

Meta’s Generative Ads Model (GEM): The Central Engine Powering Advertising AI Innovation
In today’s digital advertising landscape, artificial intelligence is transforming how businesses connect with their audiences. At the heart of this revolution stands Meta’s Generative Ads Recommendation Model (GEM), a sophisticated AI system that’s redefining personalized advertising at scale. This “central brain” for ad recommendations isn’t just improving campaign performance—it’s establishing new standards for how large-scale AI models can drive business value.
Understanding GEM: Meta’s Advertising Intelligence Core
The Generative Ads Recommendation Model represents Meta’s most advanced foundation model for advertising, built using principles inspired by large language models and trained across thousands of GPUs. As the industry’s largest foundation model specifically designed for recommendation systems, GEM operates at a scale comparable to modern LLMs while focusing exclusively on optimizing ad relevance and performance.
What sets GEM apart is its ability to address fundamental challenges in digital advertising. Every day, billions of user-ad interactions occur across Meta’s platforms, but meaningful signals like clicks and conversions remain relatively sparse. GEM must identify meaningful patterns within this vast, imbalanced dataset and generalize these insights across diverse user behaviors and preferences.
The results speak for themselves. Since its deployment, GEM has driven a 5% increase in ad conversions on Instagram and a 3% increase in Facebook Feed conversions. Even more impressively, recent architectural improvements have doubled the performance benefit GEM derives from each additional unit of data and computing power, creating an increasingly efficient learning system.
The Three Innovation Pillars of GEM
GEM’s breakthrough performance stems from three interconnected innovations that work together to create a more intelligent advertising ecosystem.
Scalable Model Architecture
GEM’s design allows it to grow more capable as parameters increase, consistently generating more precise predictions while maintaining efficiency. Compared to Meta’s original ad recommendation ranking models, GEM delivers 4 times the efficiency in driving advertising performance gains from the same amount of data and computational resources.
This efficiency emerges from GEM’s sophisticated approach to processing different data types:
-
Sequence features: User activity history and behavioral patterns over time -
Non-sequence features: Static attributes like user demographics, location, ad format, and creative elements
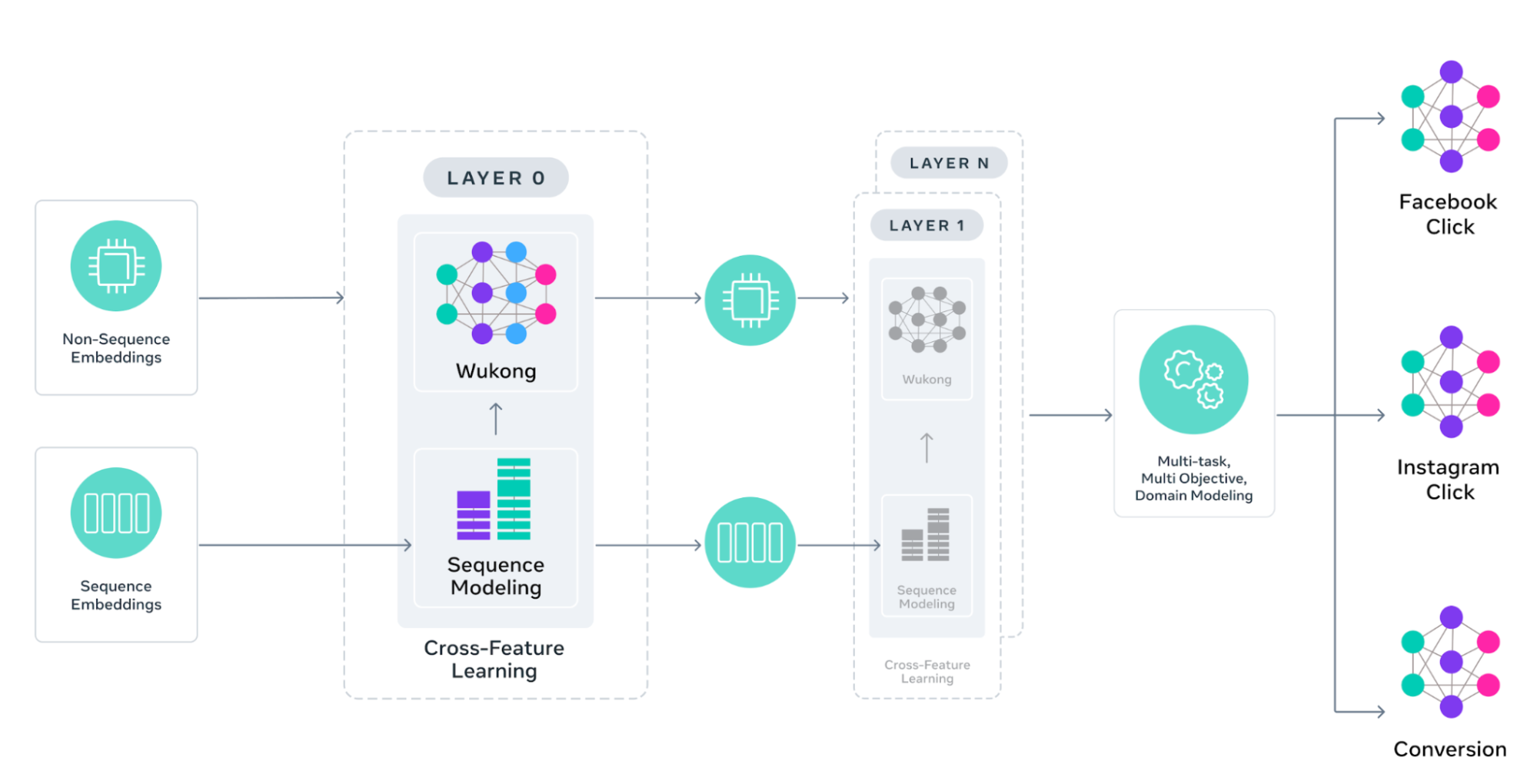
The model applies customized attention mechanisms to each feature category while enabling cross-feature learning, creating a comprehensive understanding of user-ad relationships.


Advanced Knowledge Transfer Framework
GEM’s true value emerges when its learnings propagate throughout Meta’s advertising ecosystem. The model employs two distinct transfer strategies to disseminate its knowledge:
-
Direct transfer: GEM shares knowledge directly with major vertical models operating within familiar data environments -
Hierarchical transfer: GEM’s insights flow through domain-specific foundation models before reaching specialized vertical models
This dual approach, incorporating knowledge distillation, representation learning, and parameter sharing techniques, achieves twice the effectiveness of standard knowledge distillation methods.
Revolutionary Training Infrastructure
Training a model of GEM’s magnitude requires unprecedented computational resources and optimization. Meta’s reengineered training stack delivers a 23x increase in effective training FLOPS while using 16 times more GPUs. Crucially, the model FLOPS utilization—a key measure of hardware efficiency—improved by 1.43x, demonstrating smarter resource usage rather than simply throwing more hardware at the problem.
Deep Dive into GEM’s Architectural Innovations
To appreciate why GEM performs so effectively, we need to examine its architectural foundations. The model trains on both advertising content and user engagement data, including organic interactions, then processes this information through specialized pathways for different data types.
Modeling Non-Sequence Feature Interactions
Understanding how user attributes interact with ad characteristics forms the foundation of effective recommendations. GEM enhances the Wukong architecture to employ stackable factorization machines with cross-layer attention connections, enabling the model to identify which feature combinations matter most for different contexts.
Each Wukong block can scale vertically for deeper interactions and horizontally for broader feature coverage, allowing GEM to discover increasingly complex patterns in how different users respond to various ad attributes. This means the model can identify non-obvious but valuable relationships, such as how users in specific age groups respond to certain ad formats during particular times of day.
Processing Offline Sequence Features
User behavior sequences—extended histories of ad and content clicks, views, and interactions—contain rich signals about preferences and intent. Traditional architectures struggle with these long sequences, but GEM overcomes this limitation through a pyramid-parallel structure that stacks multiple parallel interaction modules in a pyramid formation.
This innovative approach, combined with new scalable offline feature infrastructure, processes sequences containing thousands of events with minimal storage cost. By modeling these extended user behavior sequences, GEM develops a deeper, more accurate understanding of each user’s purchase journey, recognizing patterns that might span multiple sessions or platforms.
Enabling Cross-Feature Learning
Traditional methods often compress user behavior sequences into compact vectors for downstream processing, risking the loss of critical engagement signals. GEM takes a different approach by preserving full sequence information while still enabling efficient cross-feature learning.
The InterFormer architecture employs parallel summarization with an interleaving structure that alternates between sequence learning and cross-feature interaction layers. This design allows the model to progressively refine its sequence understanding while maintaining access to the complete user journey, ensuring that even complex, multi-step behavioral patterns remain intact throughout processing.
Multi-Domain Learning with Domain-Specific Optimization
Different Meta platforms—Facebook, Instagram, Business Messaging—each exhibit unique user behaviors and interaction patterns. Traditional ad recommendation systems struggle to balance learning across this diverse ecosystem, either treating each surface in isolation (missing valuable cross-platform insights) or identically (ignoring platform-specific behaviors).
GEM solves this through sophisticated multi-domain learning that extracts insights from cross-surface user interactions while ensuring predictions remain tailored to each platform’s unique characteristics. For example, GEM might use patterns observed in Instagram video ad engagement to improve Facebook Feed ad predictions, while still optimizing each platform’s predictions for its specific objectives like clicks or conversions.
Maximizing Knowledge Transfer: GEM’s Post-Training Techniques
GEM only creates real-world impact when its knowledge efficiently transfers to the hundreds of user-facing vertical models that power Meta’s advertising products. The company has developed a comprehensive suite of post-training techniques to ensure GEM’s wisdom permeates the entire advertising system.
Advanced Knowledge Distillation
In complex advertising systems, vertical models often suffer from stale supervision—delays between foundation model training and real-world application create misalignments between GEM’s predictions and each vertical model’s specific objectives. These timing and domain mismatches can gradually degrade student model accuracy and adaptability.
To address this challenge, Meta employs a Student Adapter during training—a lightweight component that refines the teacher’s outputs using the most recent ground-truth data. This adapter learns a transformation that better aligns teacher predictions with observed outcomes, ensuring student models receive up-to-date, domain-relevant supervision throughout their training process.
Strategic Representation Learning
Representation learning enables models to automatically derive meaningful, compact features from raw data, supporting more effective performance on downstream tasks like ad click prediction. This approach complements knowledge distillation by generating semantically aligned features that facilitate efficient knowledge transfer from teacher to student models.
Through representation learning, GEM improves foundation-to-vertical model transfer efficiency without adding inference overhead, meaning the entire system becomes smarter without sacrificing speed or increasing computational costs during real-time ad serving.
Efficient Parameter Sharing
Parameter sharing allows multiple models or components to reuse the same parameter sets, reducing redundancy while improving efficiency and knowledge transfer. In GEM’s ecosystem, this technique enables efficient knowledge reuse by allowing vertical models to selectively incorporate components from foundation models.
This approach lets smaller, latency-sensitive vertical models leverage the rich representations and pre-learned patterns of foundation models without incurring their full computational cost, creating a more efficient and responsive advertising system overall.

Together, these three techniques form a comprehensive knowledge transfer ecosystem that ensures GEM’s advanced capabilities benefit the entire advertising infrastructure, ultimately delivering more relevant and personalized ad experiences to users across Meta’s platforms.
The Engineering Marvel: Training GEM at Scale
Training a model of GEM’s magnitude represents a monumental engineering challenge that required completely rethinking traditional training approaches and infrastructure. The scale of this undertaking matches what’s typically seen only with modern large language models.
Distributed Training Strategies
Training GEM requires carefully orchestrated parallelism strategies across both dense and sparse model components. For the dense parts of the model, techniques like Hybrid Sharded Distributed Parallel optimize memory usage and reduce communication costs, enabling efficient distribution of dense parameters across thousands of GPUs.
Meanwhile, the sparse components—primarily large embedding tables for user and item features—employ a two-dimensional approach using data parallelism and model parallelism, specifically optimized for synchronization efficiency and memory locality. This balanced approach ensures all model components train efficiently regardless of their structural characteristics.
System-Level GPU Optimization
Beyond parallelism, Meta implemented numerous techniques to maximize GPU compute throughput and eliminate training bottlenecks:
-
Custom in-house GPU kernels designed for variable-length user sequences and computation fusion, leveraging the latest GPU hardware capabilities -
Graph-level compilation in PyTorch 2.0 that automates key optimizations, including activation checkpointing for memory savings and operator fusion for improved execution efficiency -
Memory compression techniques like FP8 quantization for activations and unified embedding formats to reduce memory footprint -
GPU communication collectives that operate without utilizing Streaming Multiprocessor resources via NCCLX, eliminating contention between communication and compute workloads
These optimizations work together to ensure GPU resources operate at peak efficiency throughout the training process, avoiding the resource underutilization common in large-scale model training.
Minimizing Training Overhead
To improve training agility and reduce GPU idleness, the team focused on optimizing effective training time—the proportion of training time actually spent processing new data. Through improvements to trainer initialization, data reader setup, checkpointing, and PyTorch 2.0 compilation, job startup time was reduced by 5x.
Notably, PyTorch 2.0 compilation time saw a 7x reduction through intelligent caching strategies, allowing researchers to iterate more quickly and test new ideas with less computational waste.
Lifecycle GPU Efficiency Optimization
GPU efficiency optimization extends across all stages of GEM’s development lifecycle—from early experimentation to large-scale training and post-training deployment. During the exploration phase, lightweight model variants enable rapid iteration at a fraction of the cost of full-sized models, supporting over half of all experiments with minimal resource overhead.
During post-training, the model runs forward passes to generate knowledge—including labels and embeddings—for downstream models. Unlike typical large language models, GEM also performs continuous online training to keep foundation models current. Enhanced traffic sharing between training, post-training knowledge generation, and downstream model operations further reduces computational demands.
The Future Direction of Advertising Foundation Models
The evolution of advertising recommendation systems will be defined by increasingly sophisticated understanding of user preferences and intent, making each interaction feel genuinely personal. For advertisers, this translates to one-to-one connections at scale, driving stronger engagement and better outcomes.
Looking ahead, GEM will expand its learning to encompass Meta’s entire ecosystem, including user interactions with both organic and advertising content across text, images, audio, and video modalities. These learnings will extend to all major surfaces across Facebook and Instagram, creating a more unified understanding of user preferences.
This enhanced multimodal foundation will help GEM capture the nuances behind clicks, conversions, and long-term value, paving the way for a unified engagement model that can intelligently rank both organic content and ads. This integrated approach delivers maximum value for both users and advertisers by ensuring the most relevant content appears in each context.
Meta plans to continue scaling GEM and training on even larger clusters by advancing its architecture and refining training approaches for the latest AI hardware. This will enable the model to learn efficiently from increasingly diverse data modalities while delivering ever-more precise predictions.
Future iterations of GEM will also incorporate reasoning capabilities with inference-time scaling to optimize compute allocation, power intent-centric user journeys, and enable intelligent, insight-driven advertiser automation that drives higher return on ad spend.
Frequently Asked Questions About GEM
What exactly is GEM and how does it improve ad recommendations?
GEM is Meta’s Generative Ads Recommendation Model, a foundation model built using large language model principles specifically for advertising applications. It improves ad recommendations through three key innovations: a scalable model architecture that’s 4x more efficient than previous systems, advanced knowledge transfer techniques that double the effectiveness of standard knowledge distillation, and a reengineered training infrastructure that delivers 23x more training FLOPS using 16x more GPUs.
How does GEM handle different types of user data?
GEM processes data through two main pathways: sequence features (user activity history) and non-sequence features (user attributes and ad characteristics). The model applies customized attention mechanisms to each feature type while enabling cross-feature learning, allowing it to maintain a comprehensive understanding of user-ad relationships across different data types and timeframes.
How does GEM share its knowledge with other advertising models?
GEM employs both direct and hierarchical knowledge transfer strategies. Direct transfer shares knowledge with major vertical models in familiar data environments, while hierarchical transfer distills GEM’s insights through domain-specific foundation models before they reach specialized vertical models. This approach uses knowledge distillation, representation learning, and parameter sharing to achieve twice the effectiveness of standard knowledge transfer methods.
What technical infrastructure is required to train a model like GEM?
Training GEM requires multi-dimensional parallelism strategies, custom GPU kernels, memory compression techniques, and sophisticated distributed training frameworks. Meta’s training infrastructure delivers a 23x increase in effective training FLOPS while using 16x more GPUs, with model FLOPS utilization improving by 1.43x—demonstrating significantly more efficient hardware usage rather than simply applying more computational resources.
How will GEM shape the future of advertising recommendation systems?
GEM represents a paradigm shift in advertising recommendation systems, enabling more sophisticated understanding of user intent across multiple modalities and platforms. Future developments will see GEM intelligently ranking both organic content and ads within a unified engagement model, while providing advertisers with more automated, insight-driven campaign optimization capabilities that deliver higher returns on advertising investment.
Conclusion
Meta’s Generative Ads Model represents a significant milestone in the evolution of advertising technology. Through its innovative architecture, efficient knowledge transfer framework, and revolutionary training infrastructure, GEM isn’t just improving advertising performance—it’s redefining what’s possible in personalized digital marketing at scale.
As GEM continues to evolve, incorporating more data modalities and refining its reasoning capabilities, it promises to create increasingly valuable experiences for both users and advertisers. In this new era of AI-driven advertising, GEM stands as the central engine powering innovation and effectiveness across the digital marketing landscape.

