

SkillsBench Deep Dive: Why Human-Crafted Agent Skills Dramatically Outperform AI-Generated Ones
Core Question: Of the tens of thousands of AI Agent Skills currently available on the market, how many actually deliver value? How can we distinguish a useful skill from a useless one, and what are the best practices for optimization?
The capability boundaries of AI Agents are constantly being expanded by modular knowledge packages known as “Skills.” However, an awkward reality persists: among the tens of thousands of available skills, only a precious few are truly effective. A comprehensive new study, SkillsBench, involving 7,308 rigorous test trajectories, reveals that human-curated skills can boost task success rates by up to 51.9%, while skills spontaneously generated by models offer almost zero value—and can even be detrimental. This is not merely a technical issue; it is a fundamental rethinking of the nature of knowledge engineering.
I. When AI Meets “Skills”: A Concept Fraught with High Expectations
What Exactly Are Agent Skills?
First, we must clarify a critical concept: Agent Skills are not simple prompt words or tool documentation.
A qualified Skill is a structured knowledge package that must satisfy four criteria simultaneously: it provides procedural guidance (how to do, not what is), it applies to a class of tasks rather than a single instance, it possesses structured components (such as a SKILL.md file and optional resources), and it maintains portability across models and frameworks. This fundamentally distinguishes them from system prompts, few-shot examples, RAG retrievals, or tool documentation.
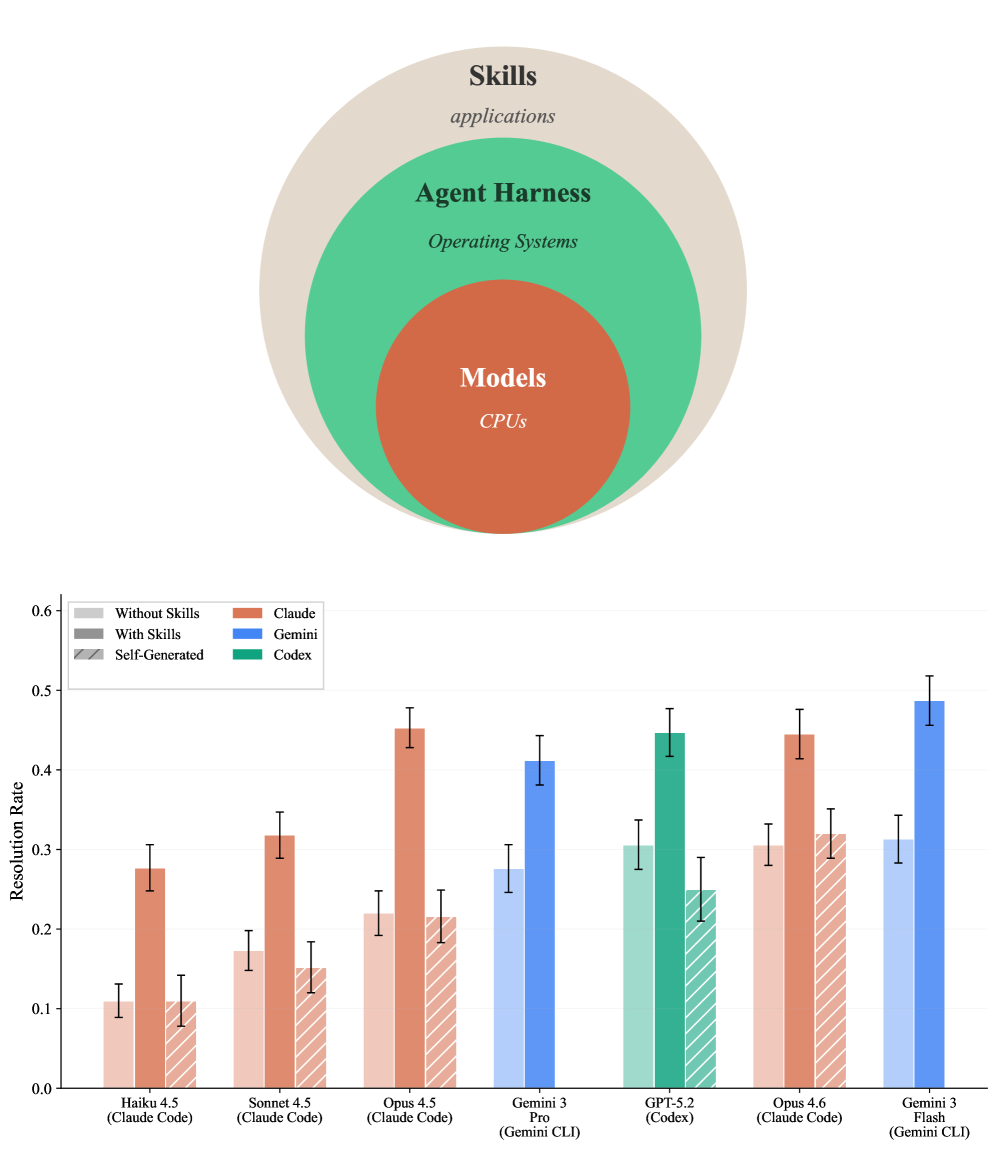
You can visualize the foundation model as the CPU, the agent framework as the operating system, and Skills as the applications installed on top—they provide specialized procedures for specific domains on top of general capabilities.
Explosive Growth vs. The Value Dilemma
The skill ecosystem has experienced explosive growth. The total number of skill packages from open-source communities, the Claude Code ecosystem, and enterprise partners has reached 47,150, covering software engineering, data analysis, and even enterprise workflows.
However, behind this prosperity lies a profound crisis of trust. In the SkillsBench evaluation, the effectiveness of this massive volume of skills was not verified. More concerning is that while 60%-80% of existing skills are concentrated in the software engineering domain, high-quality skills are severely lacking in vertical fields like healthcare, manufacturing, and finance. This ecological imbalance implies that when AI truly enters these high-value professional scenarios, it may face a situation where “no skills are available.”
“
Industry Insight: It is unsurprising that the majority of skills are tech-centric. The technical community has a strong culture of open-source sharing. However, the real opportunity lies in bridging the gap for non-technical sectors. Teaching professionals in legal, medical, and manufacturing fields to codify their expertise into skills will be a high-value endeavor in the coming years.
II. SkillsBench: How to Scientifically Test if a Skill is Truly Useful?
Core Question: How do we build a benchmarking framework that fairly and accurately evaluates the intrinsic value of a skill?
Previous agent benchmarks (like SWE-bench or WebArena) primarily evaluated the raw capabilities of models or agents in specific environments. They answered the question: “How does this model/agent perform on Task X?” SkillsBench, however, treats the skill itself as a first-class evaluation object, aiming to answer a more critical question: “What is the contribution of Skill Y to the performance on Task X?”
A Three-Layer Control Experiment: Validating Skill Value
The core methodology of SkillsBench is a paired control experiment. Each task is tested under three strictly distinct conditions:
-
No Skills: The agent receives only the task instruction with no skill packages in the environment. This represents the agent’s baseline raw capability. -
Curated Skills: The environment contains skill packages written by domain experts, having undergone strict review and deduplication. This tests the potential value of skills in an ideal state. -
Self-Generated Skills: No external skills are provided, but the agent is required to generate the procedural knowledge it deems useful before starting the task. This tests the model’s ability to utilize its implicit knowledge to generate skills.
This design allows us to clearly isolate the independent contribution of a skill, rather than confusing it with other factors like model capability or context length.
Ensuring Fairness and Rigor
To ensure test results were credible, SkillsBench applied nearly stringent principles to dataset construction, divided into automated validation and human review phases.
The Automated Validation “Filter”:
-
Structural Integrity: Must include instruction, task configuration, solution script, and verification script. -
Oracle Execution: The provided reference solution must pass the verification tests 100%, ensuring the task is solvable. -
Instruction Quality: Instructions must be human-written and meet six standards, such as explicit output paths and structured requirements.
The Human Review “Quality Gate”:
Tasks passing automated validation were reviewed by domain experts across five dimensions:
-
Data Validity: Rejecting toy or synthetic data. -
Task Realism: Reflecting real professional workflows. -
Solution Expertise: Aligning with how a domain expert would solve it. -
Skill Quality: Error-free, logically consistent, and genuinely valuable for similar tasks. -
Anti-Cheating: Preventing shortcut solutions like editing input data or extracting answers from test files.
Crucially, all tasks underwent a “leakage audit” to ensure skill packages did not contain task-specific answers, filenames, or magic numbers. Skills must provide procedural guidance on “how to do,” not declarative answers on “what is.” Ultimately, 84 tasks across 11 domains were selected from 322 candidates, stratified by difficulty (Core, Extended, Extreme) based on estimated human completion time.
III. Key Findings: Why Are Only a Few of 40,000 Skills Worth Gold?
Core Question: After testing 7,308 trajectories across 84 tasks and 7 model configurations, what is the true value of skills?
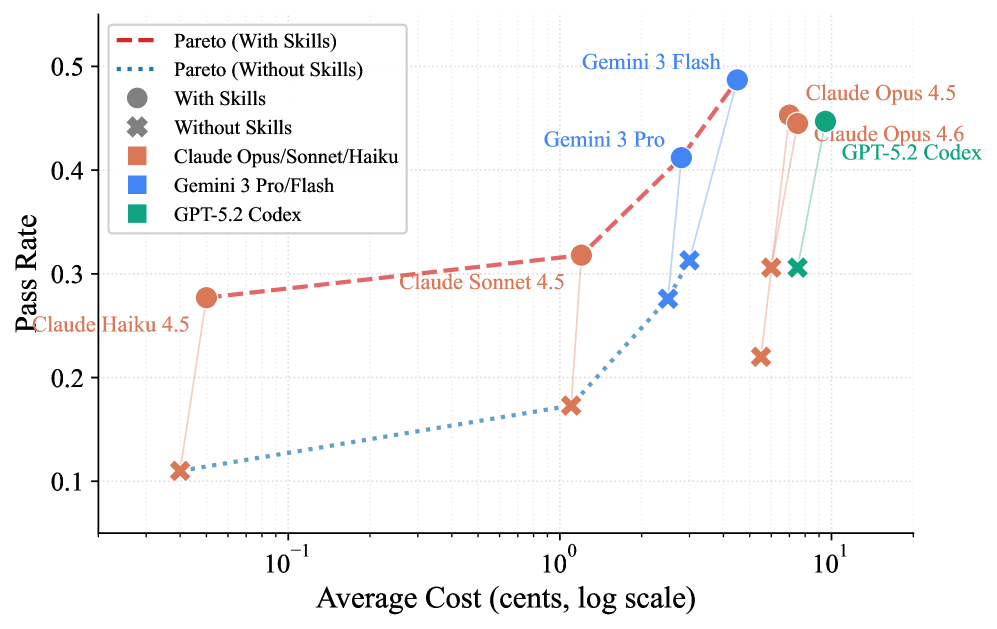
Finding 1: Human Skills Offer Huge Value, But With High Variance
Data shows that carefully curated human skills can increase the task pass rate by an average of 16.2 percentage points. This is a positive overall signal, proving that the injection of professional knowledge is indeed effective.
However, the average masks significant disparity. The benefits vary wildly by domain:
-
In Healthcare, the improvement was a massive +51.9pp. -
In Manufacturing, the improvement was similarly significant at +41.9pp. -
By contrast, in Software Engineering and Mathematics, improvements were merely +4.5pp and +6.0pp respectively.
Surprisingly, 16 tasks actually showed performance degradation after introducing skills. For instance, in the “taxonomy-tree-merge” task, performance dropped by 39.3 percentage points. This indicates that skills are not a panacea; if the introduced guidance conflicts with the model’s strong prior knowledge or adds unnecessary cognitive load, it can backfire.

Finding 2: AI Self-Generated Skills Are Virtually Worthless, Even Harmful
This is the study’s most “brutal” conclusion. In stark contrast to human skills, asking models to generate their own skills not only failed to yield gains but often led to performance drops.
In experiments, only Claude Opus 4.6 saw a marginal gain (+2.0%) under self-generated conditions. Conversely, the Codex + GPT-5.2 combination saw performance plummet by 8.1%. Trajectory analysis revealed two failure modes: models either generated vague, incomplete procedures (e.g., saying “use pandas” without specific API patterns) or, for high-expertise domains like healthcare or manufacturing, failed to recognize the need for specialized skills entirely, attempting brute-force solutions with general-purpose methods.
This finding profoundly illustrates that models are good at consuming structured knowledge but poor at producing high-quality structured procedural knowledge. Truly effective SOPs are the crystallization of human domain experience and cannot be conjured out of thin air by models.
Finding 3: Skill Efficacy Depends Heavily on Agent Framework Integration
“Good skills need a good platform.” The study found that different agent frameworks have vastly different abilities to utilize skills.
-
Claude Code exhibited the highest skill utilization rate, with all Claude models benefiting consistently. -
Gemini CLI achieved the highest raw performance (48.7%) after integrating skills. -
Codex CLI exposed a problem: even when provided with skills, the agent frequently “acknowledged” the content but then proceeded to implement solutions independently, ignoring the resource.
This reminds us that evaluating skill value cannot be detached from the agent environment in which it runs. Framework-level mechanisms for retrieval, context management, and instruction adherence are critical middleware for skills to take effect.

IV. The Skill Design Handbook: Best Practices Derived from Experimental Results
Core Question: Since skills are effective, what makes a skill more effective? How should they be written?
Based on large-scale experiments, we can distill core principles for skill design. These are not theoretical speculations but conclusions drawn from 7,308 actual runs.
Principle 1: Focus is King, Reject “Comprehensive” Bloat
Quantity is not better: When a task was equipped with 4 or more skills, the average gain plummeted to +5.9pp, far lower than the +18.6pp seen with 2-3 skills.
Content length is not better: Detailed but focused skills improved performance by +18.8pp. However, so-called “comprehensive” long documentation not only failed to help but caused performance to drop by -2.9pp.
The logic is clear: agents, like humans, face cognitive difficulties with information overload. An excellent skill should be a surgical tool, not an encyclopedia. It needs to provide step-by-step, actionable guidance, accompanied by at least one working example, which is far more effective than lengthy theoretical documentation.
| Skill Quantity/Complexity | Avg Performance Improvement (Δabs) | Key Conclusion |
|---|---|---|
| 2-3 Skills | +18.6pp | Optimal range |
| 4+ Skills | +5.9pp | Diminishing returns, potential conflict |
| Detailed & Focused | +18.8pp | Most effective format |
| “Comprehensive” Docs | -2.9pp | Negative effect, consumes context budget |
Principle 2: Modular Design and Framework Adaptation
Single, bloated skills struggle with complex tasks. Research shows that modular skills compose better for multi-part tasks. Each skill should solve a clear problem or step.
Furthermore, skill writing must account for the specific constraints of the agent framework. For example, if a framework requires a strict JSON output protocol, the skill should include repeated reminders about the format to prevent “format drift” during long interaction chains.
Principle 3: Target “High-Value” Blank Spaces
The highest ROI for skill development lies in domains where pretraining data coverage is low but highly specialized processes exist.
-
Healthcare: Clinical data harmonization, diagnostic workflow coding. -
Manufacturing: Production workflow optimization, equipment protocol interfacing. -
Cybersecurity: Penetration testing standards. -
Finance: Specific regulatory report generation.
In these fields, an excellent skill can equate to years of experience from a senior expert, bringing a qualitative leap for a general-purpose model. Conversely, in domains like software engineering or mathematics, where models are already “saturated” with code and proof data, the marginal benefit of skills is lower.
Principle 4: Small Model + Good Skills Can Challenge Large Models
This is perhaps one of the most commercially valuable findings. In the Claude model family comparison, the smaller Claude Haiku 4.5 achieved 27.7% performance when equipped with quality skills. The larger Claude Opus 4.5 without skills only managed 22.0%.
Small Model + Well-Designed Skills ≈ > Large Model’s Raw Capability
This means for cost-sensitive scenarios with clear vertical domain needs, building a high-quality skill library is more economically effective than simply chasing model parameter size. It provides a feasible path for cost reduction and efficiency gains in enterprise AI applications.
V. Practical Implications: Launching Your Skill Engineering Project
Core Question: For enterprises and developers, how do we translate research findings into action?
Action 1: Establish a Human-Led Skill Development Process
Be clear: letting AI automatically generate skills is currently unviable. You need a knowledge engineering process centered on domain experts.
-
Extract SOPs: Interview your senior staff and experts to map out standard operating procedures for solving specific classes of problems. This is the raw material for skills. -
Structured Encapsulation: Convert SOPs into SKILL.mdformat, clarifying steps, caveats, and common errors. Write reusable code templates or scripts for core steps. -
Provide Working Examples: Show a complete process of applying the skill to a specific typical task. This is the most effective teaching method. -
Iterate Continuously: In real usage, collect failure cases of the agent and reverse-engineer the skill documentation to fix ambiguities.
Action 2: Prioritize Filling Skill Gaps in Vertical Domains
Audit your business domain. If it belongs to healthcare, law, manufacturing, or energy, now is the perfect time to build a skill library because:
-
Competitors may not have acted yet. -
The model’s raw capability in this area is weakest, making the skill’s impact most significant. -
Your professional knowledge has high moat value.
Action 3: Choose or Build an Agent Framework That Excels at Using Skills
When selecting or developing an agent platform, look beyond the breadth of model integration. Examine the depth of its context management and skill invocation.
-
Can the framework effectively load and focus on relevant skills between long-term memory and the current task? -
Can it avoid “instruction forgetting” issues in long conversations? -
Does it support modular combination and dynamic loading of skills?
Choosing a framework friendly to skill integration is the technical foundation for ensuring your knowledge investment pays off.
VI. Practical Summary & One-Page Overview
Practical Summary / Action Checklist
-
Don’t Trust AI Self-Generated Skills: Current models cannot reliably create high-quality skills; human expert knowledge is mandatory. -
Pursue Focus, Avoid “Comprehensive”: Writing 2-3 targeted, clear skills is far better than a lengthy “comprehensive” document. -
Target High-Value Domains: Invest skill development efforts in vertical fields like healthcare, manufacturing, and law for the highest ROI. -
Small Models Have Big Potential: Empowering a small model with high-quality skills can match or beat a large model’s performance at a lower cost. -
Prioritize Framework Selection: Choose agent frameworks that effectively retrieve, understand, and apply skill context. -
Standardize Development: Establish a human-led process: “Expert Interview → SOP Extraction → Structured Encapsulation → Example Provision → Iterative Optimization.”
One-Page Overview
Core Conclusion: SkillsBench testing confirms that human-curated skills boost AI task success rates by an average of 16.2%, peaking at 51.9%, while model self-generated skills are negligible or harmful.
Key Data:
-
Effective Skill Ratio: Roughly 1,000 curated skills used for high-quality evaluation out of ~47,000 in the ecosystem. -
Optimal Quantity: Equipping 2-3 skills per task is optimal; more than 4 sees diminishing returns. -
Optimal Format: Detailed but focused guidance + at least one working example > Lengthy comprehensive documentation. -
High-Value Domains: Healthcare (+51.9pp), Manufacturing (+41.9pp), Cybersecurity (+23.2pp).
Actionable Advice: Establish a human-led skill development process, prioritize building skill libraries in vertical professional domains, and select agent frameworks friendly to skill integration to achieve professional AI capabilities and cost optimization.
VII. Frequently Asked Questions (FAQ)
Q1: My business scenario is relatively unique. Are there ready-made skills I can use?
A: Currently, high-quality public skills are concentrated in software engineering and data science. For vertical fields like healthcare, manufacturing, or law, ready-made resources are scarce. The best solution is to initiate an internal, expert-led skill development project to transform your unique business processes into knowledge assets usable by AI.
Q2: What is the difference between a Skill and RAG (Retrieval-Augmented Generation)? Which should I use?
A: RAG is primarily used to supplement factual knowledge (“what is”), while Skills supplement procedural knowledge (“how to do”). If your task is to answer “What is the company’s vacation policy?”, use RAG. If the task is “Please fill out a project risk assessment report following internal compliance procedures,” you need a Skill. They can be used in combination.
Q3: Is there a simple way to test if a skill is effective?
A: You can use a simple A/B test. Select a class of tasks where you already have a clear SOP. Let the agent execute the task multiple times under both “No Skill” and “With Skill” conditions. Compare the success rate, completion time, and consistency of output quality. If the improvement is significant, the skill is effective.
Q4: Can skills make a model “dumber”? Why did performance drop in some tasks after adding skills?
A: Yes. If the skill content conflicts with the model’s existing high-quality prior knowledge, or if the skill is too lengthy or vague, it will confuse the agent and lead to decision errors. This underscores the importance of skill quality—incorrect or inefficient guidance is worse than no guidance at all.
Q5: For non-technical personnel, how should I understand the value of “Skills”?
A: Think of it as a “work manual” or “expert coaching” for the AI clerk. Without a manual, it might fumble with general methods, resulting in low efficiency and errors. With a precise manual, it can complete professional work efficiently and standardized, just like a skilled worker. And the manual must be written by a real expert.
Q6: Can AI automatically generate skills in the future? What does this study imply?
A: This research indicates that for the foreseeable future, high-quality skills will still rely on human experts. This doesn’t mean AI is useless; rather, AI’s role will shift from “content generator” to “assistant to the knowledge engineer,” helping humans record, structure, and optimize SOPs. The final decision-making power remains in human hands. This suggests that building a human-machine collaborative knowledge engineering system is the priority for the next stage.

