

Building Effective Tools for LLM Agents: A Practical Guide
If you’ve ever worked with AI systems, you know that large language model (LLM) agents can handle a wide range of tasks, from scheduling meetings to analyzing data logs. But to make them truly useful in real-world scenarios, they need the right tools. These aren’t your standard software functions—they’re designed to work with the unpredictable nature of agents. In this post, I’ll walk you through how to create and refine these tools step by step, based on proven techniques that boost performance.
Think of it this way: traditional software is like a reliable machine that always does the same thing with the same input. Agents, on the other hand, might take different paths to solve a problem, sometimes succeeding brilliantly and other times getting stuck. Tools bridge that gap, helping agents tackle complex jobs more reliably. The key is making tools that feel natural for agents to use, which often means they’re straightforward for people too.
Understanding Tools in the Context of LLM Agents
You might be wondering, what exactly is a tool in this setup? It’s a piece of software that connects predictable systems—like databases or APIs—with the flexible thinking of an agent. For example, if someone asks, “Do I need an umbrella today?” an agent could call a weather tool, recall general knowledge, or ask for your location first. But agents aren’t perfect; they can misinterpret tools or even imagine details that aren’t there.
This is why designing tools requires a shift in mindset. Instead of building them like APIs for other programs, we create them for agents that think like humans but have limits, such as how much information they can process at once. The goal is to expand what agents can do effectively, allowing them to try various approaches to a task.
From experience, the most helpful tools are those that agents find easy to work with—ergonomic, as we call it. Surprisingly, these often turn out to be intuitive for humans as well.
Step-by-Step Process for Creating Tools
Getting started can feel overwhelming, but breaking it down makes it manageable. We’ll cover building a prototype, setting up evaluations, and working with agents to improve things. This iterative approach ensures your tools get better over time.
Starting with a Prototype
How do you begin? It’s hard to predict what will work without trying it out. So, start small: build a quick version of your tools and test them.
If you’re using something like Claude Code to help write the tools, provide it with relevant documentation. This could include guides for libraries, APIs, or SDKs you’re using, often available in simple formats like llms.txt files.
Next, wrap your tools in a local setup, such as an MCP server or a Desktop extension. This lets you connect and experiment in environments like Claude Code or the Claude Desktop app.
Here’s how to connect:
-
For Claude Code, use the command:
claude mcp add <name> <command> [args...]. -
In the Claude Desktop app, go to Settings > Developer for MCP servers or Settings > Extensions for Desktop extensions.
You can also feed tools directly into API calls for automated testing.
Once set up, test the tools yourself. Look for any issues, like confusing inputs or unexpected outputs. Gather input from users to understand the kinds of problems they want to solve. This builds your sense of what makes a tool effective.

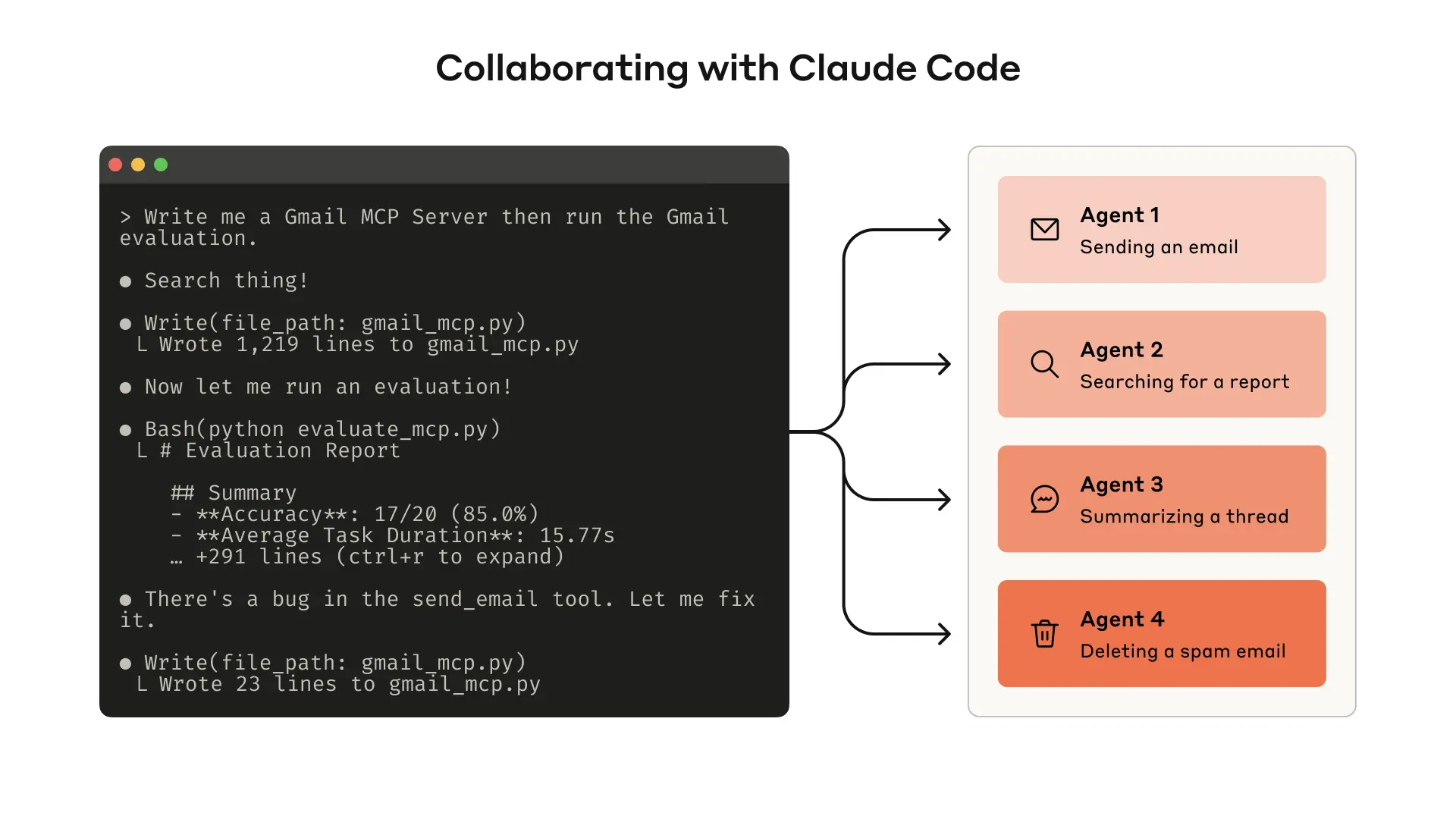
Creating an evaluation setup helps measure how well your tools perform. Tools like Claude Code can then automatically refine them based on those measurements.
Setting Up a Comprehensive Evaluation
With a prototype ready, the next question is: How well does it actually work? You need a solid way to test how agents use your tools. This involves creating tasks, running tests, and analyzing results.
First, generate evaluation tasks rooted in everyday uses. Use real data from services like internal databases or workflows. Avoid simple test environments that don’t challenge the tools enough. Good tasks often require several tool calls, maybe even dozens.
Examples of strong tasks:
-
Arrange a meeting with Jane next week to talk about the latest Acme Corp project. Include notes from the last planning session and book a room.
-
A customer with ID 9182 says they were charged three times for one purchase. Locate related logs and check if others had the same problem.
-
Sarah Chen, a customer, wants to cancel. Put together a retention plan: Figure out why she’s leaving, what offer might keep her, and any risks to consider.
Weaker tasks to avoid (they’re too basic):
-
Set up a meeting with jane@acme.corp next week.
-
Look in payment logs for ‘purchase_complete’ and customer_id=9182.
-
Find the cancellation for customer ID 45892.
Pair each task with a checkable answer. This could be a direct match of text or using an agent to judge quality. Don’t make the checker too picky—it might reject good answers over minor differences like spacing.
You can note expected tool uses, but don’t lock in one way; agents might find valid alternatives.
To run the evaluation, use a simple loop in code: Alternate between calling the LLM API and your tools for each task. Give the agent just the task and your tools.
In the agent’s instructions, have it output thinking steps and feedback first, then actions. This encourages better reasoning.
If using Claude, enable interleaved thinking to see inside the agent’s process, revealing why it chooses certain tools.
Track more than just success rates: Note time per call, number of calls, token use, and errors. This highlights patterns, like frequent sequences that could be combined into one tool.
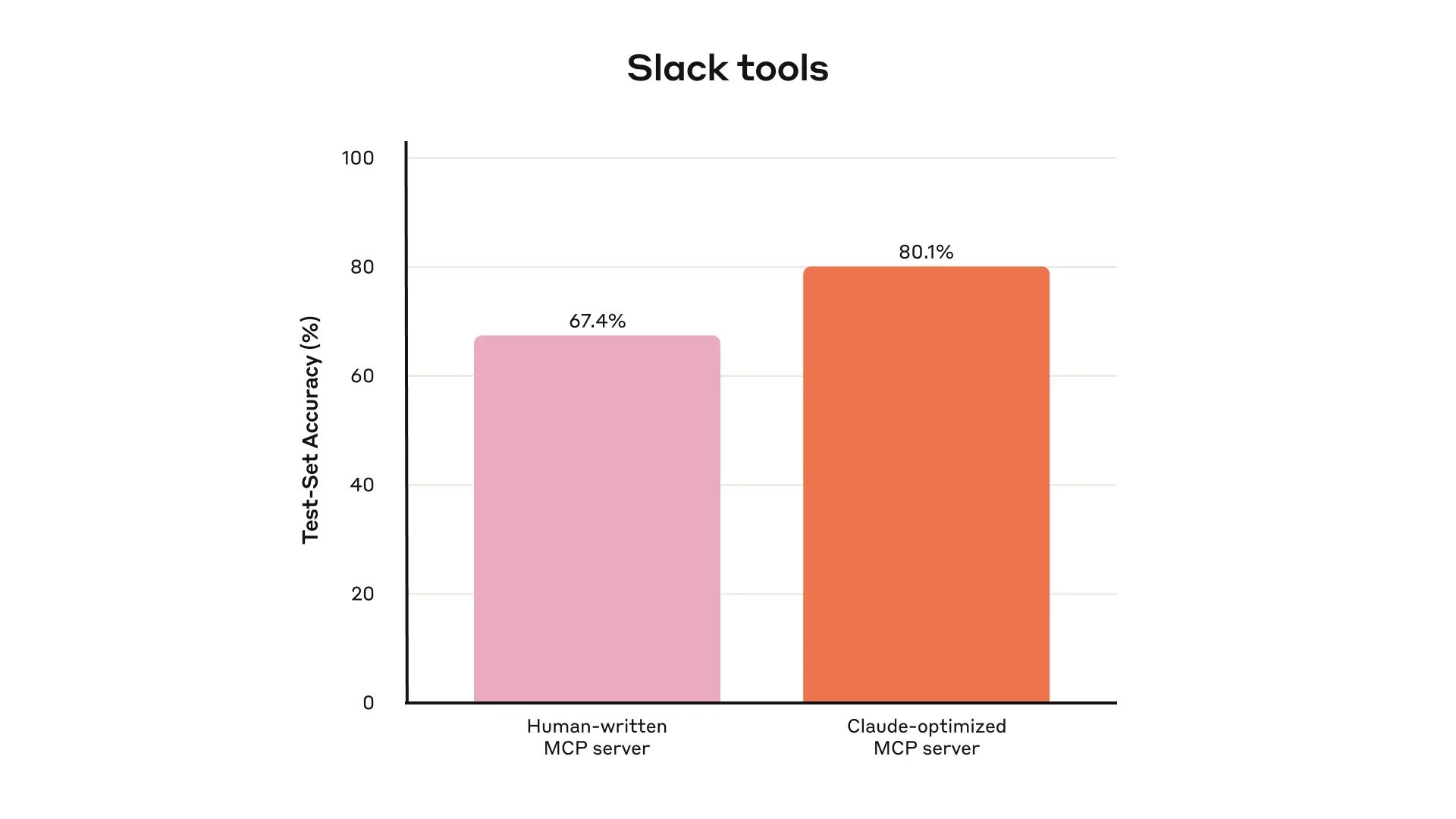
This shows performance on held-out tests for internal Slack tools.
For analysis, agents can help spot problems, like mismatched descriptions or slow implementations. But watch for what they don’t say—sometimes that’s the clue.
Look where agents struggle. Read their reasoning to find pain points. Examine full logs of calls and responses. Metrics can show needs, like better paging if calls are repetitive or clearer guides if parameters often fail.
In one case, with a web search tool, the agent kept adding ‘2025’ to queries, skewing results. Fixing the description solved it.
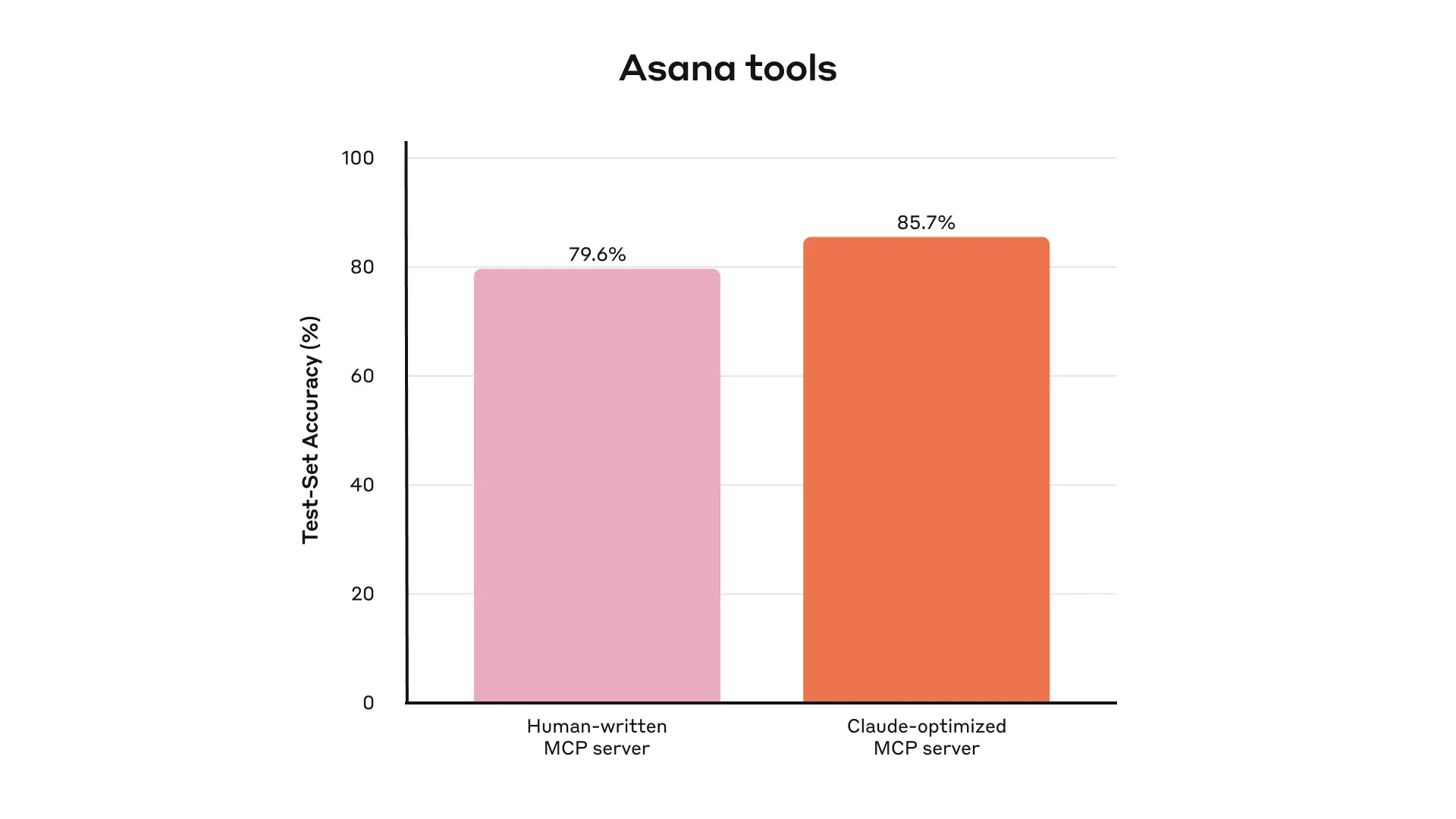
This is for internal Asana tools on held-out tests.
Working Alongside Agents for Improvements
Agents aren’t just users—they can analyze your tests and suggest fixes. Copy evaluation logs into something like Claude Code. It excels at reviewing them and updating tools, keeping everything consistent.
Much of what we’ve learned came from this loop with internal tools. Our tests mirrored real work, with actual projects and communications.
We used separate test sets to prevent overfitting. Results showed agents could outperform even expert-written tools.
Core Principles for High-Quality Tools
Through this process, several key ideas stand out for making tools that work well.
Selecting the Best Tools to Build (and Skip)
Is more always better? Not with tools. A mistake is wrapping every function without thinking if it fits agents.
Agents have limited space for info, unlike endless computer memory. For searching contacts, listing all is wasteful as the agent scans everything. Better to search directly for what’s needed.
Focus on a few tools for key workflows that match your tests, then grow from there.
Tools can bundle steps: Handle multiple actions inside one call, adding useful details.
Examples:
-
Rather than separate lists for users and events plus creation, make a schedule_event that checks availability and books.
-
Instead of reading all logs, have search_logs return just matches with context.
-
Combine customer info fetches into get_customer_context for a full recent summary.
Each tool needs a clear role, helping agents break down tasks like a person would, while saving space on extras.
Overlaps confuse agents. Thoughtful choices pay off.
Organizing Tools with Namespaces
With potentially hundreds of tools from various sources, clarity matters. Similar functions can lead to wrong choices.
Group them with prefixes, like by service (asana_search, jira_search) or type (asana_projects_search, asana_users_search). This sets boundaries.
Naming style—prefix or suffix—affects results, varying by model. Test yours.
This cuts down on loaded info and shifts work to calls, reducing errors.
Providing Useful Context in Tool Outputs
Tools should return only what’s relevant. Focus on meaning over options, using friendly terms like name or image_url, not tech IDs like uuid or mime_type.
Agents handle everyday words better than codes. Swapping IDs for descriptive labels cuts errors in finding things.
Sometimes both are needed: Add a response_format option, like ‘detailed’ or ‘concise’.
Example enum:
enum ResponseFormat {
DETAILED = "detailed",
CONCISE = "concise"
}
Detailed example (206 tokens):

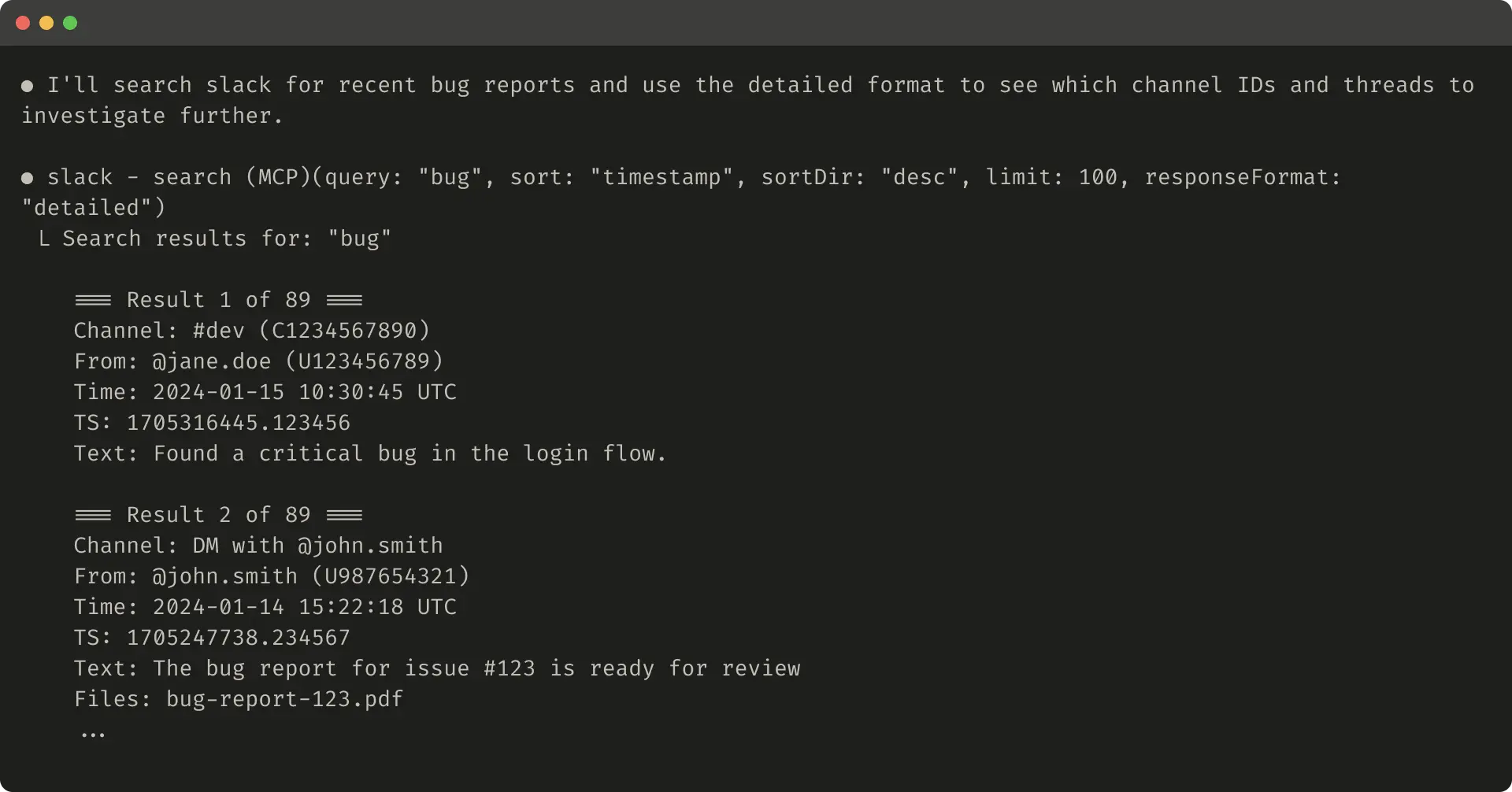
Concise example (72 tokens):

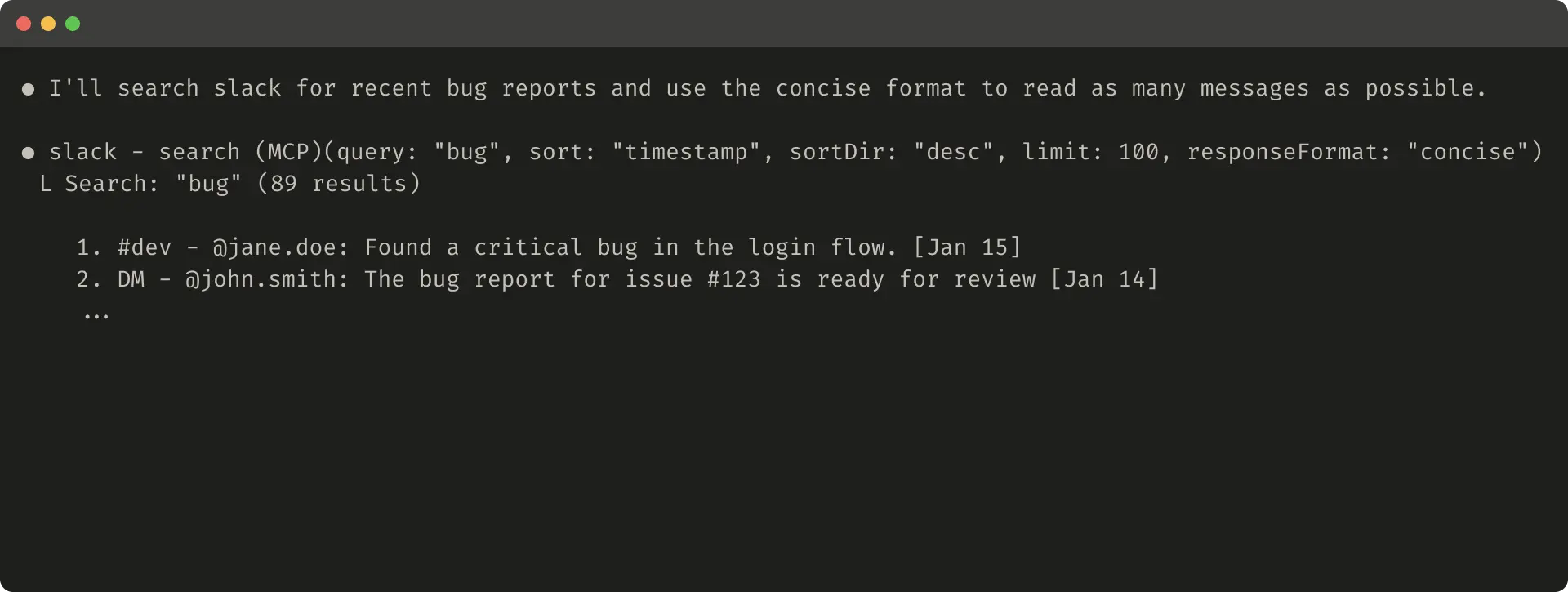
For Slack, detailed includes IDs for further actions; concise saves space with content only.
Output format—like JSON or Markdown—impacts success. It ties to model training. Choose based on tests.
Making Tool Outputs Efficient on Resources
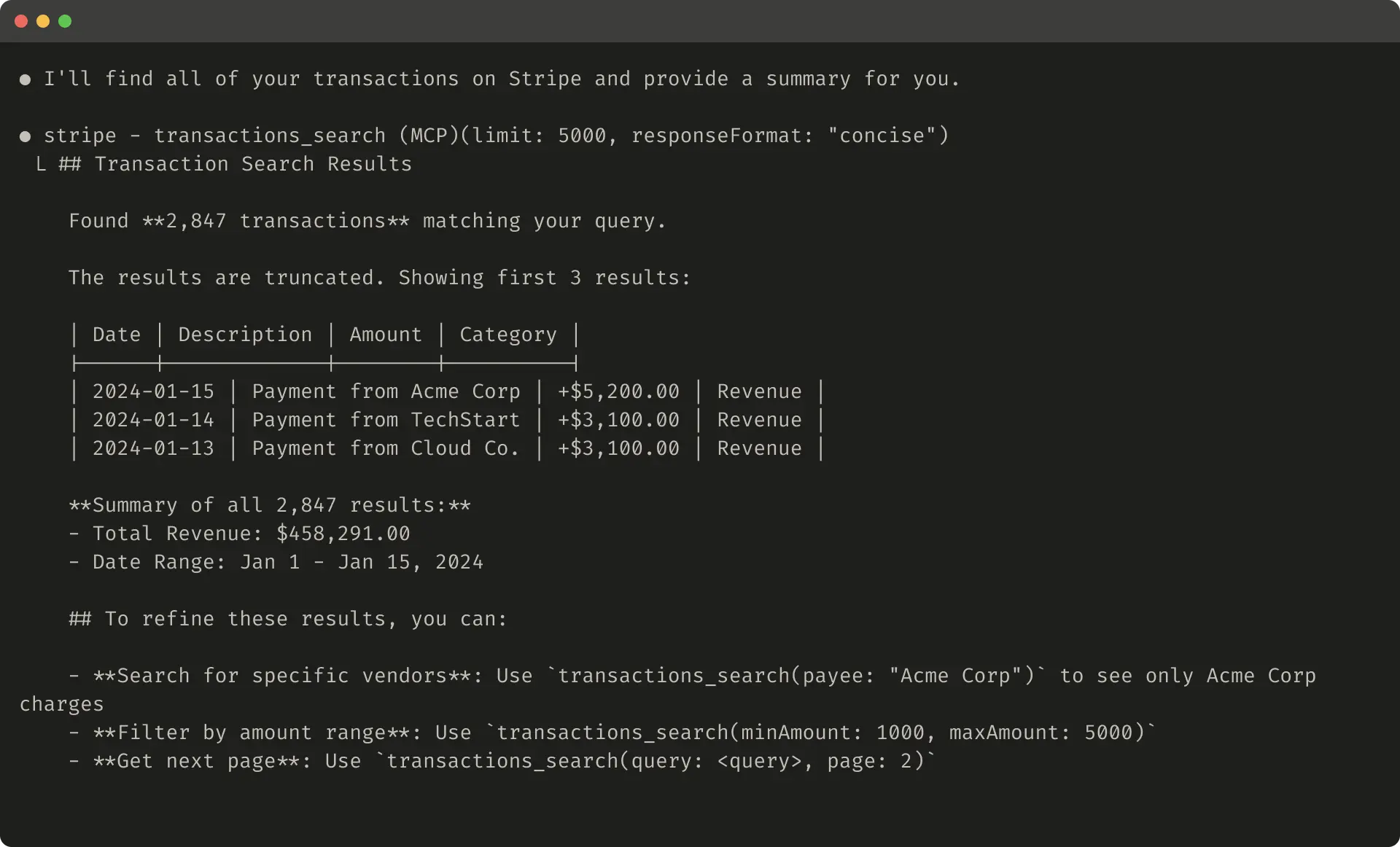
Quality matters, but so does size. Large outputs eat up agent capacity.
Add features like paging, filters, or cuts with smart defaults. Limit to 25,000 tokens or so initially.
Guide agents in truncations: Suggest targeted calls over broad ones.
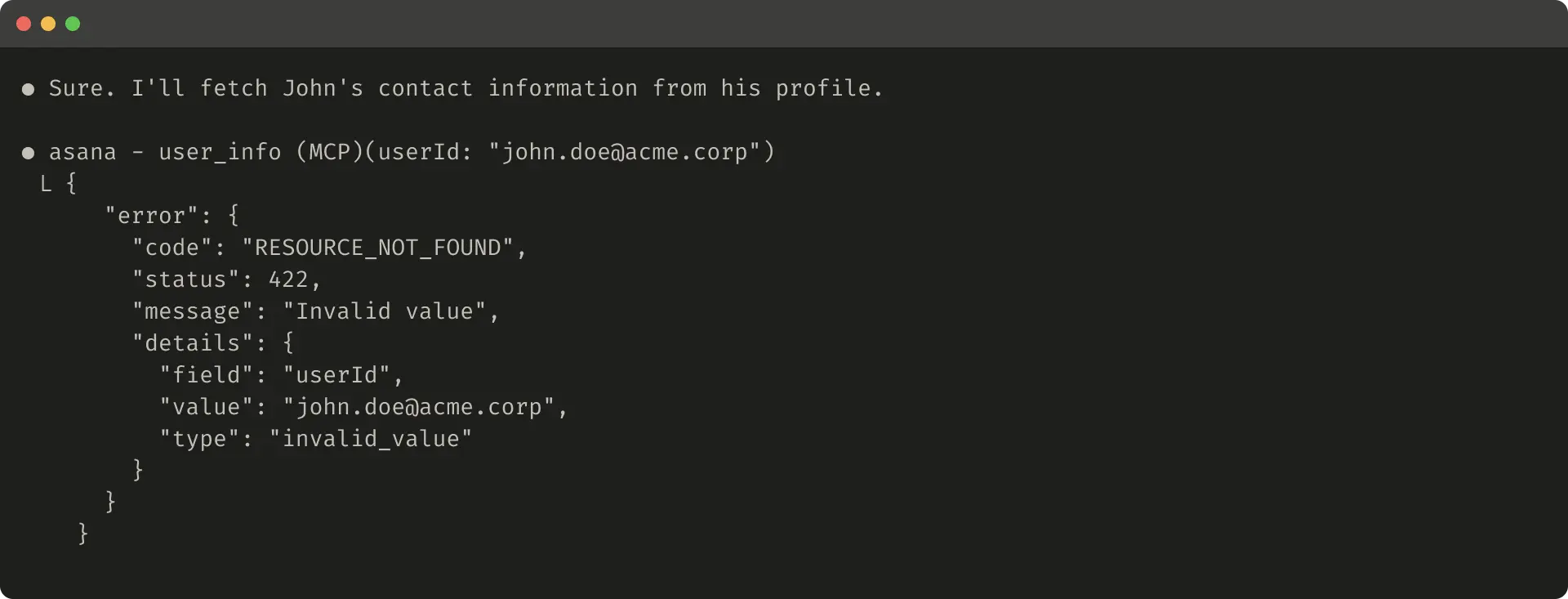
For errors, give clear fixes, not just codes.
Truncated example:

Unhelpful error:

Helpful error:

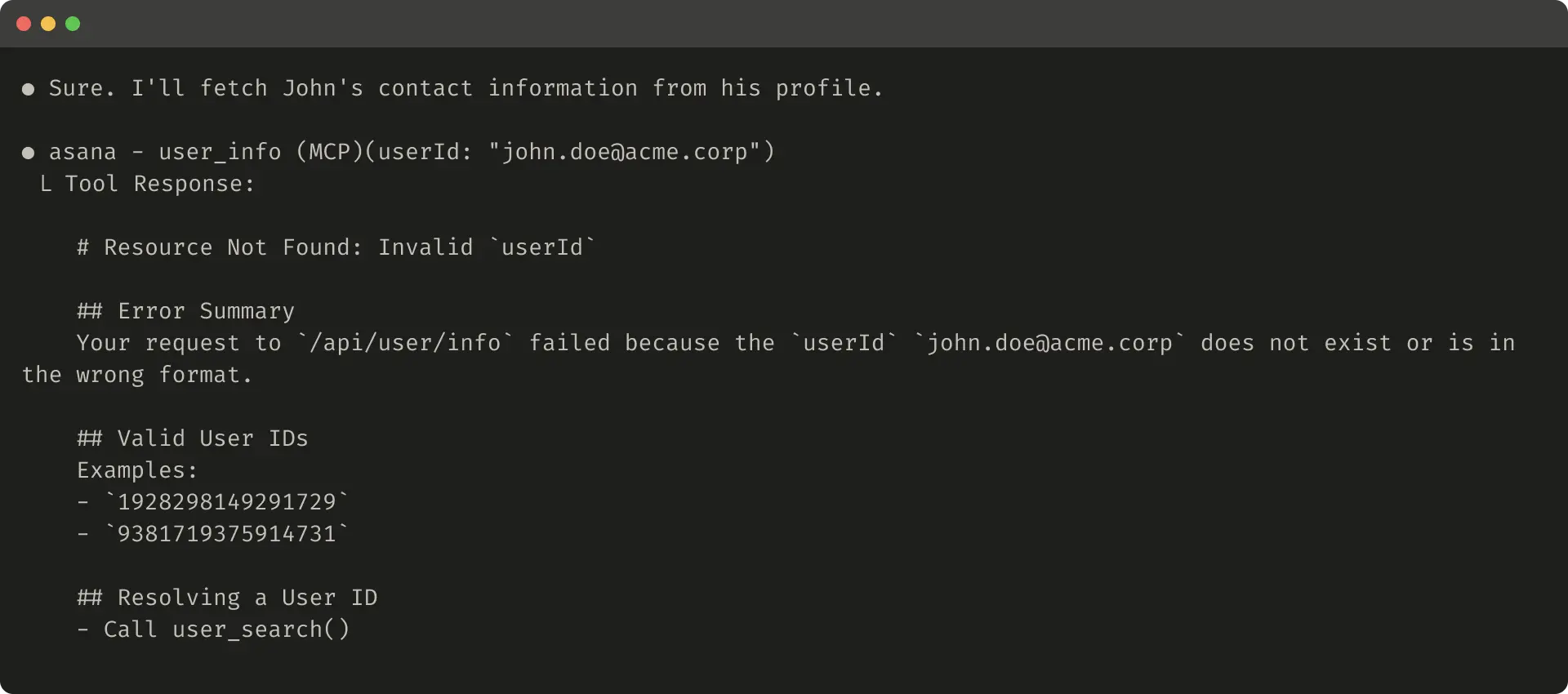
These steer toward better habits.
Refining Tool Descriptions with Prompts
One top way to improve: Tune descriptions and specs. They’re part of the agent’s input, shaping choices.
Describe like explaining to a new team member: Spell out formats, terms, connections. Be clear on inputs/outputs with firm structures. Name params well, e.g., user_id not user.
Tests show small changes boost results a lot. Precise tweaks helped achieve top scores on benchmarks by cutting errors.
Look for best practices in guides. Tools load into prompts dynamically. Note if tools access open data or change things.
Looking Forward: Evolving Tools with Agents
Designing for agents means moving from fixed patterns to flexible ones.
Effective tools are clear, use space wisely, combine well, and solve real problems intuitively.
As tech advances—like protocol updates or better models—keep evaluating to adapt tools.


How-To Guides for Common Tasks
How to Generate Evaluation Tasks
-
Use Claude Code to explore tools and make prompt-answer pairs.
-
Base on real scenarios with complexity.
-
Include verifiable answers without forcing one path.
How to Analyze Evaluation Results
-
Get agent feedback on issues.
-
Spot stuck points in reasoning.
-
Check logs and metrics for adjustments.
How to Control Output Formats
Use enums like ResponseFormat to let agents pick detail levels, balancing needs and efficiency.
Frequently Asked Questions
What’s the difference between tools for agents and regular APIs?
APIs are for predictable interactions; tools handle agent variability, where calls might not always happen or could go wrong.
Why aren’t more tools always an improvement?
Extra tools can confuse strategies and waste space. Start focused.
How can I prevent tool outputs from overwhelming agents?
Implement limits like filters or paging, and guide with instructions.
What role does namespacing play in tool selection?
It groups functions clearly, helping agents pick correctly without mix-ups.
How do I optimize tool descriptions?
Explain thoroughly, like to a newcomer, and test changes.
Can agents help refine tools?
Yes, feed them logs for analysis and updates.
What metrics should I track in evaluations?
Success, time, calls, resource use, errors.
Does output structure affect performance?
Yes, match model preferences through testing.
How will tool design change in the future?
Principles stay, but adapt to new tech for ongoing effectiveness.
This approach turns good ideas into working solutions. Keep iterating—prototype, test, refine—and your agents will handle more with less hassle. (Word count: approximately 3,250)

