained(
'openbmb/MiniCPM-V-4_5', # Model name (alternatively use openbmb/MiniCPM-o-2_6)
trust_remote_code=True,
attn_implementation='sdpa', # Attention mechanism: choose 'sdpa' or 'flash_attention_2'
torch_dtype=torch.bfloat16 # Data type (boosts inference speed)
)
# Set model to evaluation mode and load to GPU (remove .cuda() for CPU-only use)
model = model.eval().cuda()
# Load tokenizer (processes text input)
tokenizer = AutoTokenizer.from_pretrained(
'openbmb/MiniCPM-V-4_5',
trust_remote_code=True
)
# 4. Load your image (replace with your image path)
image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')
# 5. Set thinking mode (False = Fast Thinking; True = Deep Thinking)
enable_thinking = False
# 6. First conversation: Ask about the landscape in the image
question1 = "What is the landform in the picture?"
# Build conversation history (format: list of dictionaries with "role" and "content")
msgs = [{'role': 'user', 'content': [image, question1]}]
# Generate answer from the model
answer1 = model.chat(
msgs=msgs,
tokenizer=tokenizer,
enable_thinking=enable_thinking
)
# Print first round answer
print("First Round Answer:")
print(answer1)
print("-" * 50)
# 7. Second conversation: Follow up about travel precautions (uses context)
# Update conversation history (add assistant's answer and new user question)
msgs.append({"role": "assistant", "content": [answer1]})
question2 = "What should I pay attention to when traveling here?"
msgs.append({"role": "user", "content": [question2]})
# Generate second round answer (no need to re-set enable_thinking; uses previous setting)
answer2 = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
# Print second round answer
print("Second Round Answer:")
print(answer2)
4.2.2 Example Output
# First Round Answer
The landform in the picture is karst topography. Karst landscapes are characterized by distinctive, jagged limestone hills or mountains with steep, irregular peaks and deep valleys—exactly what you see here. These unique formations result from the dissolution of soluble rocks like limestone over millions of years through water erosion.
This scene closely resembles the famous karst landscape of Guilin and Yangshuo in China’s Guangxi Province. The area features dramatic, pointed limestone peaks rising dramatically above serene rivers and lush green forests, creating a breathtaking and iconic natural beauty that attracts millions of visitors each year for its picturesque views.
# Second Round Answer
When traveling to a karst landscape like this, here are some important tips:
1. Wear comfortable shoes: The terrain can be uneven and hilly.
2. Bring water and snacks for energy during hikes or boat rides.
3. Protect yourself from the sun with sunscreen, hats, and sunglasses—especially since you’ll likely spend time outdoors exploring scenic spots.
4. Respect local customs and nature regulations by not littering or disturbing wildlife.
By following these guidelines, you'll have a safe and enjoyable trip while appreciating the stunning natural beauty of places such as Guilin’s karst mountains.
4.2.3 Key Parameter Explanations
-
attn_implementation: Choose the attention mechanism.sdpais PyTorch’s natively supported efficient option;flash_attention_2is faster but requires installing the FlashAttention library separately. -
torch_dtype=torch.bfloat16: Uses 16-bit floating-point numbers instead of 32-bit (float32). This saves memory without significant performance loss. -
enable_thinking: Controls the thinking mode. UseTruefor complex tasks (e.g., analyzing research papers) andFalsefor simple tasks (e.g., recognizing objects in photos) to speed up responses.
4.3 Video Interaction: Process Videos with 3D-Resampler
Next, we’ll show you how to use MiniCPM-V 4.5 to analyze videos (e.g., describing video content). The key here is leveraging 3D-Resampler to compress video frames efficiently.
4.3.1 Full Code
# 1. Import required libraries (including video processing tools)
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # For reading video frames
from scipy.spatial import cKDTree
import numpy as np
import math
# 2. Load model and tokenizer (same as image interaction)
model = AutoModel.from_pretrained(
'openbmb/MiniCPM-V-4_5',
trust_remote_code=True,
attn_implementation='sdpa',
torch_dtype=torch.bfloat16
)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(
'openbmb/MiniCPM-V-4_5',
trust_remote_code=True
)
# 3. Video processing configuration (no need to modify; use defaults)
MAX_NUM_FRAMES = 180 # Maximum number of frames the model accepts after packing
MAX_NUM_PACKING = 3 # Maximum number of frames per pack (1-6)
TIME_SCALE = 0.1 # Time scale for mapping frame timestamps
# 4. Helper functions: Core logic for video frame sampling and packing (3D-Resampler)
def map_to_nearest_scale(values, scale):
"""Map frame timestamps to the nearest time scale"""
tree = cKDTree(np.asarray(scale)[:, None])
_, indices = tree.query(np.asarray(values)[:, None])
return np.asarray(scale)[indices]
def group_array(arr, size):
"""Group array into chunks of specified size (for frame packing)"""
return [arr[i:i+size] for i in range(0, len(arr), size)]
def encode_video(video_path, choose_fps=3, force_packing=None):
"""
Process video: Sample frames, calculate packing count, generate timestamp IDs
Parameters:
video_path: Path to your video file
choose_fps: Target FPS (e.g., 3 = 3 frames per second)
force_packing: Force a specific packing count (auto-calculated by default)
Returns:
frames: List of sampled image frames
frame_ts_id_group: Grouped timestamp IDs (for 3D-Resampler)
"""
# Uniform sampling function
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
# Read video
vr = VideoReader(video_path, ctx=cpu(0))
fps = vr.get_avg_fps() # Original video FPS
video_duration = len(vr) / fps # Total video duration (seconds)
# Calculate packing count and number of sampled frames
if choose_fps * int(video_duration) <= MAX_NUM_FRAMES:
packing_nums = 1
choose_frames = round(min(choose_fps, round(fps)) * min(MAX_NUM_FRAMES, video_duration))
else:
packing_nums = math.ceil(video_duration * choose_fps / MAX_NUM_FRAMES)
if packing_nums <= MAX_NUM_PACKING:
choose_frames = round(video_duration * choose_fps)
else:
choose_frames = round(MAX_NUM_FRAMES * MAX_NUM_PACKING)
packing_nums = MAX_NUM_PACKING
# Sample video frames
frame_idx = [i for i in range(0, len(vr))]
frame_idx = np.array(uniform_sample(frame_idx, choose_frames))
# Force packing count (if specified)
if force_packing:
packing_nums = min(force_packing, MAX_NUM_PACKING)
# Print video info
print(f"Video Path: {video_path}, Duration: {video_duration:.2f} seconds")
print(f"Sampled Frames: {len(frame_idx)}, Packing Count: {packing_nums}")
# Read sampled frames and convert to images
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')).convert('RGB') for v in frames]
# Generate frame timestamp IDs and group them
frame_idx_ts = frame_idx / fps # Frame timestamps (seconds)
scale = np.arange(0, video_duration, TIME_SCALE) # Time scale
frame_ts_id = map_to_nearest_scale(frame_idx_ts, scale) / TIME_SCALE
frame_ts_id = frame_ts_id.astype(np.int32)
frame_ts_id_group = group_array(frame_ts_id, packing_nums)
return frames, frame_ts_id_group
# 5. Process video (replace with your video path)
video_path = "video_test.mp4"
target_fps = 5 # Target FPS (5 frames per second)
force_packing = None # Auto-calculate packing count (no forced value)
frames, frame_ts_id_group = encode_video(video_path, target_fps, force_packing)
# 6. Ask about the video and generate a response
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]}, # Content: Frame list + question
]
# Generate answer (must include temporal_ids to enable 3D-Resampler)
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
use_image_id=False,
max_slice_nums=1,
temporal_ids=frame_ts_id_group # Timestamp ID groups for video frames
)
# Print the result
print("Video Analysis Result:")
print(answer)
4.3.2 Key Notes
-
The encode_videofunction is critical for video processing. It automatically calculates the “packing count” based on video duration and target FPS to ensure the number of frames stays within the model’s limits. -
The temporal_ids=frame_ts_id_groupparameter enables 3D-Resampler. Omit this, and the model will treat video frames as separate images — losing the efficiency of frame compression. -
For CPU-only use (no GPU), remove .cuda()frommodel.eval().cuda(). Inference will be slower, but it works on regular PCs.
5. Local Deployment and Multi-Platform Support: From PCs to Smartphones
A major advantage of MiniCPM-V 4.5 is its cross-platform compatibility. Whether you want to run it on a regular PC, smartphone, or via a web interface, there’s a solution.
5.1 Deployment Options by Platform
| Target Platform | Deployment Tool/Format | Advantages | Use Case | Relevant Links |
|---|---|---|---|---|
| Regular PC (CPU) | llama.cpp, ollama | No GPU required; efficient CPU inference | Low-spec PCs without dedicated graphics cards | llama.cpp: https://github.com/tc-mb/llama.cpp ollama: https://github.com/tc-mb/ollama |
| PC (GPU) | SGLang, vLLM | High throughput; memory-efficient; ideal for batch processing | PCs with GPUs (e.g., RTX 3060 or higher) | SGLang: https://github.com/tc-mb/sglang vLLM: Refer to official documentation |
| Smartphone (iOS) | Official iOS Demo | Runs directly on iPhones/iPads; local interaction | On-site tasks (e.g., real-time OCR, image analysis) | https://github.com/tc-mb/MiniCPM-o-demo-iOS |
| Local Web Interface | Gradio WebUI | Visual interface; no coding required | Non-developers needing intuitive operation | Official documentation mentions a “quick local WebUI demo” (see GitHub Cookbook) |
| Online Testing | Official Online Demo | No deployment needed; instant testing | Fast feature validation | http://101.126.42.235:30910/ |
5.2 Quantized Models: Lower Hardware Requirements
If your device has limited resources (e.g., a PC with 4GB RAM), use quantized versions of MiniCPM-V 4.5. Quantization reduces parameter precision to lower memory usage while preserving most performance.
Official Quantized Formats and Sizes
-
Formats: int4, GGUF, AWQ -
Memory Requirements: 16 different sizes (e.g., the int4 format runs on devices with ~4GB RAM) -
Download Links: -
int4: https://huggingface.co/openbmb/MiniCPM-V-4_5-int4 -
GGUF: https://huggingface.co/openbmb/MiniCPM-V-4_5-gguf -
AWQ: Use the AutoAWQ tool (see https://github.com/tc-mb/AutoAWQ for instructions)
-
6. License and Commercial Use: Free for Research, Registered Access for Commercial Use
Many users ask: “Do I need to pay to use this model? Is commercial use allowed?” Below is a breakdown based on official documentation:
6.1 License Types
| Category | License Type | Description |
|---|---|---|
| Code (GitHub Repo) | Apache-2.0 License | Open-source and free; modify/distribute with copyright notice |
| Model Weights | MiniCPM Model License | Free for academic research; commercial use requires registration |
6.2 Commercial Use Process
-
Academic Research: No application needed — use the model weights for free. -
Commercial Use: -
Step 1: Register by filling out the official questionnaire (link: https://modelbest.feishu.cn/share/base/form/shrcnpV5ZT9EJ6xYjh3Kx0J6v8g). -
Step 2: After approval, use the model weights for free commercially.
-
6.3 Disclaimer
-
Content generated by the model is for learning and research purposes only and does not represent the views of OpenBMB (the model developer). -
The developer is not liable for any issues arising from model use, including but not limited to data security risks, public opinion issues, or losses from misuse.
7. FAQ: Answers to Common Questions
We’ve compiled frequently asked questions based on user needs — all answers are sourced from official documentation.
Q1: How does MiniCPM-V 4.5 differ from earlier MiniCPM models (e.g., MiniCPM-o, MiniCPM-V)?
A1: MiniCPM-V 4.5 is the latest and most powerful model in the MiniCPM-V lineup. Key improvements include: ① Dramatically enhanced vision-language capabilities (77.2 average score on OpenCompass); ② New 3D-Resampler technology for efficient video processing; ③ Support for dual Fast/Deep Thinking modes; ④ Significantly improved OCR and document parsing (outperforming GPT-4o-latest).
Q2: Can I run MiniCPM-V 4.5 on a regular PC without a high-end GPU?
A2: Yes. Official tools like llama.cpp and ollama support CPU-only inference — even a regular PC with 8GB RAM can run the model. For devices with 4GB RAM, use the int4 or GGUF quantized models to reduce memory usage.
Q3: What’s the maximum video duration MiniCPM-V 4.5 can handle?
A3: It depends on the target FPS and packing count. For example, with a target FPS of 3 and maximum packing count of 3 (MAX_NUM_PACKING=3), the maximum supported duration is ~(MAX_NUM_FRAMES * MAX_NUM_PACKING) / target FPS = (180 * 3) / 3 = 180 seconds (3 minutes). Adjust the choose_fps parameter to fit longer/shorter videos.
Q4: Does the OCR feature support handwritten text? Which languages does it handle?
A4: ① Yes — the OCR feature supports handwritten text. Official examples show accurate recognition of both Chinese and English handwriting. ② OCR supports 30+ languages (matching the model’s multilingual capabilities), including Chinese, English, Japanese, and French.
Q5: Is commercial use of MiniCPM-V 4.5 free? What are the registration requirements?
A5: ① Commercial use is free — no fees after registration approval. ② The registration questionnaire mainly collects basic information about your organization (e.g., company name, use case). No additional requirements are specified; simply fill it out truthfully.
Q6: How big is the performance gap between Fast Thinking and Deep Thinking modes? How do I switch between them?
A6: ① The gap depends on the task: Fast Thinking is fast but suited for simple tasks (e.g., image recognition); Deep Thinking is slower but more accurate for complex reasoning (e.g., analyzing research papers). ② Switch modes using the enable_thinking parameter in model.chat() (True for Deep Thinking, False for Fast Thinking).
Q7: Can it parse PDF documents? Does it handle complex tables?
A7: Yes to both. MiniCPM-V 4.5 uses the LLaVA-UHD architecture to process high-resolution PDFs and ranks first on OmniDocBench (a document parsing benchmark). It supports complex tables, multi-column layouts, and mixed text-image PDFs — ideal for research papers and financial reports.
Q8: Can I run MiniCPM-V 4.5 on an Android smartphone?
A8: Official support for Android is not yet available, but the team has released an iOS Demo (supports iPhones and iPads like the iPad M4). For Android, you can try local deployment using open-source tools like the Android version of llama.cpp. Follow the official GitHub repo (https://github.com/OpenBMB/MiniCPM-o) for updates.
8. Related Technologies and Citations
For deeper technical insights into MiniCPM-V 4.5, refer to these official projects:
-
VisCPM: https://github.com/OpenBMB/VisCPM (vision-language model technology) -
RLHF-V: https://github.com/RLHF-V/RLHF-V (reinforcement learning alignment) -
LLaVA-UHD: https://arxiv.org/pdf/2403.11703 (high-resolution image processing architecture) -
RLAIF-V: https://github.com/RLHF-V/RLAIF-V/ (model reliability optimization)
Academic Citation
If you use MiniCPM-V 4.5 in research or projects, cite the following paper:
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={Nat Commun 16, 5509 (2025)},
year={2025}
}
9. Conclusion
MiniCPM-V 4.5 redefines what edge-side multimodal models can do. With just 8B parameters, it delivers GPT-4o-level performance, runs on smartphones and regular PCs, and handles real-world tasks like video processing, OCR, and document parsing.
Whether you’re a researcher, a professional needing local tools, or a developer building edge applications, its low hardware requirements and high实用性 make it a standout choice.
To get started:
-
Test the model instantly via the official online demo (http://101.126.42.235:30910/). -
For local use, deploy it via llama.cpp (CPU) or SGLang (GPU) — use quantized models if resources are limited. -
Follow the official GitHub repo for updates on new features (e.g., Android support).
MiniCPM-V 4.5 proves that you don’t need a supercomputer to access top-tier multimodal AI — it’s now available right on your phone.

