

2025 LLM Year in Review: Six Paradigm Shifts and Future Implications
The LLM landscape in 2025 evolved beyond a mere race for scale, fundamentally reshaping our understanding of intelligence, training methodologies, and application paradigms.


2025 has been a monumental year for Large Language Models. We witnessed not just incremental performance gains but a series of fundamental “paradigm changes.” These shifts have redefined how we perceive artificial intelligence, how we train these systems, and how they integrate into our digital lives. This article breaks down these key transformations, explaining their underlying logic and profound implications in accessible terms.
1. From Human Feedback to Verifiable Rewards: How RLVR Taught AI to “Think”
For a long time, producing a mature, commercial-grade LLM followed a classic recipe: large-scale pretraining, supervised fine-tuning, and Reinforcement Learning from Human Feedback. This pipeline was stable and effective—until 2025, when a new core stage was widely introduced: Reinforcement Learning from Verifiable Rewards.
So, what exactly is RLVR, and why is it so significant?
In simple terms, RLVR trains LLMs in environments where success can be automatically judged, such as solving math problems or coding puzzles. The system provides a clear, objective reward signal (e.g., whether the problem was solved correctly). During this process, the model isn’t explicitly told how to reason step-by-step. Instead, it must explore and experiment, spontaneously developing strategies that, to humans, resemble “reasoning.” It learns to break down complex problems into intermediate steps, tries different solution strategies, and even learns to backtrack and correct errors.
This represents a fundamental departure from previous training methods:
-
SFT (Supervised Fine-Tuning) and RLHF (Reinforcement Learning from Human Feedback) are relatively “short and light” stages, primarily involving fine-tuning. -
RLVR enables prolonged optimization. Because it has an objective, non-gameable reward target, computational resources can be poured into it continuously, driving sustained capability improvements.
The direct consequences were:
-
“Thinking Time” as a New Dimension: RLVR models can improve answer quality at test time by generating longer “reasoning traces.” This means “compute” can be flexibly converted into “thinking depth.” -
Reallocation of Compute Resources: The RLVR stage proved to be highly cost-effective in terms of capability gain per dollar. Vast amounts of compute originally earmarked for pretraining were redirected here. Thus, the 2025 capability leap came primarily from models undergoing much longer RLVR runs, not just from them being larger. -
Flagship Models Emerged: OpenAI’s o1 model was the first demonstration of RLVR, but the o3 release in early 2025 was the inflection point where the public could intuitively feel this qualitative shift.
The Layman’s Explanation: Think of RLVR as putting an AI in a super library with infinite practice workbooks and an automatic grading system. It has no teacher guiding each step, but by constantly solving problems and seeing what’s right/wrong, it deduces its own efficient methods for learning and problem-solving.
2. Ghosts vs. Animals: Understanding the “Jagged” Shape of LLM Intelligence
In 2025, the industry began to grasp the unique “shape” of LLM intelligence more intuitively. A core metaphor emerged: we are not “evolving or raising animals,” but “summoning ghosts.”
Why “Ghosts” and not “Animals”?
Because everything about building an LLM—its neural architecture, training data, optimization objectives—is fundamentally different from the evolutionary path of biological intelligence. The human brain is “optimized” for survival and reproduction in a complex world. The LLM is “optimized” to imitate human text, score points on math puzzles, and get thumbs-ups in evaluations.
This leads to two key characteristics:
-
Jagged Capability Profile: In verifiable domains amenable to RLVR (like math, coding), LLMs develop sharp “spikes” of ability, performing like polymath geniuses. Yet, in areas less “verifiable”—common sense, complex reasoning, or adversarial scenarios (like security bypasses)—their performance can plummet instantly, resembling a confused grade-schooler easily tricked.
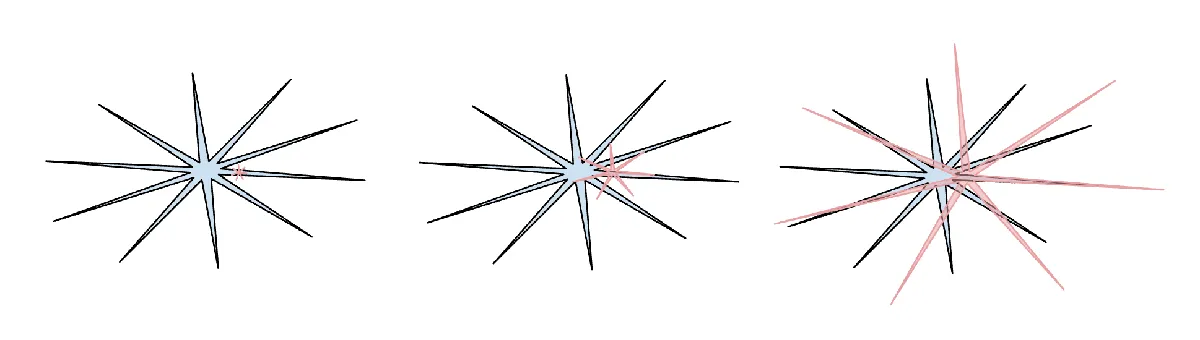
(Schematic: Blue represents human intelligence, red represents AI intelligence. Both have their own unique “jagged” profiles.) -
A Crisis of Trust in Benchmarks: Since benchmark tests are themselves “verifiable environments,” they naturally become the primary target for RLVR optimization. Teams inevitably train specialized “capability spikes” to cover the problem types found in these benchmarks. This has turned “training on the test set” into a new art form and forces us to ask: Does crushing all benchmarks equate to achieving Artificial General Intelligence (AGI)? The answer is clearly no.

The Core Insight: LLMs represent a new, non-biological form of intelligence. It’s inappropriate to judge them by the “smooth” standards we apply to human intelligence. We must accept and understand their “jagged” nature—where brilliance and naivety coexist—and manage this appropriately in their application.
3. The Cursor Phenomenon: Revealing a New “LLM App” Layer
Beyond model advancements, 2025 saw significant innovation at the application layer. The meteoric rise of Cursor clearly revealed a new tier of “LLM applications,” sparking discussions about “Cursor for X” in various fields.
What exactly do these new applications do?
They are far more than simple API calls. As outlined by Andrej Karpathy in his Y Combinator talk, their core value lies in:
-
Context Engineering: They meticulously construct and prepare conversational context for specific verticals (e.g., programming, design, writing). -
Complex Orchestration: Under the hood, they orchestrate multiple LLM calls into increasingly complex directed acyclic graphs, carefully balancing performance and cost. -
Domain-Specific GUI: They provide graphical user interfaces tailored to specific workflows, drastically optimizing human-AI collaboration. -
The “Autonomy Slider”: Users can flexibly adjust the AI’s level of independent operation based on task requirements.
A key market question arises: How “thick” is this application layer? Will LLM labs capture all the value?
The current observation suggests a division of labor: LLM labs tend to graduate “generalist college students”—providing foundational, powerful, general-purpose capabilities. Meanwhile, LLM application developers act as “specialized HR firms” and “project managers.” They organize, fine-tune, and deploy teams of these “generalists” into effective “professionals” for specific verticals by integrating private data, specialized tools, and feedback loops.
4. Claude Code: The AI “Agent” That Lives on Your Computer
If Cursor represents a new application paradigm, then Claude Code defined what a true “LLM agent” looks like and pioneered a new interaction paradigm.
What makes Claude Code groundbreaking?
-
True Agentic Loops: It can string together tool use and reasoning steps in a recursive, looping manner for extended, complex problem-solving. -
A “Local-First” Philosophy: Claude Code runs directly on the developer’s local machine. This contrasts with early attempts that deployed AI agents in cloud containers. While cloud-based agent swarms might sound like the “AGI endgame,” in our current reality of “jagged” capabilities and gradual progress, having an agent with direct, low-latency access to the developer’s local environment, data, configurations, and context is more pragmatic and powerful. -
Paradigm Shift from “Website” to “Resident”: AI is no longer just a website you visit, like Google. Claude Code is like a “spirit” or “ghost” that resides on your computer, familiar with your entire working environment. This persistence, privacy, and deep integration marks the beginning of a new era in human-computer interaction.
5. “Vibe Coding”: When Code Becomes a Free and Disposable Tool of Expression
In 2025, AI crossed a critical capability threshold in programming, giving rise to the phenomenon of “Vibe Coding.” Simply put, it’s describing a software need in plain English and having the AI generate working programs, to the point where the developer can almost “forget the code exists.”
This represents a dual liberation:
-
Liberation for Non-Experts: Programming is no longer the exclusive domain of highly trained professionals. Anyone with an idea can create software through conversation. This represents a historic flip in technology diffusion, empowering regular people to an unprecedented degree. -
Liberation for Professional Developers: Experts can use this to rapidly build a multitude of “disposable” or “exploratory” software tools. For a specific need—like customizing a high-performance Rust tokenizer or prototyping a menu generator—a developer can simply “vibe code” it, without investing significant time learning unfamiliar libraries or writing from scratch. Code becomes free, ephemeral, malleable, and single-use disposable.
The Profound Impact: Vibe coding will profoundly alter the landscape of software development and the job description of developers. It encourages more experimentation, faster prototyping, and frees creativity from the minutiae of syntax.
6. The Dawn of Graphical Interaction: Gemini Nano Banana and the “LLM GUI”
Google’s Gemini Nano Banana model offered a crucial glimpse into the future in 2025: LLM interaction will inevitably evolve from text-dominant “chatting” towards a richer Graphical User Interface.
The underlying logic parallels the history of traditional computing:
-
Early computer users interacted via command-line text instructions. -
The Graphical User Interface was invented because visual and spatial information is humanity’s preferred mode of consumption.
Similarly, while LLMs “favor” text, humans do not enjoy parsing large walls of it. We prefer images, infographics, slides, whiteboard sketches, animations, and even interactive web applications.
Early GUI Precursors: We already use emojis and Markdown to “dress up” text for better readability.
The Key to Future GUIs: The real breakthrough will come from models with joint capabilities in text generation, image generation, and world knowledge. Nano Banana is an early signal of this direction. Future AI will not just answer in text but will directly generate infographics to explain concepts, draw diagrams to clarify processes, or even spin up a simple interactive demo to illustrate functionality.
What does this mean? We are heading toward an era of multimodal AI-driven, more intuitive, and more efficient interaction. Output will no longer be a monotonous text stream but tailored, visual information packages designed for optimal human comprehension.
Conclusion and Outlook
Looking back at 2025, LLM development presents a fascinating paradox: they are simultaneously smarter than we expected (in specific domains) and more “awkward” than we expected (in others). This “jagged intelligence” is intrinsic to their nature as non-biological intelligences.
Despite rapid progress, the industry has likely unlocked less than 10% of the potential of current models. From training paradigms (RLVR) and understanding intelligence (Ghosts vs. Animals) to application layers (Cursor), interaction paradigms (Claude Code), production tools (Vibe Coding), and interfaces (GUI), each direction presents vast, wide-open spaces for innovation.
The road ahead promises continued rapid advancement in capabilities, coupled with the long-term challenge of learning to safely, effectively, and creatively harness this new form of intelligence. The journey has only just begun, and it is one worth watching closely.
Frequently Asked Questions (FAQ)
Q1: Does RLVR improve LLM capabilities beyond math and coding?
A1: RLVR directly optimizes performance in formalizable, verifiable domains (like math, code, logic puzzles). Improvements in these areas can sometimes enhance the model’s structured reasoning abilities, potentially benefiting other tasks requiring similar thinking patterns. However, for tasks heavily reliant on world常识, ambiguous context, or complex ethical judgment, RLVR’s direct contribution may be limited, requiring other training data and methods.
Q2: Does “Jagged Intelligence” mean LLMs are unreliable?
A2: Not unreliable, but requiring smarter usage. The key is “knowing their strengths and weaknesses.” In their areas of expertise—verifiable domains like code generation, data cleaning, knowledge Q&A—they can be exceptionally reliable and powerful. However, in areas requiring deep understanding, creative breakthroughs, or safety/ethical considerations, human oversight and final judgment remain essential. The right approach is to leverage their “spikes” while implementing processes and guardrails to mitigate their “valleys.”
Q3: Will applications like Cursor be replaced by products from the major LLM labs themselves?
A3: This depends on competitive dynamics. Core LLM labs excel at foundational model research. Vertical application developers excel at deep understanding of specific industry workflows, accumulation of private data, and refined human-AI interaction design. A more likely landscape is one of specialization and collaboration: labs provide powerful “foundation model engines,” and app developers build focused, user-friendly “vehicles” on top. The relationship will involve both competition and a broad cooperative ecosystem.
Q4: Which is the future: locally-run AI agents (like Claude Code) or cloud-based agents?
A4: Both will likely coexist, serving different scenarios. Local Agents excel in low latency, data privacy, and deep integration with existing personal/work environments. They are ideal for individual or small-team tasks demanding immediacy, privacy, and personalization. Cloud Agent Swarms excel in unlimited compute scaling, easy collaboration/sharing, and managing complex workflows. They suit large projects or tasks requiring massive resources. In the near term, “local-first” agents may see faster adoption due to superior user experience and privacy assurances.
Q5: Will “Vibe Coding” make programmers obsolete?
A5: A more accurate description is that “the nature of programmers’ work will transform.” Junior-level, repetitive coding tasks will diminish significantly. However, skills in architecting complex systems, reviewing and integrating AI-generated code, translating vague requirements into precise AI instructions (i.e., “prompt engineering” or “AI coordination”), and solving novel problems that AI still struggles with will become more critical than ever. Programmers will shift from being “code typists” toward becoming “AI-augmented solution architects” and “technical tuners.”

