

Theoretical Limits of Embedding-Based Retrieval: Why Even State-of-the-Art Models Fail on Simple Tasks
Some retrieval tasks cannot be solved—even with the best embedding models and unlimited data. This isn’t a technical limitation but a fundamental mathematical constraint.
Have you ever wondered why sometimes even the most advanced search engines fail to find documents you know exist? Or why two seemingly related documents never appear together in search results?
The answer might not lie in the algorithms but in the theoretical limitations of embedding-based retrieval technology.
Recent research from Google DeepMind has revealed fundamental constraints in vector embedding-based retrieval systems. The researchers not only provided theoretical proof but also created a dataset called LIMIT to validate their theory—with surprising results: even state-of-the-art embedding models perform poorly on this seemingly simple task.
What Is Embedding-Based Retrieval?
Before we explore these limitations, let’s briefly understand what embedding-based retrieval entails.
Embedding retrieval forms the core of modern information retrieval systems. The basic idea is to convert text (whether queries or documents) into points in a mathematical space (called vectors or embeddings), then find the most relevant results by calculating distances or similarities between these points.
Imagine placing all documents in a vast multidimensional space where similar documents cluster together. When a user enters a query, the system converts it into a point in this space and finds the document points closest to it.
This approach is powerful because it captures semantic similarities beyond mere keyword matching. For example, it understands that “canine” and “dog,” though different words, have similar meanings.
Theoretical Limitations: Why Embedding Dimension Matters
The core finding of this research is: For any given embedding dimension d, there exist certain document combinations that cannot be returned as retrieval results for any query.
What does this mean? Let’s use a simple analogy.
Suppose you can only use two features (like weight and color) to describe fruits. Your descriptive capability is limited. You can say “find a red apple that weighs 100 grams,” but if you need to consider sweetness, origin, and ripeness simultaneously, two features aren’t enough.
Similarly, the embedding dimension d determines how many different “concepts” the model can distinguish. The study shows that as the number of documents n increases, the number of possible combinations the model needs to distinguish grows combinatorially (specifically, the binomial coefficient—the number of ways to choose k documents from n). However, the number of distinct regions an embedding model can represent only grows polynomially with dimension d.
Mathematical Formalization
The researchers precisely described this limitation by formalizing the problem as a matrix rank issue. Assume we have:
-
m queries and n documents -
A true relevance matrix A ∈ {0,1}^{m×n}, where A_ij = 1 indicates document j is relevant to query i
The embedding model maps each query to a vector u_i ∈ R^d and each document to a vector v_j ∈ R^d. Relevance is modeled by the dot product u_i^T v_j, where relevant documents should score higher than irrelevant ones.
The study found that the minimum embedding dimension d required to correctly sort documents is closely related to the sign-rank of the matrix 2A – 1_{m×n}. Specifically:
rank_±(2A - 1_{m×n}) - 1 ≤ rank_rop A ≤ rank_gt A ≤ rank_±(2A - 1_{m×n})
Where rank_rop A is the row-order-preserving rank, and rank_gt A is the globally thresholdable rank.
What does this mean? The higher the sign-rank, the larger the embedding dimension required to accurately capture relevance relationships. For some matrices, the sign-rank can be so high that practically feasible embedding dimensions cannot represent all possible combinations.
Empirical Validation: Free Embedding Experiments
Theory is elegant, but what about practice? The researchers designed ingenious experiments to validate this theoretical limitation.
They created a “free embedding” optimization setup where vectors themselves can be directly optimized through gradient descent. This approach eliminates any constraints imposed by natural language, showing the best possible performance any embedding model could achieve for this problem.
The experimental setup was as follows:
-
Create a random document matrix (size n) and a random query matrix containing all top-k combinations (i.e., size m = C(n, k)) -
Use Adam optimizer and InfoNCE loss function to directly optimize for constraint satisfaction -
Gradually increase the number of documents (thus increasing the binomial number of queries) until optimization can no longer solve the problem (achieve 100% accuracy) -
They call this point the “critical n-value”

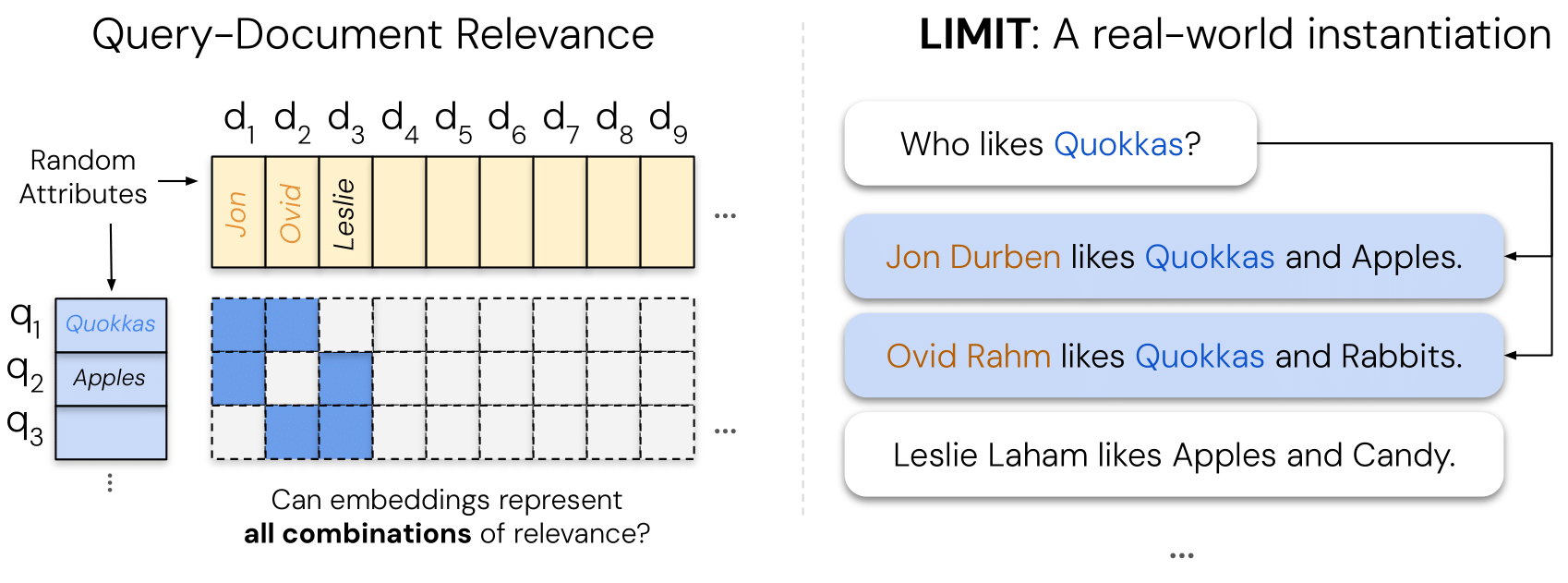
Figure: Critical n-value where the dimension becomes too small to successfully represent all top-2 combinations. The trend line follows a cubic polynomial function.
The results were surprising: even in this optimal scenario, performance drops sharply at a certain point. The curve fits a cubic polynomial function:
y = -10.5322 + 4.0309d + 0.0520d² + 0.0037d³ (r²=0.999)
Extrapolating this curve gives critical n-values for embedding sizes:
-
512 dimensions → 500k documents -
768 dimensions → 1.7 million documents -
1024 dimensions → 4 million documents -
3072 dimensions → 107 million documents -
4096 dimensions → 250 million documents
Please note this is the best-case scenario: real embedding models cannot directly optimize query and document vectors to match the test relevance matrix (and are constrained by factors like “modeling natural language”). These numbers show that for web-scale search, even the largest embedding dimensions with ideal test-set optimization are insufficient to model all combinations.
The LIMIT Dataset: Simple Yet Challenging Task
To test these theoretical limitations in a realistic environment, the researchers created the LIMIT dataset—a seemingly simple but extremely difficult retrieval task.
Dataset Construction
The LIMIT dataset’s construction process is both clever and straightforward:
-
Select attributes: Gather a list of attributes a person might like (such as Hawaiian pizza, sports cars, etc.), obtained by prompting Gemini 2.5 Pro and cleaned to a final 1,850 items -
Create documents: Use 50,000 documents, each assigned a random name and a set of randomly selected attributes -
Design queries: Create 1,000 queries, each asking about only one item (e.g., “Who likes X?”) -
Set relevance: Select 46 documents, using all possible pairs of two documents (C(46,2)=1,035) as relevant document pairs
Despite the task’s simplicity (e.g., “Who likes apples? Jon likes apples”), even state-of-the-art embedding models struggle due to the theoretical foundation, and it’s impossible for models with small embedding dimensions.
Surprising Experimental Results
The researchers evaluated state-of-the-art embedding models, including:
-
GritLM -
Qwen 3 Embeddings -
Promptriever -
Gemini Embeddings -
Snowflake’s Arctic Embed Large v2.0 -
E5-Mistral Instruct
These models range in embedding dimension from 1024 to 4096 and vary in training style (instruction-based, hard negative optimization, etc.). They also evaluated three non-single-vector models for comparison: BM25, gte-ModernColBERT, and token-wise TF-IDF.
The results were startling: Models severely struggle even though the task is simple.
In the full setting, models had difficulty achieving even 20% recall@100. In the 46-document version, models couldn’t solve the task even with recall@20.
Key results include:
| Model | Dimension | Recall@2 | Recall@10 | Recall@100 |
|---|---|---|---|---|
| E5-Mistral 7B | 4096 | 1.3 | 2.2 | 7.3 |
| Snowflake Arctic L | 4096 | 0.4 | 0.8 | 3.3 |
| GritLM 7B | 4096 | 2.4 | 4.1 | 12.9 |
| Promptriever Llama3 8B | 4096 | 3.0 | 6.8 | 18.9 |
| Qwen3 Embed | 4096 | 0.8 | 1.8 | 4.8 |
| Gemini Embed | 3072 | 1.6 | 3.5 | 10.0 |
| GTE-ModernColBERT | default | 23.1 | 34.6 | 54.8 |
| BM25 | default | 85.7 | 90.4 | 93.6 |
Table: Performance results of various models on the LIMIT dataset
Notably, BM25, a sparse retrieval method, performed接近完美ly, while even the best neural embedding models lagged far behind. This emphasizes that the problem’s essence isn’t about understanding semantics but about the theoretical limitation of representing all possible combinations.
Why This Isn’t a Domain Shift Problem
A reasonable question is whether the models’ poor performance stems from domain shift between the queries and the models’ training data.
To test this, the researchers conducted another set of experiments: they took an off-the-shelf embedding model and trained it on either the training set (created using non-test set attributes) or the official test set of LIMIT.
The results showed:
-
Models trained on the training set could not solve the problem -
Models trained on the test set could learn the task, overfitting to tokens in the test queries
This indicates that poor performance is not due to domain shift but rather the intrinsic difficulty of the task itself. Real embedding models couldn’t completely solve the task even with 64 dimensions, showing that real-world models are much more limited than free embeddings, exacerbating the limitations shown in the figure.
Impact of Relevance Patterns
What makes LIMIT difficult is that it tests models on more document combinations than typically used. To verify this, researchers compared four different relevance patterns:
-
Random: Random sampling from all combinations -
Cycle: The next query is relevant to one document from the previous query and the next document -
Disjoint: Each query is relevant to two new documents -
Dense: Uses the maximum number of connections for the largest number of documents that fit in the query set (n choose k)
The results were clear: All patterns except dense showed relatively similar performance. Switching to the dense pattern showed significantly lower scores across all models: GritLM dropped 50 absolute points in recall@100, while E5-Mistral decreased almost tenfold (from 40.4 to 4.8).
Comparison With Existing Datasets
Existing retrieval datasets typically use static evaluation sets with limited numbers of queries because relevance annotation is expensive for each query. This means the query space used for evaluation is only a tiny sample of potential queries.
For example, the QUEST dataset has 325,000 documents and queries with 20 relevant documents per query, totaling 3,357 queries. The number of unique top-20 document sets that could be returned with the QUEST corpus would be C(325k,20) = 7.1e+91 (larger than the estimated number of atoms in the observable universe, 10^82). Thus, the 3,000 queries in QUEST can only cover an infinitesimally small portion of the relevance combination space.
In contrast, the LIMIT dataset evaluates all top-k combinations for a small number of documents. Unlike QUEST, BrowseComp, and others that use complex query operators, LIMIT selects very simple queries and documents to highlight the difficulty of representing all top-k combinations themselves.
Alternatives to Embedding Models
Given that single-vector embedding models have these limitations, what alternatives exist?
Cross-Encoders
Although unsuitable for large-scale first-stage retrieval, cross-encoders are typically used to improve first-stage results. But is LIMIT challenging for rerankers too?
Researchers evaluated the long-context reranker Gemini-2.5-Pro in the small setting for comparison. They provided Gemini with all 46 documents and all 1,000 queries at once, asking it to output relevant documents for each query in one generation.
They found it could successfully solve 100% of all 1,000 queries in one forward pass. This contrasts sharply with even the best embedding models showing less than 60% recall@2. This indicates that LIMIT is simple for state-of-the-art reranker models because they don’t share the same embedding dimension limitations. However, they remain more computationally expensive than embedding models and thus cannot be used for first-stage retrieval with large document collections.
Multi-Vector Models
Multi-vector models achieve greater expressiveness by using multiple vectors per sequence combined with the MaxSim operator. These models show promise on the LIMIT dataset, scoring significantly higher than single-vector models despite using smaller backbones (ModernBERT).
However, these models aren’t typically used for instruction-following or reasoning-based tasks, leaving open the question of how well multi-vector techniques will transfer to these more advanced tasks.
Sparse Models
Sparse models (including lexical and neural versions) can be considered single-vector models but with very high dimensionality. This high dimensionality helps BM25 avoid the problems of neural embedding models, as shown in the results. Because their vector dimension d is high, they can scale to many more combinations than their dense vector counterparts.
However, how to apply sparse models to instruction-following and reasoning-based tasks remains unclear, as these tasks lack lexical or even paraphrase-like overlap. This direction is left for future work.
Practical Implications and Future Directions
This research has profound implications for the information retrieval field:
-
Evaluation Design: Academic benchmarks test only a small fraction of possible queries (and these queries are often overfitted to), hiding these limitations. Researchers should be aware of these constraints when designing evaluations.
-
Model Selection: When attempting to create models that handle the full range of instruction-based queries (i.e., any query and relevance definition), alternative retrieval methods should be chosen—such as cross-encoders or multi-vector models.
-
Theoretical Awareness: The community should recognize that as tasks given to embedding models require returning increasingly complex top-k relevant document combinations (e.g., through logical operators connecting previously unrelated documents), we will reach combination limits they cannot represent.
-
Future Research: New methods need to be developed to address this fundamental limitation, potentially including hybrid retrieval systems, dynamic embedding dimensions, or completely different retrieval paradigms.
Frequently Asked Questions
What is embedding-based retrieval?
Embedding-based retrieval is a modern information retrieval approach that converts text into vector representations in mathematical space, finding the most relevant results by calculating similarities between vectors. This method captures semantic similarities beyond mere keyword matching.
Why do embedding-based retrieval systems have theoretical limitations?
Because the embedding dimension d is fixed, while the number of possible relevant document combinations grows combinatorially with the number of documents. Therefore, for any given embedding dimension, there will always be some document combinations that cannot be returned as retrieval results for any query. This is a fundamental mathematical limitation, not a technical implementation issue.
Why is the LIMIT dataset difficult?
The LIMIT dataset tests models on more document combinations than typically used. It employs a “dense” relevance pattern that uses the maximum number of connections for the largest number of documents that fit in the query set (n choose k), making it particularly challenging despite the seemingly simple task.
How do state-of-the-art embedding models perform on LIMIT?
Even state-of-the-art embedding models perform poorly on LIMIT, struggling to achieve even 20% recall@100 in the full setting and failing to solve the task even with recall@20 in the 46-document version. Performance heavily depends on embedding dimension, with larger dimensions performing better.
What alternatives can overcome these limitations?
Alternatives include cross-encoders (computationally expensive but perform well), multi-vector models (more expressive than single-vector models), and sparse models (like BM25, with very high dimensionality). Each approach has its trade-offs and must be selected based on specific application scenarios.
Do these limitations affect practical applications?
Yes. As instruction-following retrieval grows, users may create increasingly complex queries connecting previously unrelated concepts, making these limitations more apparent. Retrieval system designers need to be aware of these constraints and use alternative methods when appropriate.
Conclusion
This research reveals fundamental limitations of vector embedding-based retrieval systems. Through theoretical analysis and empirical validation, researchers have shown that for any given embedding dimension d, there exist document combinations that cannot be returned as retrieval results for any query.
The LIMIT dataset they created presents significant challenges even for state-of-the-art models, highlighting the constraints of the current single-vector embedding paradigm. These findings suggest that the community should consider how instruction-based retrieval affects retrievers, as there will be top-k document combinations that cannot be represented.
Future research directions include developing more expressive retriever architectures, better understanding the sign-rank of practical relevance matrices, and designing evaluation benchmarks that account for these limitations.
This work not only advances our understanding of the theoretical foundations of embedding retrieval but also points the way toward developing more powerful and reliable retrieval systems in the future.
This article is based on the Google DeepMind research paper “On the Theoretical Limitations of Embedding-based Retrieval.” For more technical details and experimental data, please refer to the original paper and GitHub repository.

