

GLM-4.5: A Breakthrough in Open-Source AI Language Models
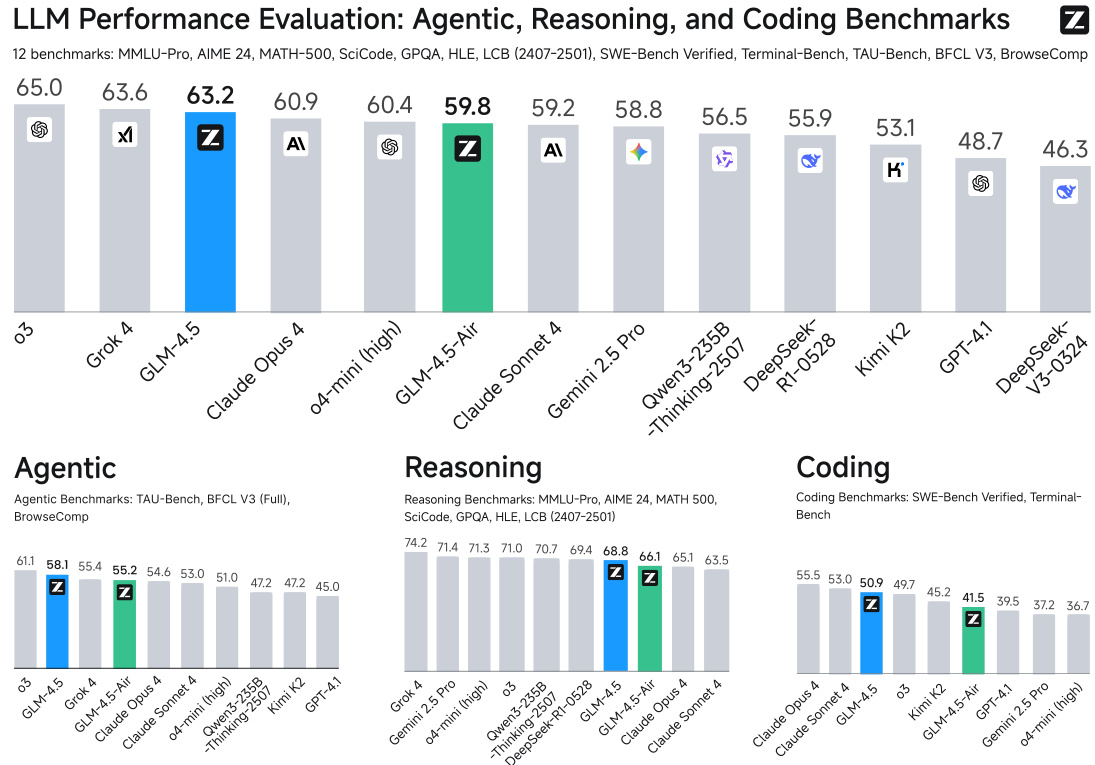
Figure 1: GLM-4.5’s average performance across Agentic, Reasoning, and Coding (ARC) benchmarks

1. What is GLM-4.5?
GLM-4.5 is a new generation of open-source large language model (LLM) developed by Zhipu AI and Tsinghua University. Unlike conventional language models, it employs a 「Mixture-of-Experts (MoE) architecture」, maintaining high parameter scale (355 billion total parameters) while achieving efficient computation through dynamic activation (only 32 billion parameters actively participate in calculations).
Key Features:
-
「Multi-modal reasoning」: Supports both “thinking mode” and “direct response” modes -
「Domain excellence」: Outstanding performance in agentic tasks, complex reasoning, and code generation -
「Open-source friendly」: Available in two versions – full 355B parameter model and compact 106B GLM-4.5-Air
2. Architecture Design: Why MoE?
2.1 What is MoE Architecture?
MoE (Mixture-of-Experts) is a specialized neural network structure that divides the model into multiple “expert modules.” Each input token dynamically selects the most relevant experts for processing, similar to a hospital triage system – different symptoms are directed to different departments.
「Parameter Comparison Table」
| Model | Total Parameters | Activated Parameters | Dense Layers | MoE Layers |
|---|---|---|---|---|
| GLM-4.5 | 355B | 32B | 3 | 89 |
| GLM-4.5-Air | 106B | 12B | 1 | 45 |
| DeepSeek-V3 | 671B | 37B | 3 | 58 |
| Kimi K2 | 1043B | 32B | 1 | 60 |
Data Source: Paper Table 1
2.2 Architectural Innovations
-
「Depth-First Design」
Compared to similar models (e.g., DeepSeek-V3), GLM-4.5 prioritizes increasing model depth over width. Experiments show 「deeper architectures perform better in mathematical reasoning tasks」. -
「Attention Mechanism Optimization」
-
Uses Grouped-Query Attention (GQA) -
Increases attention heads to 96 (with 5120 hidden dimension) -
Implements QK-Norm technology to stabilize attention logic ranges
-
-
「Multi-Token Prediction Layer (MTP)」
Adds a specialized layer at the model end to support speculative decoding during inference, 「improving generation speed by over 30%」.
3. Training Process: How to Build a Top-Tier Model?
3.1 Pre-training: Data Determines the Ceiling
「Training Data Composition」
-
Web pages (English/Chinese) -
Multilingual texts (filtered by quality classifiers) -
Code repositories (GitHub and other platforms) -
Mathematics/science literature
「Data Processing Highlights」
-
Web deduplication: Combines MinHash and semantic deduplication (SemDedup) techniques -
Code enhancement: Uses Fill-In-the-Middle objective function -
Quality stratification: Assigns weights to different data sources, prioritizing high-frequency knowledge
3.2 Mid-Training: Specializing Capabilities
Stage 1: Repository-Level Code Training
-
Trains on concatenated code files from the same repository -
Includes issues, pull requests (PRs), and commit histories -
Extends sequence length to 32K tokens
Stage 2: Synthetic Reasoning Data
-
Generates mathematical/science competition problem solutions -
Constructs coding competition problems and solutions
Stage 3: Long Context & Agent Training
-
Extends sequence length to 128K tokens -
Introduces large-scale agent trajectory data
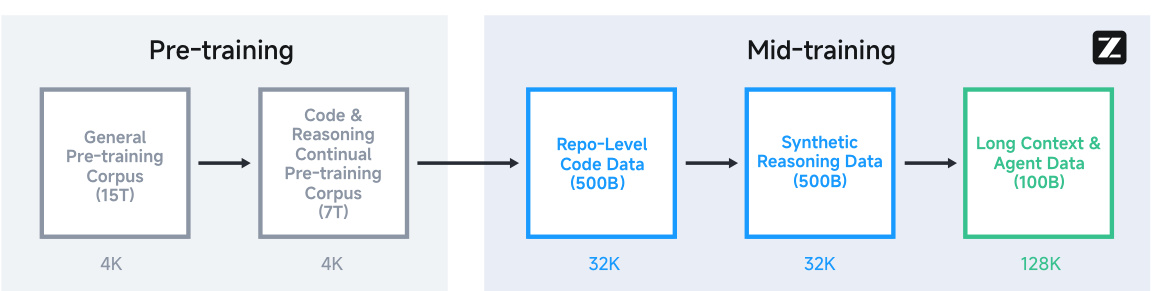
Figure 3: Complete pre-training and mid-training process for GLM-4.5
3.3 Post-Training: Expert Model Iteration
Adopts a two-stage strategy:
-
「Expert Training」
Trains three specialized models:-
Reasoning Expert -
Agent Expert -
General Chat Expert
-
-
「Unified Training」
Integrates expert capabilities through self-distillation, resulting in a final model capable of:-
Deep thinking mode (for complex tasks) -
Fast response mode (for casual conversation)
-
4. Performance: How Does It Actually Perform?
4.1 Agentic Tasks
「Key Metrics」
| Benchmark | GLM-4.5 | Comparison Model (o3) |
|---|---|---|
| TAU-Retail | 79.7% | 70.4% |
| BFCL V3 | 77.8% | 72.4% |
| BrowseComp | 26.4% | 49.7% |
Data Source: Paper Table 3
「Real-World Application Example」
In TAU-Bench retail scenario testing, the model can:
-
Understand multi-turn conversations -
Query APIs for product inventory -
Handle complex operations like order modifications
4.2 Reasoning Capabilities
「Math & Science Task Performance」
| Benchmark | Accuracy | Comparison Model (o3) |
|---|---|---|
| AIME 24 | 91.0% | 90.3% |
| MATH-500 | 98.2% | 99.2% |
| GPQA | 79.1% | 82.7% |
Data Source: Paper Table 4
「Technical Highlights」
-
91% accuracy on AIME 2024 math competition problems -
Solves 14.4% of “Humanity’s Last Exam” (HLE) questions -
Scores 72.9% on LiveCodeBench coding tasks
4.3 Code Generation
「SWE-bench Verified Results」
| Model | Accuracy | Comparison Model (Claude Sonnet 4) |
|---|---|---|
| GLM-4.5 | 64.2% | 70.4% |
Data Source: Paper Table 5
「Practical Capability Demonstration」
-
64.2% success rate in fixing real GitHub issues -
Scores 37.5% on Terminal-Bench terminal tasks
5. Typical Application Scenarios
5.1 Code Development Assistant
「Supported Functions」
-
Automatically generates Python/JavaScript code -
Fixes issues in existing codebases -
Understands project documentation and provides suggestions
「Real-World Case」
In CC-Bench testing:
-
40.4% task win rate vs Claude Sonnet 4 -
90.6% tool call success rate (industry leading)
5.2 Intelligent Customer Service System
「Core Advantages」
-
Supports complex multi-turn conversations -
Understands implicit user intentions -
Calls external APIs to process order inquiries
5.3 Educational Assistance
「Applicable Scenarios」
-
Automatic math problem solving -
Code assignment grading -
Scientific concept explanations
6. How to Access and Use?
6.1 Download Links
-
「Full Model」
HuggingFace Link -
「Compact Model」
GLM-4.5-Air
6.2 Hardware Requirements
| Model Version | VRAM Requirement | Recommended GPU |
|---|---|---|
| GLM-4.5 | 80GB+ | NVIDIA H100/A100 |
| GLM-4.5-Air | 24GB+ | NVIDIA A10/A6000 |
7. Frequently Asked Questions (FAQ)
Q1: Who is GLM-4.5 suitable for?
Suitable for developers needing to build intelligent agent systems, automated coding tools, or complex dialogue robots. Particularly ideal for:
-
Enterprise intelligent customer service development -
Code assistance tool construction -
Educational AI applications
Q2: How to call the model API?
Official Python SDK example:
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="your_api_key")
response = client.chat.completions.create(
model="glm-4.5",
messages=[{"role": "user", "content": "Write a Python sorting algorithm"}]
)
print(response.choices[0].message.content)
Q3: What advantages does it have compared to other models?
-
「Parameter efficiency」: Achieves performance comparable to models with tens of billions more parameters -
「Long context handling」: Natively supports 128K tokens context -
「Multilingual support」: Strong mixed Chinese/English processing capabilities
Q4: Are there fine-tuning guidelines?
The official repository provides:
-
LoRA fine-tuning example code -
RLHF training framework -
Multi-GPU training configuration templates
8. Technical Evolution Directions
The paper mentions future focus areas:
-
「Multi-modal capabilities」: Support for image/video understanding -
「Inference speed optimization」: Through speculative decoding technology -
「Enhanced safety」: Better value alignment

