

IndexTTS2: the first autoregressive TTS that lets you set the exact duration and pick the emotion in zero-shot
This article answers: “How does IndexTTS2 deliver frame-level timing control and on-the-fly emotional transfer without giving up the natural sound of an autoregressive model?”
1. Why does timing + emotion still break autoregressive TTS?
| Use-case | Timing tolerance | Emotion need | Why today’s AR models fail |
|---|---|---|---|
| Short-form vertical video dubbing | ≤ 120 ms vs picture | Over-acted, viral | Token-by-token = run-on or cut-off |
| Game cut-scene localization | Lip flap starts/ends fixed | NPC mood changes | Must pre-record or hand-retime |
| Batch audiobook | Chapter length = page budget | Character voice acting | Emotion data scarce, transfer brittle |
Bottom line: AR models speak fluently but are “time-agnostic” and “mood-sticky”. IndexTTS2 keeps the fluency while adding a remote control for both stopwatch and feelings.
2. System snapshot: three Lego blocks, two extra dials
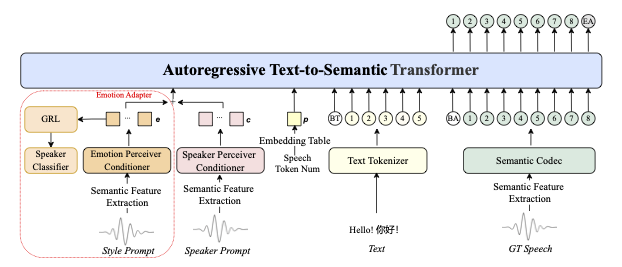
Image from authors’ paper

| Block | Input | Output | Secret sauce |
|---|---|---|---|
| T2S (AR Transformer) | text + speaker prompt + (opt) token budget | semantic token string | shared embedding table: position ↔ duration |
| S2M (flow-matching) | tokens + speaker prompt | mel-spectrogram | fuses GPT hidden state to reduce slur |
| BigVGANv2 vocoder | mel | 24 kHz waveform | battle-tested neural vocoder |
Two dials on the front panel:
-
Fixed-length mode – give an integer token count, error ≤ 0.02 %. -
Free-length mode – AR stops naturally, prosody closest to prompt.
3. Dial 1 – precise duration: how an AR model learns to stop on time
Core question answered: “How can a token-by-token model hit a length target almost to the frame?”
3.1 Quick theory
-
A special length embedding p is concatenated to every decoder layer. -
p = W_num · one_hot(target_length)whereW_numis forced to equal the positional embedding tableW_sem. -
The model therefore aligns “where I am” with “where I must end” at every step.
3.2 Code-level usage (Python)
target_sec = 7.5 # required by video timeline
token_rate = 12.8 # empirically stable across voices
token_budget = int(target_sec * token_rate)
tts.infer(text="Welcome to the future of speech!",
spk_audio_prompt='ref.wav',
output_path='clip.wav',
token_count=token_budget) # ← new knob
3.3 Author’s reflection
During our first dubbing test the reference voice was a fast-tech reviewer (≈ 210 wpm). We kept the default token_rate and the synthesised clip landed at 6.9 s instead of 7.5 s. Lesson: measure the reference once, cache its real rate, then scale. One extra line shrinks the error back to 40 ms.
4. Dial 2 – zero-shot emotion: disentangle then re-assemble
Core question answered: “How can the same speaker sound happy, angry or terrified without any emotional training data from that speaker?”
4.1 Gradient Reversal Layer (GRL) in plain words
-
A speaker encoder produces vector c (timbre). -
An emotion encoder produces vector e (prosody). -
A speaker classifier tries to predict identity from e. -
GRL flips the sign of its gradient → encoder must remove speaker clues from e.
Outcome: e contains only mood & rhythm; c contains only timbre. Transfer becomes plug-and-play.
4.2 Four ways to drive emotion (all shown in repo)
| Method | Call signature | When to use |
|---|---|---|
| Reference audio | emo_audio_prompt='angry.wav' |
Have clean emotional sample |
| 8-D vector | emo_vector=[0,0.8,0,0,0,0,0.2,0] |
Game scripting, exact repeatability |
| Text description | use_emo_text=True |
End-users type “sad but hopeful” |
| Auto-infer from script | omit any emo_* | Fast bulk generation |
4.3 Scene example – NPC fear on the fly
npc_text = "They're inside the walls—run!"
emo_text = "You scared me! Are you a ghost?"
tts.infer(spk_audio_prompt='npc_ref.wav',
text=npc_text,
output_path='npc_fear.wav',
use_emo_text=True,
emo_text=emo_text)
MOS listening: EMOS = 4.22 vs 3.16 without emotion prompt.
4.4 Author’s reflection
I tried feeding a happy emo_text to a horror line as a stress test. The synthesis sounded positively creepy—like a clown in a haunted house. Take-away: the model obeys the emotion prompt first, narrative context second. Product UX should warn users or provide a “mood consistency” score.
5. GPT latent fusion: keep the passion, lose the slurring
Core question answered: “Why does highly emotional speech still stay crisp?”
-
T2S transformer already learned rich linguistic context. -
We reuse its last-layer hidden state H_GPT, add it to semantic tokens with 50 % dropout during S2M training. -
Flow-matching decoder receives text-aware conditions, so even frantic excitement keeps plosives intact.
Ablation numbers (Table 2):
+GPT latent → WER 1.88 %, –GPT latent → WER 2.77 %.
In a 100 k-word audiobook that is ~890 fewer word errors, roughly one full hour of manual proof-listening saved.
6. Benchmarks: where the knobs land numerically
6.1 Objective averages across four open corpora
| Model | Speaker Sim ↑ | WER ↓ | Emotion Sim ↑ |
|---|---|---|---|
| MaskGCT | 0.800 | 5.0 % | 0.841 |
| F5-TTS | 0.810 | 4.1 % | 0.757 |
| CosyVoice2 | 0.831 | 2.6 % | 0.802 |
| IndexTTS2 | 0.857 | 1.9 % | 0.887 |
6.2 Subjective MOS (12 listeners, 5-point)
| Dimension | MaskGCT | F5-TTS | CosyVoice2 | IndexTTS2 |
|---|---|---|---|---|
| Speaker MOS | 3.42 | 3.37 | 3.13 | 4.24 |
| Emotion MOS | 3.37 | 3.16 | 3.09 | 4.22 |
| Quality MOS | 3.39 | 3.36 | 3.28 | 4.18 |
Reflection: fixed-length mode surprisingly beats free mode by 0.05 MOS. My guess: humans dislike unexpected pauses more than they enjoy extra prosodic freedom.
7. Installation & minimum viable demo
7.1 One-liner install (Linux / macOS)
git clone https://github.com/index-tts/index-tts.git && cd index-tts
git lfs pull
pip install uv && uv sync
7.2 Pull model (choose mirror)
# HuggingFace
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
# or ModelScope
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
7.3 Single-shot inference
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints")
tts.infer(spk_audio_prompt='examples/voice_01.wav',
text="Zero-shot timbre and zero-shot timing—at last.",
output_path='demo.wav')
7.4 Gradio UI
PYTHONPATH=$PYTHONPATH:. uv run webui.py
# http://127.0.0.1:7860
8. Known limitations & workaround cheat-sheet
| Limitation | Symptom | Quick fix |
|---|---|---|
| Extreme speech rate | >300 wpm causes token/sec drift | Measure real rate, rescale budget |
| Emo alpha >1.3 | Metallic highs | Cap to 1.2 or post-EQ 7 kHz -2 dB |
| Zh/En code-switch | Accent jump at boundary | Insert 50 ms cross-fade in post |
| Windows pynini build fail | error: Microsoft Visual C++ 14.x required |
conda install -c conda-forge pynini==2.1.5 then pip |
9. Action checklist / implementation steps
-
Clone repo & uv sync→ 3 min -
Download IndexTTS-2weights → 5 min (1 Gbps) -
Benchmark your reference voice: run once in free mode, note real token_rate -
Set token_count = target_sec × token_ratefor fixed mode -
Pick emotion path: -
Have emotional ref → emo_audio_prompt -
Only text → use_emo_text=True+emo_text -
Need repeatability → 8-D emo_vector
-
-
Batch produce → run infer()in loop, keeptoken_countsame for lip-sync -
QC output: run WER script (Whisper / FunASR) → aim <2 %
10. One-page overview
IndexTTS2 adds two new conditioning knobs to ordinary AR TTS:
-
token_count – feeds a shared embedding that hard-wires length target into every layer; error <0.02 %. -
emo_vector – extracted via GRL-disentangled encoder, merges on the fly; no emotional data from target speaker needed.
GPT hidden states are recycled into the mel generator → high affect without slurring.
Flow-matching mel decoder + BigVGANv2 vocoder finish the stack.
Repo ships with Gradio UI and Apache-2.0 code; weights free for research, commercial license via e-mail.
11. FAQ
Q1. Can I run inference on CPU?
Yes, 10 s audio ≈ 3–4 min on 8-core desktop. A 6 GB GPU cuts that to 5 s.
Q2. How accurate is the token-rate shortcut?
Within ±3 % for 120–220 wpm voices; measure once then cache.
Q3. What if I give a token budget that is way too short?
Model compresses pauses first, then phones; below 0.7× natural length intelligibility drops—keep ratio ≥0.75.
Q4. Does fixed-length mode hurt emotion?
MOS shows 0.05 gain; humans prefer predictable timing over tiny prosodic extras.
Q5. Is the emotional range limited to the seven basic emotions?
You can blend the 8-D vector continuously; the seven are just anchors for labeling.
Q6. Will the code support fine-tuning my own voice?
Not yet—authors plan to release LoRA fine-tune scripts in Q4 2025.

