The Latest Breakthrough from Alibaba’s Tongyi Lab
Introduction: Revolutionizing Efficiency in 3D Avatar Technology
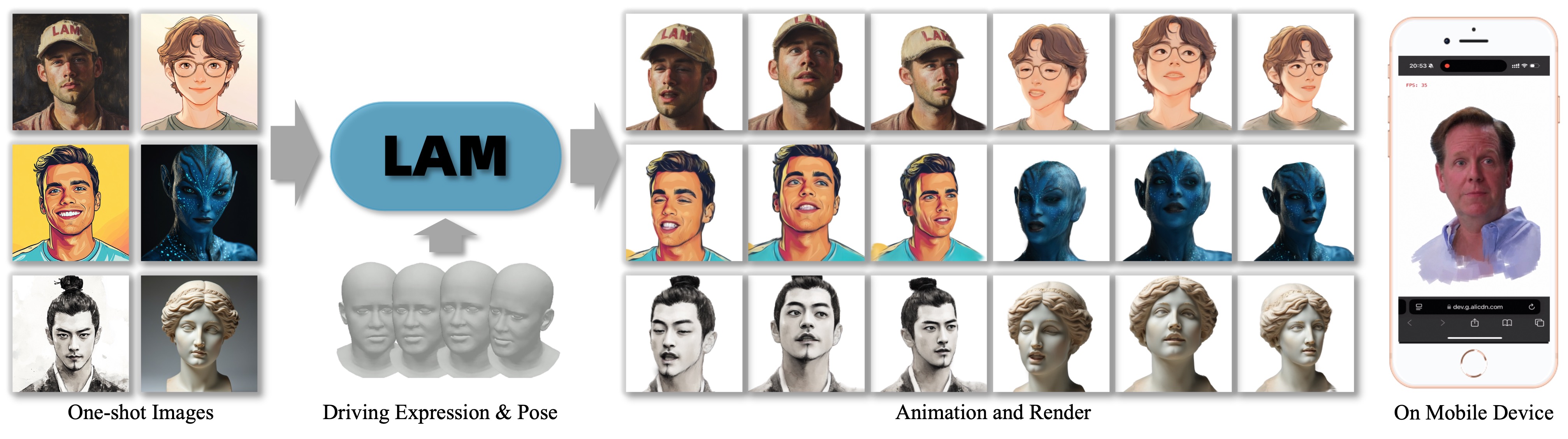
In fields such as virtual livestreaming, metaverse social interactions, and game character design, 3D avatar creation has long faced two major challenges: high costs and low efficiency. Traditional methods require multi-angle video capture or complex neural network training, consuming hours or even days. Alibaba’s Tongyi Lab recently unveiled LAM (Large Avatar Model), a technology that generates real-time animatable 3D Gaussian heads from a single image in just 1.4 seconds, elevating industry productivity to unprecedented levels.
This article provides a comprehensive analysis of this groundbreaking innovation, covering its technical principles, practical applications, and industry impact.
I. Core Technical Principles of LAM
1. Limitations of Traditional Methods
Video-Driven Approaches
Reliant on multi-angle video input and 3D reconstruction via optical flow or structured light scanning. Key drawbacks include:
-
High equipment costs (professional camera arrays required) -
Lengthy data processing (hours per model generation)
Neural Network-Assisted Approaches
Use GANs or NeRF for model generation, requiring additional networks to predict animation parameters. Issues include:
-
Rendering latency (GPU-dependent real-time computation) -
Poor cross-platform compatibility (difficult to deploy on mobile devices)
2. LAM’s Innovative Design
LAM adopts a single-image input + one-pass forward computation architecture, with a two-step core workflow:
(1) Canonical Space Modeling
-
FLAME Standard Template: Integrates the FLAME head model (a “3D facial skeleton”) with 52 expression bases and predefined topological structures. -
Multi-Scale Feature Fusion: Uses a Transformer to interact image features with FLAME canonical points, directly predicting Gaussian attributes (position, color, transparency, etc.).
(2) Real-Time Animation and Rendering
-
Linear Blend Skinning (LBS): Drives Gaussian model deformation by blending FLAME expression weights, enabling fine-grained animations like blinking and smiling. -
Cross-Platform Rasterization: Gaussian representations natively support rasterization renderers, enabling real-time operation on WebGL, mobile devices, and chat applications.
Performance Metrics:
-
Model generation time: 1.4 seconds -
Rendering FPS: 562.9 FPS on NVIDIA A100 GPUs, 110+ FPS on Xiaomi 14 smartphones
II. Three Key Technical Advantages of LAM
1. Detail Reconstruction Capability
Traditional methods struggle with high-frequency details like hair strands or transparent glasses. LAM achieves precision through multi-scale image feature sampling, accurately reconstructing complex structures such as split ends and lens reflections.
2. Full Platform Compatibility
-
No Adaptation Required: Generated Gaussian models export directly to universal formats (e.g., PLY, OBJ), compatible with Unity, Unreal Engine, and other mainstream engines. -
Low Computational Demand: Mobile devices only require OpenGL ES 3.0 support, enabling smooth operation on budget smartphones.
3. Editing Flexibility
Users can edit source images in Photoshop (e.g., modifying hairstyles or makeup), and LAM automatically maps 2D edits to 3D models without retraining.
III. Practical Applications of LAM
1. Virtual Livestreaming and Real-Time Interaction
-
Low-Latency Avatars: Integrated with the OpenAvatarChat SDK for voice-driven lip-sync (latency <200ms). -
Enterprise Solutions: Generate customer service or virtual instructor avatars directly via smartphone cameras.
2. Game and Film Production
-
Rapid Prototyping: Upload concept art to generate engine-ready 3D models in 1 second. -
Facial Animation Libraries: Export FBX animation sequences for direct use in Unity or Maya.
3. Cultural Heritage Preservation
-
Single-Image Digitization: Create interactive 3D models from photographs of ancient murals or sculptures. -
Virtual Restoration: Reconstruct complete 3D structures from images of damaged artifacts.
IV. LAM vs. Competing Technologies
| Metric | Traditional NeRF | Neural Network Methods | LAM |
|---|---|---|---|
| Single Model Gen Time | 2–6 hours | 30 mins–2 hours | 1.4 seconds |
| Mobile Rendering FPS | Not Supported | <30 FPS | 110+ FPS |
| Cross-Platform Support | Format Conversion | Renderer-Dependent | Out-of-the-Box |
| Edit Cost | Retraining Needed | Parameter Tuning | Edit Source Image |
V. Future Development Roadmap
1. Model Enhancements
-
LAM-Large: A high-precision version trained on million-scale datasets (Q4 2025 release). -
Audio-Driven Expansion: Integrate Audio2Expression for end-to-end voice-to-animation generation.
2. Developer Ecosystem
-
Open-Source SDK: Provide C++/Python APIs for custom expression bases and rendering pipelines. -
Cloud API Service: Deploy via Alibaba Cloud with pay-per-use pricing (planned 2026 launch).
VI. How to Experience LAM
1. Online Demos
2. Local Deployment Guide
# Installation (CUDA 12.1)
git clone git@github.com:aigc3d/LAM.git
cd LAM
sh ./scripts/install/install_cu121.sh
3. Model Downloads
| Model Version | Training Data | Download Links |
|---|---|---|
| LAM-20K | VFHQ + NeRSemble | HuggingFace |
| Pre-trained Assets | FLAME Models & Textures | OSS Direct Link |
Conclusion: Democratizing Technology and Industry Transformation
LAM’s value lies not only in its technical superiority but also in its open-source ecosystem. Developers can integrate it rapidly via the GitHub repository, while individual users experiment freely on HuggingFace Spaces. This philosophy of “lowering creative barriers” may mark a pivotal shift in 3D content production—from professional studios to mainstream accessibility.
