

GEN-0: The Embodied Foundation Model That’s Redefining Robotics Intelligence
Introduction: The Missing Piece in AI’s Evolution
We’re living in an era where artificial intelligence has made staggering progress. Large language models can write poetry, solve complex problems, and hold conversations that feel remarkably human. Computer vision systems can identify objects with superhuman accuracy. Yet, when it comes to physical intelligence—the kind that allows a child to catch a ball or a chef to chop vegetables—AI has consistently fallen short.
This disparity isn’t surprising to those familiar with Moravec’s Paradox, which observes that what humans find difficult (like complex mathematics) is often easy for computers, while what humans find effortless (like perception and mobility) proves extremely difficult for machines. For years, robotics has struggled with this fundamental challenge: how to create systems that can operate effectively in the messy, unpredictable physical world.
Today, we’re examining a potential breakthrough that addresses this very problem. Generalist AI’s GEN-0 represents a new class of artificial intelligence—embodied foundation models—that may finally bridge this gap between digital intelligence and physical competence.
What Are Embodied Foundation Models?
To understand GEN-0’s significance, we need to distinguish between traditional AI models and embodied foundation models.
Traditional AI models, including most large language models, process abstract information—text, images, or speech. They exist in a digital realm, manipulating symbols without direct connection to physical reality. An AI can describe how to make a sandwich without ever touching bread or spreading mayonnaise.
Embodied AI, in contrast, concerns itself with physical interaction. It’s about intelligent agents that operate in real environments: grasping objects, navigating spaces, manipulating tools. The difference is akin to knowing the definition of “balance” versus actually riding a bicycle.
GEN-0 belongs to this second category. It’s not just an AI that understands instructions—it’s an AI that can execute complex physical tasks in the real world. Imagine a robot that can assemble a camera kit from start to finish: placing a cleaning cloth into a box, folding a cardboard tray, carefully removing a camera from its plastic bag, positioning it in the box, closing the lid (including that tricky small flap), and disposing of the packaging. GEN-0 performs such tasks seamlessly, without explicit programming for each subtask, operating within a continuous stream of perception and action.
The Historical Challenge: Why Robotics Has Resisted Scaling Laws
In natural language processing, we’ve witnessed the power of scaling laws—the consistent observation that performance improves predictably as models grow larger and training data increases. This principle has driven the remarkable progress in models like GPT-4, PaLM, and others.
Robotics, however, has stubbornly resisted similar scaling. Several fundamental challenges have prevented the establishment of reliable scaling laws in physical AI:
-
The Data Desert: Collecting high-quality robotic interaction data is expensive, time-consuming, and logistically complex. While internet-scale text and image data are readily available, physical interaction data must be painstakingly gathered from real-world operations.
-
The Physics Problem: The real world operates on continuous, complex physical principles that don’t conform to neat digital rules. Friction, gravity, material properties, and unpredictable environments create challenges that don’t exist in purely digital domains.
-
The Real-Time Imperative: In conversation, an AI can take extra milliseconds (or even seconds) to formulate a response. In physical space, hesitation can mean failure—a robot that thinks too long about grasping a moving object will miss its opportunity.
-
The Hardware Heterogeneity Problem: Robots come in different shapes, sizes, and capabilities—from simple robotic arms to complex humanoid systems. Creating models that work across this diverse ecosystem has proven exceptionally difficult.
GEN-0 addresses these challenges head-on, demonstrating for the first time that reliable scaling laws can indeed apply to physical intelligence.
Harmonic Reasoning: Thinking and Acting in Unison
At the heart of GEN-0’s architecture lies its most innovative feature: Harmonic Reasoning. This approach represents a fundamental shift in how AI systems interact with physical environments.
The Physical World Doesn’t Pause for Processing
In digital environments, systems can process, deliberate, and then respond. Chatbots can take extra time to formulate complex answers. But in physical space, the world continues evolving while computation occurs. A robot contemplating its next move while a conveyor belt moves packages past it will quickly find itself overwhelmed.
Harmonic Reasoning solves this fundamental mismatch by enabling the model to process sensory input and generate actions simultaneously within asynchronous, continuous-time streams. Rather than treating perception, planning, and action as separate sequential stages, GEN-0 interweaves them in a harmonious flow that mirrors how biological systems operate in dynamic environments.
Technical Implementation
Without delving too deeply into technical complexities, Harmonic Reasoning involves training models to operate on continuous streams of sensing and acting tokens. The model learns to maintain multiple parallel processes—interpreting sensory data while planning and executing actions—without the traditional separation between “thinking” and “doing.”
This architecture allows GEN-0 to scale to very large model sizes without requiring separate System 1 (fast, instinctive) and System 2 (slow, deliberative) components, or heavy inference-time guidance controllers that can slow down decision-making.
The Intelligence Threshold: Why Size Matters in Physical AI
One of the most striking findings from the GEN-0 research is the existence of a clear “intelligence threshold” in embodied AI. The scaling experiments reveal that model size dramatically affects the ability to absorb and utilize physical interaction data.
The Ossification Phenomenon
Researchers observed a fascinating pattern across different model sizes:
-
1B Parameter Models: These smaller models struggle to absorb complex, diverse sensorimotor data during pretraining. Their weights eventually reach a point where they stop effectively incorporating new information—a phenomenon the researchers term “ossification.” It’s as if the model’s capacity becomes saturated, unable to digest additional training data.
-
6B Parameter Models: At this scale, models begin to show meaningful benefits from pretraining. They develop stronger multi-task capabilities and demonstrate more flexible physical reasoning.
-
7B+ Parameter Models: This appears to be the sweet spot where models fully internalize large-scale robotic pretraining. These larger models can transfer their learning to new tasks with remarkable efficiency—often requiring only a few thousand steps of post-training adaptation.

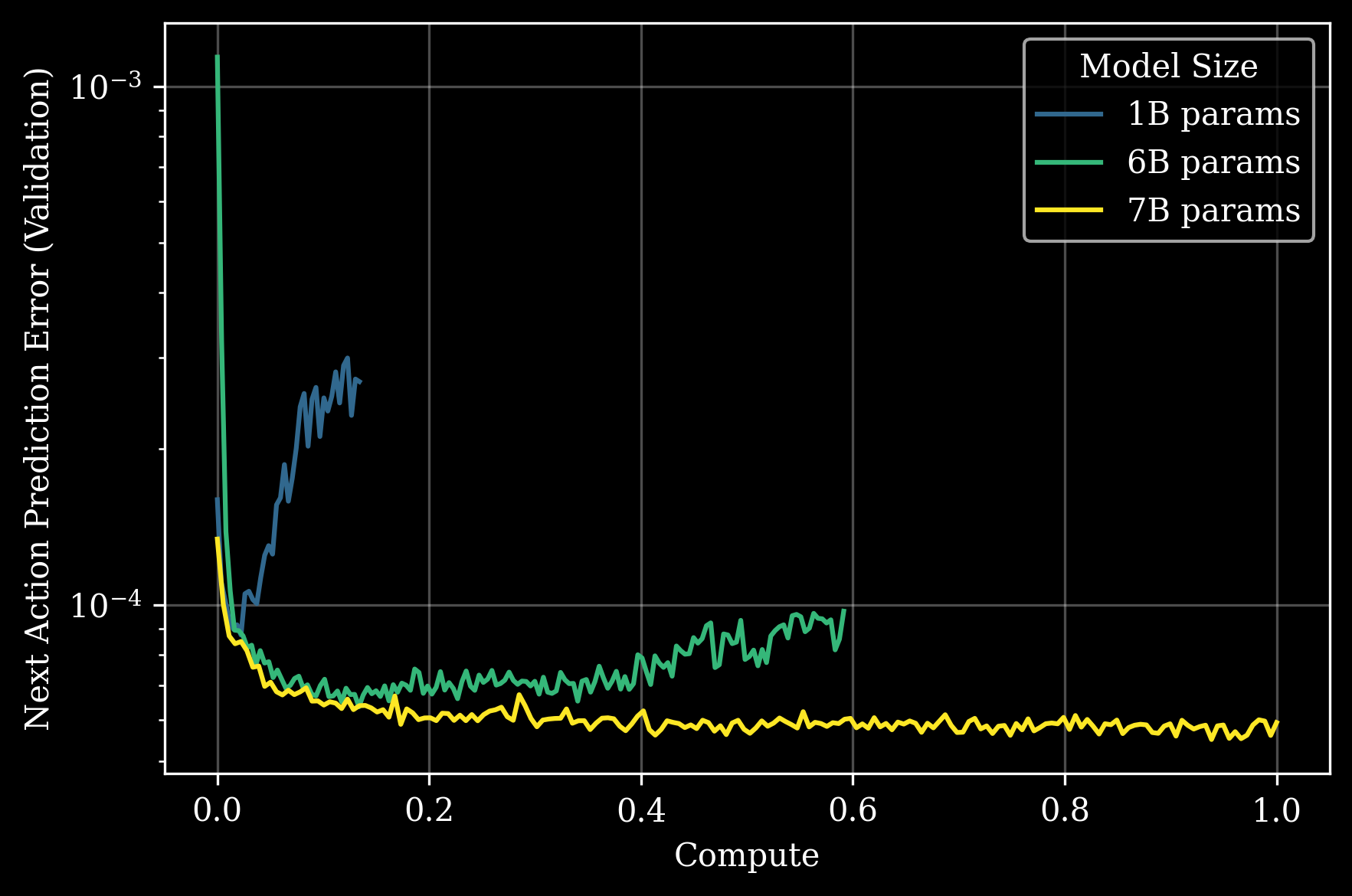
The chart above illustrates this phenomenon clearly. While 1B parameter models quickly plateau in their learning, 6B and 7B models continue improving as pretraining computation increases.
Echoes of Moravec’s Paradox
This scaling pattern provides empirical support for Moravec’s Paradox. The fact that physical intelligence requires larger models than comparable language tasks suggests that what humans find effortless—perception, dexterity, physical intuition—actually demands substantial computational resources when implemented in artificial systems.
The research team suggests that intelligence in the physical world may have a higher “activation threshold” in terms of compute requirements, and we’re only beginning to explore what becomes possible beyond this threshold.
Establishing Scaling Laws for Robotics
Perhaps the most significant contribution of GEN-0 research is the establishment of reliable scaling laws for embodied AI. For the first time, researchers can predict how improvements in training data and model size will translate to better performance on physical tasks.
The Experimental Framework
To establish these scaling laws, researchers sampled checkpoints from GEN-0 training runs across different subsets of the pretraining dataset. They then post-trained these checkpoints on multi-task, language-conditioned data. This supervised fine-tuning stage spanned 16 distinct task sets, including:
-
Dexterity Tasks: Complex manipulation challenges like building Lego structures -
Industry Workflows: Practical applications like fast food packing -
Generalization Tasks: Open-ended challenges following “do anything” style instructions
Across all these domains, a consistent pattern emerged: more pretraining reliably improved downstream performance during post-training.
The Power Law Relationship
At sufficient model scale, the relationship between pretraining dataset size and downstream validation error follows a predictable power law of the form:
L(D) = (Dc/D)^αD
Where:
-
D represents the number of action trajectories in pretraining -
L(D) represents the validation error on a downstream task -
Dc and αD are constants specific to the task
This mathematical relationship enables practical engineering decisions. Robotics teams can now estimate:
-
How much pretraining data they need to reach a target level of performance -
How additional pretraining data might reduce the need for task-specific fine-tuning -
The optimal allocation of computational resources between pretraining and fine-tuning

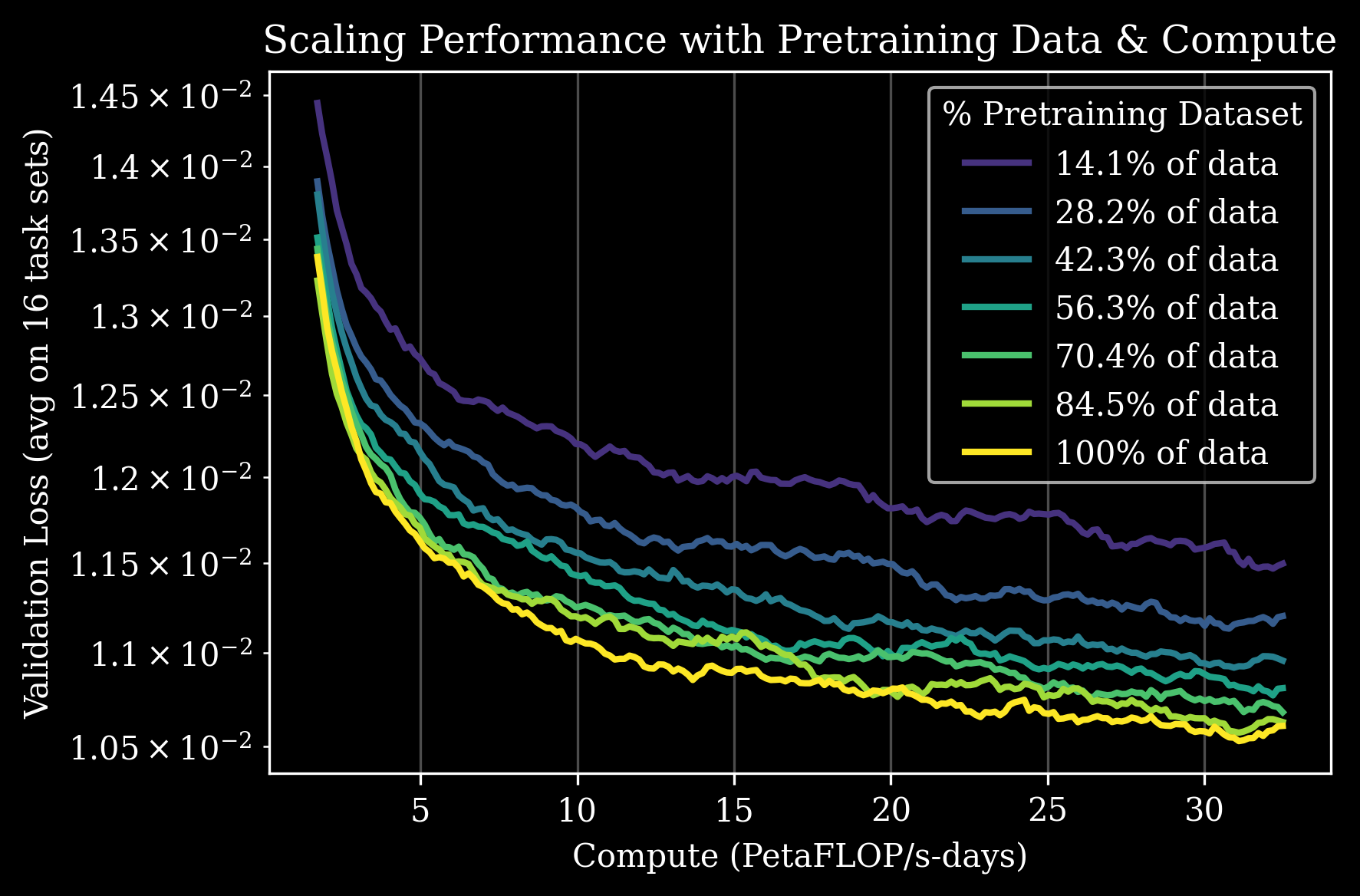

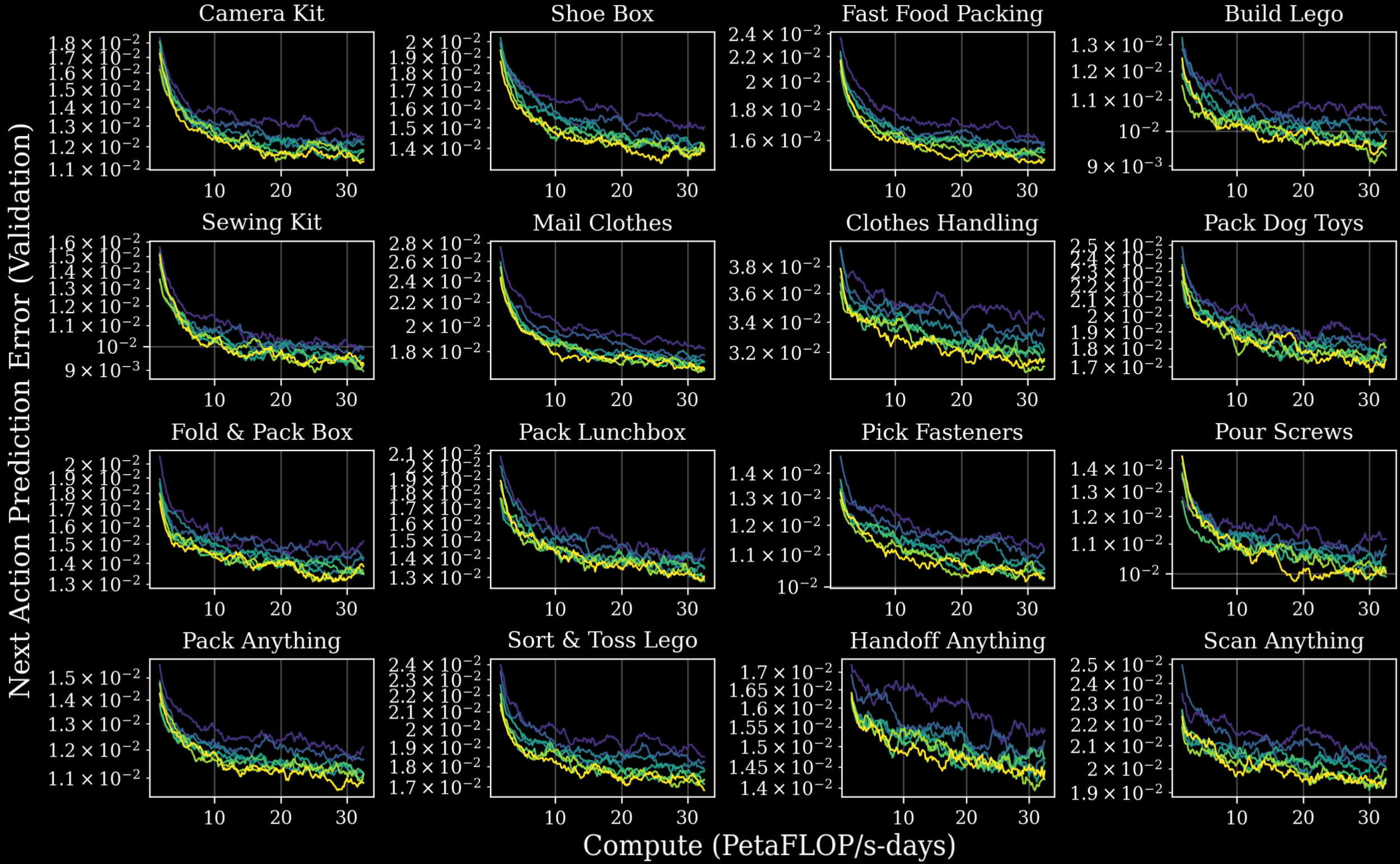
The charts above demonstrate how increased pretraining data (represented by different colors) improves model performance across all 16 task sets, both in terms of validation loss and next-action prediction error.

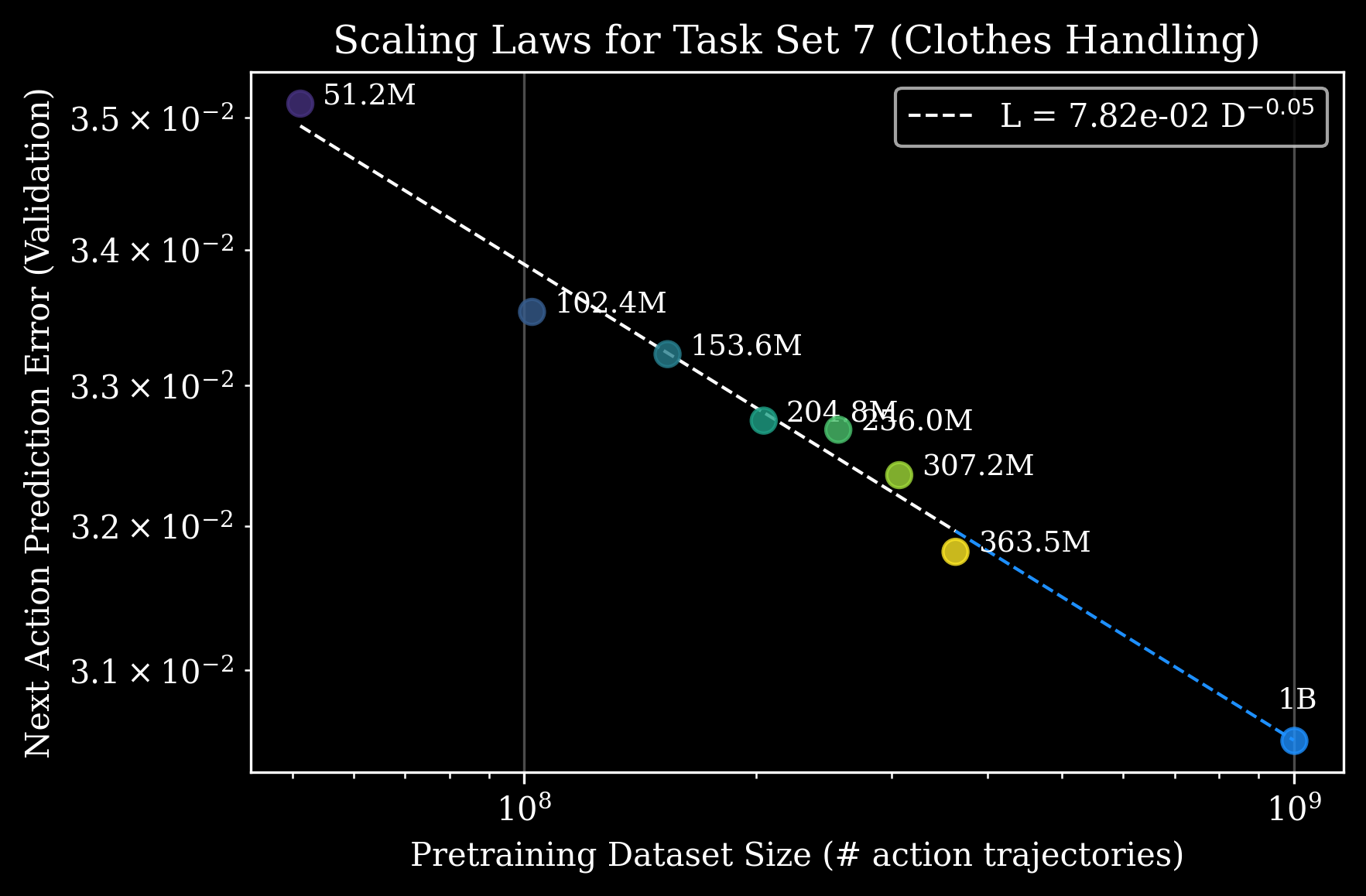
The clothing handling task example shows how these scaling laws enable performance predictions for specific applications, helping teams set realistic data collection targets for desired performance levels.
The Data Engine: Fueling the Robotics Revolution
GEN-0’s capabilities are built on an unprecedented foundation of real-world physical interaction data. The scale and diversity of this dataset represent a quantum leap beyond previous efforts in robotics AI.
Unprecedented Scale
The GEN-0 training corpus comprises:
-
270,000 hours of real-world manipulation trajectories -
Collected across thousands of homes, warehouses, and workplaces worldwide -
Growing at a rate of over 10,000 new hours per week (and accelerating)
To put this in perspective, this dataset is orders of magnitude larger than any previous real-world robotics dataset.

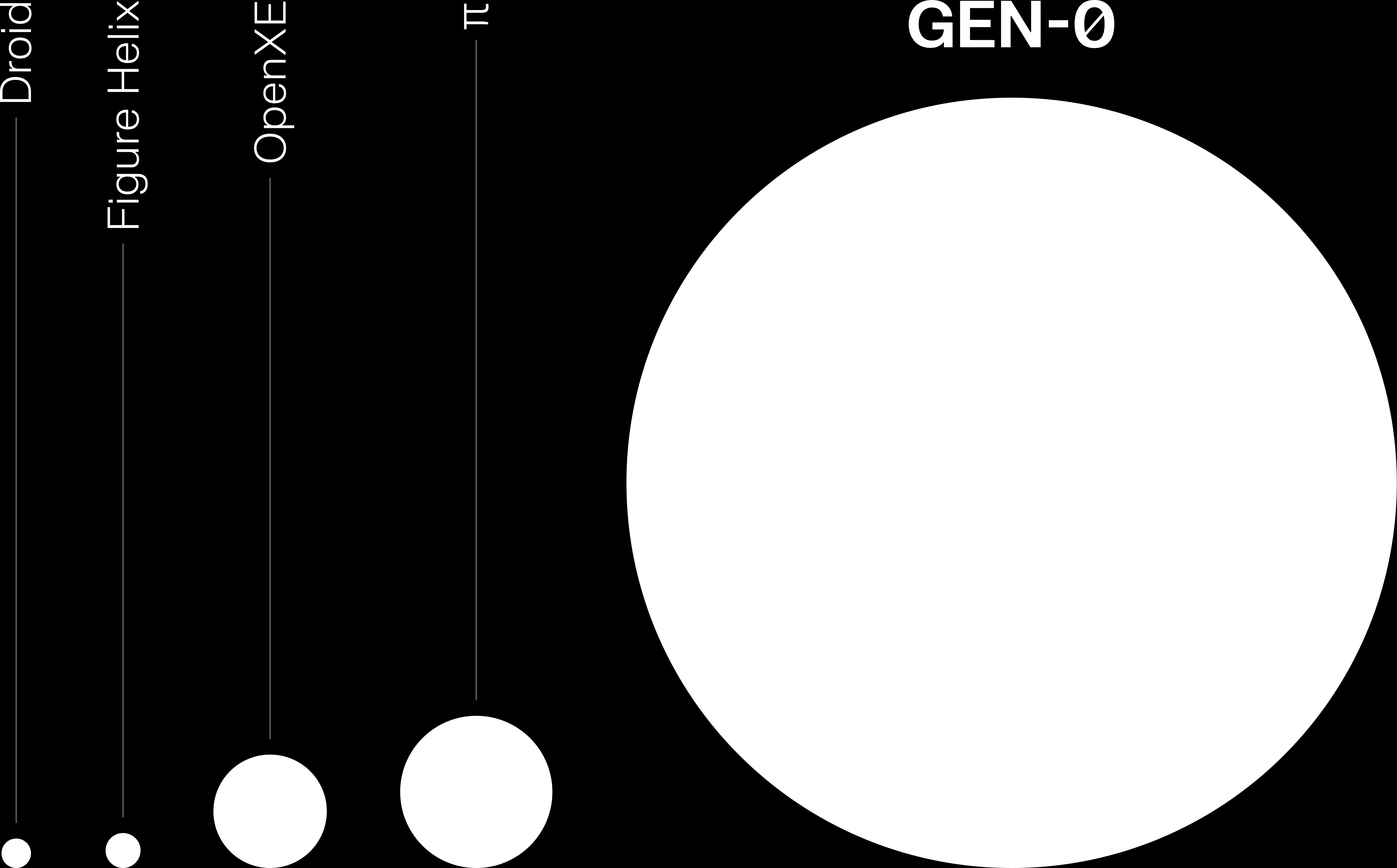
The visualization above illustrates how GEN-0’s training data dwarfs previous robotics datasets.
The “Universe of Manipulation”
The team isn’t just collecting massive amounts of data—they’re building a comprehensive “universe of manipulation” that spans virtually every type of physical task humans perform. This includes everything from peeling potatoes and threading bolts to operating in specialized environments like bakeries, laundromats, factories, and warehouses.
To navigate this vast dataset, the team has developed sophisticated internal tools that allow researchers to explore the data space visually. Using t-SNE maps of language label embeddings, users can search for specific types of manipulation tasks and instantly retrieve relevant video examples from the dataset.
Infrastructure at Scale
Supporting data operations of this magnitude requires extraordinary engineering effort. The team has built:
-
Custom hardware and data-loaders optimized for robotic data processing -
Dedicated network infrastructure, including new internet lines to handle uplink bandwidth from global data collection sites -
Multi-cloud contracts and custom upload machines to manage data flow -
Approximately 10,000 compute cores dedicated to continuous multimodal data processing -
Compression systems handling dozens of petabytes of data
This infrastructure enables what the team calls “internet-scale robot data” processing—a system capable of absorbing the equivalent of 6.85 years of real-world manipulation experience every single training day.
The Science of Pretraining: Data Quality Matters
While scale is crucial, the GEN-0 research reveals that data quality and diversity are equally important. Through large-scale ablation studies across 8 different pretraining datasets and 10 long-horizon task sets, the team discovered that not all data contributes equally to model capabilities.
Measuring Model Characteristics
Researchers evaluated models using two key metrics:
-
Validation Prediction Mean Squared Error (MSE)
-
Measures how closely the model’s predicted actions match ground truth actions -
Lower values indicate better accuracy
-
-
Reverse Kullback-Leibler (KL) Divergence
-
Measures how well the model’s action distribution matches the demonstration data distribution -
Lower values indicate the model is less “overconfident” in incorrect actions
-
Data Mixtures Create Different Model Behaviors
The experiments revealed that different pretraining data mixtures produce models with distinct characteristics:
-
Models with low MSE and low reverse KL tend to perform better with supervised fine-tuning for post-training -
Models with high MSE but low reverse KL exhibit more multimodal action distributions, making them better starting points for reinforcement learning
These findings have practical implications for data collection strategies. By carefully designing data mixtures, teams can steer model development toward specific capabilities and training approaches.
Partner Data Classification
The research categorized data from different collection partners into three classes:
-
Class 1: Task-specific data focused on particular skills -
Class 3: “Do anything” type data emphasizing generalization -
Class 2: Data representing the spectrum between specific and general
Experiments with these different data classes enable continuous improvement of data collection strategies, helping determine what types of data most effectively improve model performance for different applications.
Cross-Embodiment Design: One Architecture, Multiple Robots
A crucial feature of GEN-0’s architecture is its cross-embodiment capability—the same model can operate across different robotic platforms without architectural changes.
Tested Across Diverse Platforms
The GEN-0 architecture has been successfully tested on:
-
6DoF (Degree of Freedom) robotic arms -
7DoF robotic arms with more flexible movement -
16+DoF semi-humanoid systems with complex body-like structures
This flexibility is significant because it means a single pretraining run can produce models that serve heterogeneous robot fleets, dramatically reducing development and deployment costs.
Abstract Action Representations
The cross-embodiment capability works by learning abstract representations of actions and perceptions that aren’t tied to specific robot kinematics. Rather than learning “how to move joint 3 by 15 degrees,” the model learns higher-level concepts like “grasp the object securely” that can be adapted to different physical implementations.
GEN-0 in Action: Real-World Task Performance
The true measure of any robotic system is its performance on actual tasks. GEN-0 has demonstrated remarkable capabilities across a range of challenging domains.
Long-Horizon Dexterous Tasks
The camera kit assembly task mentioned earlier represents exactly the kind of challenge that has traditionally stumped robotic systems. It requires:
-
Long-horizon planning: Executing a sequence of 7+ distinct steps -
Fine motor control: Handling small, delicate objects like camera components -
Adaptation: Dealing with variations in object positioning and environmental conditions -
Continuous operation: Maintaining progress without explicit subtask segmentation
What’s particularly impressive is that GEN-0 accomplishes this without maintaining explicit representations of subtasks or using hand-crafted state machines—it operates through a continuous stream of harmonic reasoning from start to finish.
Industry-Relevant Applications
Beyond laboratory demonstrations, GEN-0 has been tested on practical applications across multiple industries:
-
Apparel: Sorting, unscrambling, buttoning, and hanging clothes in real workplace environments -
Manufacturing: Assembly tasks requiring precision and repeatability -
Logistics: Packing and handling operations common in warehouse settings -
Electronics: Handling delicate components without damage
The scaling laws established through GEN-0 research enable teams to predict performance improvements as more task-specific data becomes available, making it possible to set realistic deployment timelines for commercial applications.
Implications and Future Directions
GEN-0 represents more than just a technical achievement—it points toward a fundamental shift in how we develop robotic intelligence.
From Specialized to General Embodied Intelligence
Traditional robotics has focused on creating specialized systems for specific tasks. GEN-0 demonstrates the feasibility of a different approach: developing general embodied intelligence that can adapt to diverse challenges with minimal additional training.
The Path to Human-Level Physical Intelligence
The established scaling laws suggest a clear path forward. While current models are impressive, they represent just the beginning. As datasets grow from hundreds of thousands to millions of hours, and as model architectures continue to improve, we can anticipate steady progress toward more human-like physical competence.
Industry Transformation
The implications span virtually every sector that involves physical work:
-
Manufacturing: More flexible, adaptive production lines -
Logistics and Warehousing: Systems that handle unexpected situations gracefully -
Healthcare: Robotic assistance with patient care and rehabilitation -
Home and Service Robotics: Systems that operate effectively in unstructured human environments -
Agriculture: Robots that can handle delicate harvesting operations
Frequently Asked Questions
How is GEN-0 different from traditional robotics approaches?
Traditional robotics typically involves carefully engineered systems designed for specific tasks in controlled environments. GEN-0 represents a foundation model approach—a general-purpose physical intelligence that can be adapted to various tasks with minimal additional training, much like how large language models can be adapted to different writing tasks.
What makes Harmonic Reasoning special compared to other robot control methods?
Most robotic systems separate perception, planning, and action into distinct stages. Harmonic Reasoning interweaves these processes in a continuous flow, allowing the system to operate more naturally in dynamic environments where conditions change rapidly. This approach more closely resembles how biological systems interact with the world.
Why do smaller models experience “ossification”?
Ossification occurs when a model’s capacity is insufficient to absorb the complexity and diversity of the training data. It’s analogous to trying to pour a gallon of water into a pint-sized container—the excess simply can’t be contained. Larger models have more “room” to organize and integrate the complex patterns present in physical interaction data.
How much data is needed to achieve human-level manipulation skills?
While the exact amount is unknown, the scaling laws established by GEN-0 research provide a framework for estimation. Based on current trends, achieving truly human-level manipulation across diverse tasks will likely require orders of magnitude more data than the current 270,000-hour dataset. However, the power law relationships mean we can predict progress and identify the most efficient paths toward this goal.
Can GEN-0 be applied to any robot?
The cross-embodiment design means GEN-0 can potentially work across diverse robotic platforms, from simple arms to complex humanoid systems. However, successful deployment requires appropriate fine-tuning and potentially some platform-specific adaptation, particularly for systems with unique kinematic structures or sensor suites.
How does data quality affect the final model?
The research shows clearly that data quality and diversity significantly impact model capabilities. Different data mixtures produce models with different strengths—some may excel at precise manipulation while others show better generalization to novel situations. Careful data curation is as important as data quantity.
Conclusion: The Dawn of Scalable Physical Intelligence
GEN-0 represents a watershed moment for robotics and embodied AI. For the first time, we have compelling evidence that physical intelligence can scale predictably with data and compute, following reliable mathematical laws similar to those that transformed natural language processing.
The combination of Harmonic Reasoning, cross-embodiment design, and internet-scale data operations creates a foundation for rapid progress in physical AI. As datasets continue to grow and model architectures refine, we can anticipate steady improvements in robotic capabilities across virtually every domain that involves physical interaction.
What makes this development particularly significant is its timing. As industries worldwide face labor shortages and the need for increased productivity, scalable robotic intelligence offers a path forward. The established scaling laws mean that investments in data collection and model development can now be made with reasonable confidence in the outcomes.
We’re standing at the beginning of a new era in artificial intelligence—one where machines not only think but act intelligently in our physical world. GEN-0 provides our first clear roadmap for this journey, and the destination appears more exciting than we might have imagined.
This analysis is based entirely on technical documentation and research reports from Generalist AI’s GEN-0 project. All information comes from publicly available sources, and no external knowledge has been incorporated.

