

Kimi K2.5 Release: The Open-Source Visual Agentic Intelligence Revolution
This article addresses the core question: What substantive technical breakthroughs does Kimi K2.5 introduce over its predecessor, and how do its visual understanding, coding capabilities, and new Agent Swarm paradigm alter the landscape of complex task solving?
Moonshot AI has officially released Kimi K2.5, marking not just an iterative update but a fundamental reshaping of architectural and capability boundaries. As the most powerful open-source model to date, Kimi K2.5 builds upon the foundation of Kimi K2 through continued pre-training on approximately 15 trillion mixed visual and text tokens. This release establishes its leadership in coding and vision domains, most notably by introducing the Agent Swarm (intelligent swarm) paradigm—a significant leap from single-agent intelligence to group-based collaborative intelligence.
Model Architecture: A Foundation of Trillion-Parameter Native Multimodal Design
This section addresses the core question: How is Kimi K2.5’s underlying architecture designed to support such robust multimodal and long-context capabilities?
Kimi K2.5 employs a highly efficient Mixture of Experts (MoE) architecture. The total parameter count reaches a staggering 1T (trillion), yet during actual inference, only about 32B parameters are activated per token. This design ensures the model possesses a deep knowledge base while drastically reducing inference costs, making large-scale application feasible.
Specifically, the model network comprises 61 layers and utilizes 384 experts. For each input token, the model dynamically selects 8 experts for processing, assisted by 1 shared expert. The attention mechanism features a hidden size of 7168 and is equipped with 64 attention heads. To handle ultra-long texts and complex tool-calling traces, the model supports a maximum context length of 256K tokens, allowing it to easily accommodate long spec documents, extensive codebase histories, and multi-step research workflows.
In terms of visual processing, Kimi K2.5 introduces a vision encoder called MoonViT, with approximately 400 million parameters. Unlike traditional “vision-language” stitching, K2.5 trains visual tokens and text tokens together within a single multimodal backbone. This native multimodal training means the model masters the joint structure of images, documents, and language from the very beginning, rather than learning it as an afterthought.
Reflection / Technical Insight
From an architectural perspective, K2.5’s MoE configuration (384 experts selecting 8 + 1 shared) represents an engineering balance. It avoids the massive computational overhead of fully activated models while ensuring knowledge density through a high total expert count. More importantly, embedding visual capabilities directly into the backbone training, rather than treating them as an external plugin, explains why it performs so naturally on cross-modal tasks like “video-to-code”—in its internal representation, images and code essentially belong to the same language.
Key Architecture Parameters at a Glance
| Parameter Item | Value/Config | Significance |
|---|---|---|
| Total Parameters | 1T | Scale of the model’s knowledge base |
| Activated Parameters | ~32B per token | Actual computational load during inference |
| Layers | 61 | Depth and complexity of the model |
| Expert Config | 384 experts (8 active + 1 shared) | Efficient sparse activation mechanism |
| Context Length | 256K tokens | Support for long documents and long conversations |
| Vision Encoder | MoonViT (~400M params) | Core of native multimodal understanding |
Image Source: Marktechpost (Example Architecture Diagram)

Agent Swarm: From Serial Execution to Parallel Intelligent Swarms
This section addresses the core question: How does Agent Swarm solve complex tasks through a parallel multi-agent architecture and improve execution efficiency?
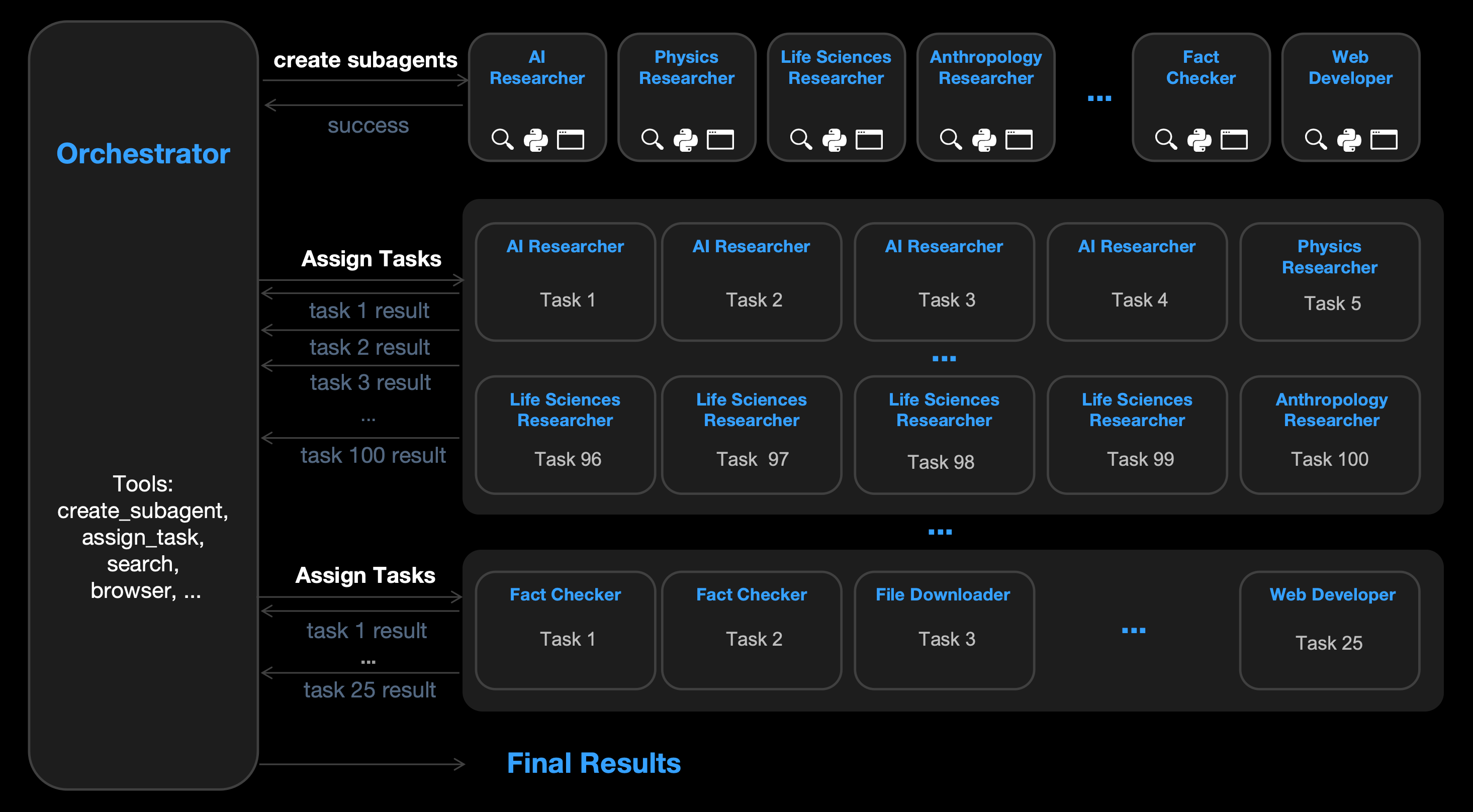
The most significant innovation in Kimi K2.5 is the launch of the Agent Swarm mode. Traditional AI agents often work in isolation, processing steps serially when facing complex tasks, which is time-consuming and prone to bottlenecks. K2.5 introduces Parallel-Agent Reinforcement Learning (PARL), training a self-directing “orchestrator agent.”
This orchestrator can automatically decompose complex macro goals into parallelizable subtasks and dynamically instantiate up to 100 sub-agents to work simultaneously. In a single task workflow, the system can coordinate up to 1,500 steps of tool calls.
The efficiency gains from this parallelization are astounding. Compared to a single-agent setup, Kimi K2.5’s Agent Swarm can reduce execution time by 4.5x.
Solving “Serial Collapse” and Training Challenges
Training a reliable parallel orchestrator is not easy. Feedback from sub-agents is often delayed, sparse, and the environment is non-stationary. Models are prone to “serial collapse,” where, despite having parallel capacity, the orchestrator defaults to single-threaded execution for safety.
To address this, PARL employs staged reward shaping. Early in training, the system provides an auxiliary reward rparallel specifically to encourage the instantiation and concurrent execution of sub-agents, thereby exploring the parallel scheduling space. As training progresses, the optimization focus gradually shifts to end-to-end task quality, preventing degenerate solutions where parallelism exists in name only.
Furthermore, the team introduced a metric called Critical Steps to measure performance. Inspired by the “critical path” in parallel computing, this metric calculates the total time of all serially dependent steps, rather than just the total step count. The system only receives a high score if concurrency actually shortens the critical path.
Real-World Case Study: Finding Top Creators Across 100 Niches
A typical application scenario: A task requires identifying top YouTube creators across 100 different niche domains (e.g., “Retro Game Restoration,” “Quantum Physics Pop-science”).
K2.5 Agent Swarm first researches and defines the boundaries of these 100 domains. Automatically creates 100 sub-agents, each responsible for a deep search in one domain. Each sub-agent works in parallel, mining information in their respective corners of the web, before results are aggregated.
This process would take an extremely long time if done by a single agent searching one by one; in Swarm mode, it happens almost instantly.

Vision and Coding Fusion: Breaking Development Boundaries
This section addresses the core question: How does Kimi K2.5 revolutionize coding workflows using visual understanding, enabling developers to generate code via images or video?
Kimi K2.5 is one of the most powerful open-source coding models available today, particularly in frontend development. Its core strength lies in “Vision-Coding”—utilizing visual input to assist code generation.
From Conversation to Complete Interfaces
K2.5 can transform simple natural language conversations directly into complete frontend interfaces, including interactive layouts and rich animation effects (such as scroll-triggered effects). More importantly, it is not limited to text instructions; it can directly read UI design mockups, screenshots, or even demo videos.
Video-to-Code is a use case with immense potential. By reasoning over the interaction logic and visual styles in a video, K2.5 can reconstruct the corresponding web or app code. This allows product managers and designers to generate prototypes by simply recording a demo video, drastically lowering communication costs.
Complex Visual Reasoning and Code Generation
Kimi K2.5 doesn’t just do interfaces; it can solve algorithmic problems. A fascinating case documented shows K2.5 solving a maze puzzle by visually recognizing the image and writing an algorithm to find the shortest path.
Task Description: Navigate from the top-left corner (green dot) to the bottom-right corner (red dot) in a complex maze image, where black represents the path.
Execution Process:
-
Image Analysis: The model first identifies the image structure, locating the start (approximate position) and end points. -
Algorithmic Planning: It identifies this as a typical graph theory problem suitable for the BFS (Breadth-First Search) or A* algorithm. -
Code Writing & Execution: It writes Python code using the OpenCV library to load the image, binarize the maze, and extract pixel coordinates. -
Result Verification: The model calculates the start point as (7, 3) and the end point as (1495, 2999), finding a shortest path of 113,557 steps. -
Visual Feedback: It generates a result image, marking the path’s progression with a color gradient.
This case demonstrates K2.5’s powerful ability in “image-to-code,” going beyond pixel-level recognition to include spatial logic reasoning and algorithm implementation.

Image Source: Moonshot AI Blog

Reflection / Developer Perspective
For developers, K2.5’s “Vision-Coding” is not just an efficiency tool but a new interaction paradigm. Previously, we needed to use natural language to describe extremely precisely “make the button on the left slightly bigger.” Now, simply uploading a design mockup or a screen recording allows the model to understand your intent. More importantly, it can perform “Visual Debugging”—looking at a UI screenshot to write code that fixes bugs—solving the pain point of intent expression for non-technical users.
Autonomous Visual Debugging: Generating a Matisse-Style Webpage
Another impressive application is Autonomous Visual Debugging. K2.5 can read Matisse’s famous painting La Danse and, referencing Kimi App’s documentation, autonomously iterate to generate an art-styled webpage.
In this process, the model doesn’t just generate code once. It uses visual inputs (inspecting the generated webpage effect) and documentation queries to continuously self-correct the code until the generated page visually meets expectations. This closed-loop “Generate-Observe-Correct” workflow is a key step towards truly autonomous programming.
Office Productivity: Handling Real-World Knowledge Work
This section addresses the core question: What specific landing capabilities does Kimi K2.5 possess when facing high-density real-world office scenarios?
Beyond hardcore coding and algorithmic tasks, Kimi K2.5 demonstrates powerful Agentic Intelligence in the daily office domain. It can handle high-density, large-scale office tasks, end-to-end generating Word documents, Excel spreadsheets, PDF reports, and PowerPoint presentations.
Advanced Document and Data Processing Capabilities
Kimi K2.5’s Agent mode supports adding annotations in Word, building complex financial models with Pivot Tables in Excel, and writing LaTeX equations in PDFs. It can also handle long-form content, such as generating 10,000-word papers or 100-page technical documents.
In internal evaluations, the team designed the AI Office Benchmark and General Agent Benchmark. Results show that K2.5’s performance on these benchmarks improved by 59.3% and 24.3%, respectively, compared to the K2 Thinking model. This reflects a qualitative leap in the model’s integration capabilities within real-world workflows.
Practical Application Examples
Spreadsheet Generation: It can generate a 100-shot storyboard with images in Excel based solely on a prompt.
Document Automation: Based on a vague requirement description, it can automatically generate a structured industry analysis report complete with data charts.
These capabilities mean that work that used to take professional analysts or assistants hours or even days can now be completed in minutes by Kimi K2.5 with expert-level quality.
Image Source: Moonshot AI Blog (Internal Productivity Benchmark Results)

Benchmark Performance
This section addresses the core question: How does Kimi K2.5’s performance compare to other top-tier models in objective benchmarks?
Kimi K2.5 has delivered an impressive report card across multiple authoritative benchmarks, showing extremely strong competitiveness in agent search, multimodal understanding, and coding capabilities.
Agent and Search Capabilities
In the agent domain, Kimi K2.5 excels thanks to tool-calling and long context advantages:
-
HLE-Full (with tools): 50.2, significantly outperforming most closed-source models. -
BrowseComp (with context mgm): 74.9, demonstrating extreme strength in web browsing and information retrieval. With Agent Swarm mode enabled, the score further increases to 78.4. -
DeepSearchQA: 77.1, performing excellently on deep search problems.
Multimodal and Video Understanding
Benefiting from the MoonViT encoder and large-scale joint pre-training, K2.5 stands out in vision and video tasks:
-
MMMU-Pro: 78.5, a highly challenging multimodal reasoning benchmark. -
VideoMMMU: 86.6, ranking at the industry forefront in video understanding. -
OmniDocBench 1.5: 88.8, proving high-precision understanding of complex documents.
Coding Capabilities
As a strong open-source coding contender, K2.5 ranks among the top in several coding tests:
-
SWE-Bench Verified: 76.8, a hardcore metric measuring real GitHub issue resolution. -
SWE-Bench Multilingual: 73.0, demonstrating support for multi-language programming. -
LiveCodeBench (v6): 85.0, performing excellently in live code generation.

Deployment and Usage: How to Access Kimi K2.5
This section addresses the core question: Through what channels can developers and general users access Kimi K2.5?
Kimi K2.5 offers flexible access methods covering the needs of everyone from general users to developers.
User-End Products
General users can experience Kimi K2.5’s powerful features through the following platforms:
-
Kimi.com and Kimi App: Currently supports four modes: -
K2.5 Instant: Fast response, suitable for daily conversation. -
K2.5 Thinking: Deep thinking, suitable for complex reasoning. -
K2.5 Agent: Agent mode, supporting tool calls. -
K2.5 Agent Swarm (Beta): Swarm intelligence mode, currently offering free credits for high-tier paid users.
-
Developer and Product Integration
For developers, Kimi provides a dedicated product called Kimi Code:
-
Integration: Supports running directly in the terminal or integration into IDEs like VSCode, Cursor, and Zed. -
Open Source: Kimi Code is itself open source and supports images and videos as input. -
Environment Compatibility: Capable of automatically discovering and migrating existing skills and MCPs (Model Context Protocol) into your working environment.
API and Open Source Weights
-
API: Developers can access model capabilities via the Kimi API. -
Model Weights: The model weights for Kimi K2.5 have been open-sourced on Hugging Face, supporting mainstream inference frameworks like vLLM, SGLang, and KTransformers (requiring transformers 4.57.1 or newer). -
Quantized Deployment: An INT4 quantized version is available, reusing the quantization method from Kimi K2 Thinking, allowing the model to run on consumer-grade GPUs with smaller video memory budgets.
Conclusion
The release of Kimi K2.5 marks a key step for open-source models in the realms of “Visual Agents” and “Group Collaboration.” It is not just a language model but a universal assistant capable of understanding images, writing code, and managing multi-agent swarms. Through the Agent Swarm architecture trained via PARL, it has proven that parallelism is an effective path to solving complex, long-horizon tasks. For developers, researchers, and enterprise users, Kimi K2.5 provides a high-performance, low-cost, and customizable solution, drastically lowering the barrier to entry for AI applications.
Practical Summary / Action Checklist
If you want to get started with Kimi K2.5 immediately, refer to this quick guide:
-
Quick Experience (No Code Required):
-
Visit Kimi.com or download the Kimi App. -
Select the “K2.5 Agent Swarm (Beta)” mode to try complex tasks (like web-wide searching and organizing). -
Upload a design mockup or video and try asking it to generate the corresponding code or document.
-
-
Developer Integration:
-
Install the Kimi Code plugin into your IDE (like VSCode). -
Use the API to integrate K2.5 into your business workflow, leveraging its 256K context to process long documents. -
Download the open-source model weights and deploy the INT4 quantized version locally using vLLM to save VRAM.
-
-
Best Practices:
-
Coding Tasks: Use screenshots for visual debugging; if you encounter an error, just take a screenshot and send it to K2.5. -
Complex Research: Use Agent Swarm mode and let the model automatically decompose tasks and search in parallel.
-
One-Page Summary
| Dimension | Core Feature | Key Data/Metrics |
|---|---|---|
| Model Type | Mixture of Experts (MoE) | 1T Params / 32B Active / 256K Context |
| Vision Capabilities | MoonViT Native Multimodal | VideoMMMU 86.6 / MMMU-Pro 78.5 |
| Coding Capabilities | Vision-Assisted Code Generation | SWE-Bench Verified 76.8 |
| Agent System | Agent Swarm (Parallel Multi-Agent) | 100 Sub-agents / 1500 Steps / 4.5x Efficiency Boost |
| Deployment | API / Open Source / IDE Integration | Supports INT4 Quantization / vLLM / SGLang |
Frequently Asked Questions (FAQ)
1. What is the difference between Kimi K2.5 and the previous Kimi K2?
K2.5 builds on K2 with approximately 15T mixed vision-text tokens of continued pre-training. It introduces a native vision encoder and the brand-new Agent Swarm architecture, showing significant improvements in coding, vision, and agent tasks.
2. What types of tasks is the Agent Swarm mode suitable for?
It is suitable for complex scenarios requiring parallel processing of numerous subtasks, such as “searching for top experts in 100 fields web-wide” or “batch processing large volumes of documents to generate reports.” Compared to a single agent, it significantly reduces task duration.
3. Is Kimi K2.5 completely free?
The model itself is open source, and the weights are free to download. When using Kimi.com and the Kimi App, some advanced features (like Agent Swarm Beta) may have credit tiers for paid users, and API calls are billed according to platform standards.
4. Can I run Kimi K2.5 on my local computer?
Yes. Officially provided INT4 quantized versions make it possible to deploy and run on consumer-grade GPUs with limited video memory (like a 4090 graphics card). You can load the model via inference frameworks like vLLM.
5. Does Kimi K2.5 support video input?
Yes. K2.5 has native video understanding capabilities and can directly analyze video content for use in generating code (e.g., video-to-webpage) or answering video-related questions.
6. How does K2.5 handle image input in coding tasks?
You can upload UI design mockups, screenshots, or bug error screenshots directly. K2.5 will use its visual capabilities to analyze the image content, understand your modification intent or the cause of the error, and then directly generate or modify the corresponding code.
7. How does the parallel mechanism in Agent Swarm work?
The system uses a trained “orchestrator agent” to decompose large tasks and dynamically create multiple “sub-agents.” These sub-agents work independently and simultaneously (e.g., searching different web pages at the same time), and finally aggregate the results. This avoids the inefficiency of a single agent processing items one by one in sequence.

