

As someone who spends most days squinting at 18th-century handwritten archives, I recently experienced something that sent a professional shiver down my spine. It started with a subtle change in Google AI Studio—users began noticing occasional A/B tests where two answers appeared side-by-side, asking them to select the better one. This kind of testing typically precedes major model releases, and the leaked capabilities might mark AI’s transition from quantitative improvement to qualitative transformation.
This post shares how I accidentally accessed this mysterious model and witnessed what can only be described as near-autonomous reasoning in handwritten historical document analysis. Every detail comes directly from my test logs—no external information added.
Why Handwriting Recognition Became AI’s Ultimate Benchmark
It’s Not Just “Reading Images”—It’s Time Travel
Most people assume transcribing historical handwriting is a vision problem. That’s only half true. When you open a merchant’s letter from 1760, you’re entering a foreign country where:
-
Spelling is chaotic: A single word might appear three different ways in one paragraph -
Units are archaic: £6/15/0 means 6 pounds, 15 shillings, 0 pence—a non-decimal system that breaks modern brains -
Context is everything: Was the writer’s name Richard Darby or Derby? Without period knowledge, you’re guessing -
Scripts are alien: The long s (ſ) looks like f, so “leſs” could be “leff”?
This creates a unique AI testing ground where vision, language understanding, and logical reasoning must work in perfect sync. Drop any ball and expert-level accuracy becomes impossible.
LLMs’ Built-In Handicap: When Probability Works Against Reality
To appreciate this breakthrough, you need to understand why current models struggle with historical documents.
Large language models are probability machines trained to predict the next most likely token. This works brilliantly for modern text but fails catastrophically on historical documents:
The Core Problems
-
Proper nouns are statistical outliers: Names and places get “corrected” to common words -
Numbers are pure ambiguity: Is it 30 or 80 gallons when ink is smudged? No statistical difference -
Historical “misspellings” get “fixed”: The model’s helpfulness destroys historical authenticity -
Quantities lack context: Faced with “145,” the model can’t infer it means 14 lb 5 oz
Last year, a colleague and I developed a rigorous test set: 50 documents totaling ~10,000 words, carefully selected to avoid training data contamination (we took every reasonable precaution). Even Gemini-2.5-Pro only managed 4% CER and 11% WER—impressive but not yet professional-grade.
| Model Version | Strict CER | Strict WER | CER (excluding punctuation/capitalization) | WER (excluding punctuation/capitalization) |
|---|---|---|---|---|
| Gemini-2.5-Pro | 4.0% | 11.0% | 2.0% | 4.0% |
| New Test Model | 1.7% | 6.5% | 0.56% | 1.22% |
What This Means: The new model gets only 1 character wrong per 200, with errors concentrated in ambiguous punctuation. That’s a 50-70% jump—consistent with scaling law predictions.
How I Accessed the Mystery Model (And How You Can Test It Too)
The Setup Process
Accessing this unreleased model wasn’t straightforward. It required persistence and a specific workflow:
System Prompt Used
"Your task is to accurately transcribe handwritten historical documents, minimizing CER and WER. Work character by character, word by word, line by line, transcribing the text exactly as it appears. Retain spelling errors, grammar, syntax, and punctuation as well as line breaks. Transcribe all text including headers, footers, marginalia, insertions, page numbers, etc. Insert them where indicated by the author. In your final response write "Transcription:" followed only by your transcription."
Step-by-Step Access Method
-
Upload: Use high-resolution images (minimum 2000px width recommended) -
Paste: Input the exact system prompt above -
Send: Submit your request -
The Crucial Part: If you get a single response, manually refresh and resend 30-50 times until the A/B choice interface appears -
Select: Choose the higher-quality transcription
This process is time-consuming, hits rate limits frequently, and is clearly not meant for production use. During a Thanksgiving trip, I only completed five documents (roughly 1,000 words—10% of our full test set).
Documents I Chose: The Hardest of the Hard
To stress-test the model, I selected only the most problematic documents from our set:
-
Illegible scrawls: Near-illiterate handwriting -
Spelling chaos: Documents riddled with grammatical errors and missing punctuation -
Inconsistent capitalization: Pre-standardization English -
Complex formatting: Tables, marginalia, insertions

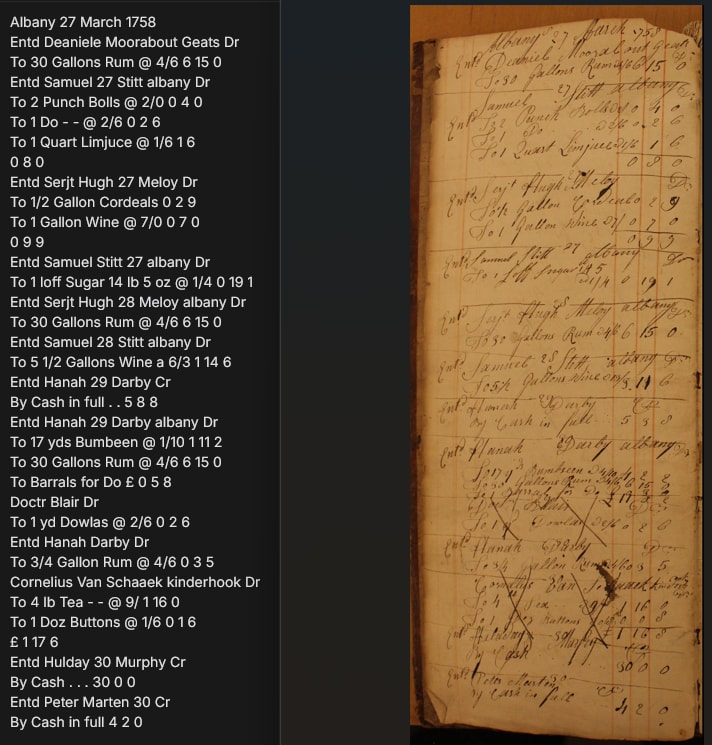
The Moment That Gave Me Chills: AI Solved a 260-Year-Old Accounting Puzzle
The Sugar Loaf Entry That Didn’t Make Sense
After the five test documents, I uploaded a page from a 1758 Albany merchant’s daybook—the type of tabular handwritten data that breaks every previous model. This Dutch clerk’s English was messy, mixed with Dutch words, and used the old £/s/d system with shorthand like “To 30 Gallons Rum @4/6 6/15/0” (30 gallons at 4 shillings 6 pence per gallon = 6 pounds, 15 shillings, 0 pence total).
The model’s transcription was nearly flawless—all numbers correct. But one line made me freeze:
Original: “To 1 loff Sugar 145 @ 1/4 0 19 1”
Model’s Transcription: “To 1 loff Sugar 14 lb 5 oz @ 1/4 0 19 1”
Wait. The document says “145,” not “14 lb 5 oz.” Classic AI hallucination, right? But then I traced the logic.
The AI’s Unprompted Reverse Engineering
This “error” was actually unsolicited autonomous reasoning:
-
Pattern Recognition: 19 previous entries all specified units upfront (30 gallons, 17 yards, 1 barrel). Only the sugar entry had numbers after the description. -
Contextual Inference: From “@ 1/4” (1 shilling 4 pence per unit) and total “0 19 1” (0£ 19s 1d), it deduced 145 must represent weight. -
Multi-Step Calculation: -
1 shilling 4 pence = 16 pence per unit -
0£ 19s 1d = 229 pence total -
229 ÷ 16 = 14.3125 → 14 5/16 → 14 lb 5 oz
-
The model questioned its own transcription, realized “145” was illogical, and back-calculated the only weight that fit the price.
Required reasoning layers:
-
Dual non-decimal systems: Currency (12d=1s, 20s=£1) and weight (16oz=1lb) -
Ambiguous symbol interpretation: A faint mark above the “1” might indicate pounds -
Proactive clarification: It could’ve copied “145” and been done
Comparison: No Other Model Comes Close
Testing the same ledger with current models:
-
GPT-5 Pro: Transcribed as “1 lb 5,” losing critical data -
Gemini-2.5-Pro: Occasionally added “lb” but deleted other digits -
Both require hand-holding: Even when prompted “What does 145 mean?”, they guessed “145 lbs” instead of the correct 14 lb 5 oz
The new model didn’t need prompting. It spontaneously reasoned—a first in my testing.

What This Reveals About Emergent Reasoning in LLMs
The Symbolic Reasoning Debate
The AI community is split: Are LLMs truly “thinking” or just advanced mimics? Skeptics argue they lack explicit symbolic manipulation capacity.
The sugar loaf case challenges this. The model received no explicit rules about 18th-century currency yet performed:
-
Symbol abstraction: Treated £/s/d and lb/oz as operable variables -
Multi-step calculation: Converted across four measurement systems -
Self-verification: Used results to validate inputs
This suggests emergent implicit reasoning—when scale and multimodality cross a threshold, pattern recognition spontaneously organizes into logical structure.
The Tipping Point We Might Be Witnessing
If this proves reliable and replicable (so far, I’ve only triggered it once in hundreds of attempts), the implications are profound:
For Historical Research
-
From transcription to collaboration: AI becomes a research assistant that flags ambiguities -
Mass archival digitization: Millions of unexplored ledgers, letters, and diaries become searchable -
Multilingual barrier broken: Models handle mixed-language documents seamlessly
For AI Development
-
Generalist beats specialist: No need for domain-specific models—general ones master niches automatically -
Scaling laws hold: Capability jumps come from size, not architecture hacks -
Understanding may be emergent: True comprehension could be a spontaneous property of complex systems
FAQ: What Readers Keep Asking Me
Q: Is this definitely Gemini-3?
A: Unconfirmed. Google hasn’t officially acknowledged the test. All evidence comes from collective user observations in AI Studio. Based on the A/B test’s sudden disappearance and performance leap, the community suspects it’s an early Gemini-3 version. But the name matters less than the capability itself.
Q: What does 0.56% CER mean in practical terms?
A: It’s publishable quality. Professional transcription services guarantee 1% WER for clean documents. For messy historical archives, human experts typically score 4-10% WER. The new model enters the top human expert range—thousands of times faster.
Q: Will AI “modernize” documents and destroy historical authenticity?
A: This was my biggest fear. But tests show the model follows “transcribe exactly as written” instructions strictly. All spelling errors and grammar chaos remain intact. Its only “intervention” occurs when logic fails (like the 145 case)—and even then, it clarifies rather than distorts. In practice, you can request both “strict” and “interpretive” versions.
Q: Can researchers use this technology now?
A: Not yet. The A/B window appears closed—I haven’t been able to trigger it again after hundreds of refreshes. Convention suggests public release is 3-6 months away. Once available, transcribing a 20-page ledger will cost mere dollars.
Q: If AI can reason about history, won’t it fabricate narratives?
A: Critical question. In the sugar case, AI used document-internal consistency, not external knowledge. It didn’t hallucinate 18th-century sugar prices—it used the ledger’s own arithmetic. This verifiable reasoning is distinct from speculation. Still, users must treat AI as an assistant, not an authority, and validate all outputs.
Q: What does this mean for history students?
A: Learn AI basics, not engineering. Historians who ignore AI tools will be as limited as those who refuse databases today. The barrier is lowering—focus on what AI can/can’t do and how to verify results, not coding. Start with Digital Humanities courses covering AI applications.
How to Test AI Handwriting Recognition Yourself (Today’s Tools)
While the advanced model remains unreleased, current models are already powerful. Here’s a practical framework to evaluate if they meet your research needs.
Setup Phase
-
Document scanning: Smartphone photos work if lit evenly and text is clear. Aim for 300 DPI minimum -
Curate samples: Pick 3-5 documents with varying legibility to establish a difficulty curve -
Human baseline: Manually transcribe once or compare against published authoritative versions
Testing Protocol (Using Current Gemini-2.5-Pro)
Step 1: Basic Transcription Test
Prompt template:
"Transcribe this handwritten text verbatim:
- Preserve all spelling errors and grammar issues
- Maintain original punctuation and capitalization
- Follow original line breaks
- No explanations or interpretations
- Output must start with 'Transcription:'"
Step 2: Accuracy Assessment
-
Calculate Character Error Rate (CER) and Word Error Rate (WER) using online tools -
Focus on: Proper nouns, numbers, dates—these are deal-breakers -
Note which handwriting styles cause most failures
Step 3: Reasoning Stress Test
Upload a document with tables or calculations (e.g., old ledgers). Check if the model:
-
Recognizes logical relationships between numbers -
Questions implausible data -
Explains symbol meanings (like £/s/d)
Step 4: Cost-Benefit Analysis
Track for each document:
-
Processing time (seconds) -
API cost (token consumption) -
Human proofreading time required
Performance Benchmarks
Minimum Viable (Current GPT-4V/Gemini-1.5 Level)
-
CER < 10% -
Proper noun recognition > 80% -
Number error rate < 15%
Professional Grade (Gemini-2.5-Pro Level)
-
CER < 4% -
Proper noun recognition > 90% -
Basic historical context comprehension
Expert Grade (New Test Model Level)
-
CER < 2% -
Spontaneous logical validation -
Ambiguous symbol interpretation
Actionable Advice for Different Professionals
For Historians & Archivists
-
Immediate: Inventory your handwritten collections for digitization readiness -
6-month plan: Learn basic Python for batch API processing -
Strategic: Rethink research workflows around “AI transcription + human interpretation”
For Librarians & Archive Managers
-
Cost factor: A 20-page handwritten document costs 2.00 to transcribe via API vs. $200+ for human contractors -
Quality control: Implement “AI first pass + volunteer crowd-proofreading” models -
Service innovation: Offer searchable handwritten collections, dramatically increasing institutional value
For AI Practitioners & Researchers
-
Technical validation: Multimodal + scale unlocks unexpected capabilities—handwriting is just the start (medical imaging, engineering diagrams, manuscript restoration) -
Application space: Any domain requiring “vision + reasoning” could see similar leaps -
Ethical readiness: When AI starts “interpreting” not just “recognizing,” we need new usage guidelines
Conclusion: A Tiny Case Study, a Giant Leap
From the 1946 machine that could read handwritten digits to today’s AI capable of reasoning through 18th-century ledgers, the journey spans nearly eight decades. The inflection point might be hidden in that tiny edit: 145 → 14 lb 5 oz.
This tells us three things:
-
Scaling laws haven’t peaked: Keep expanding models and more “impossibilities” become possible -
Generalist AI beats specialist: No need to train separate models for each domain—powerful general models master niches automatically -
Understanding can emerge: Logical reasoning may be a spontaneous property of complex statistical systems, not hand-coded rules
The caveat? Google must release this capability publicly and reliably. Even if this was a one-time fluke, it’s a lighthouse illuminating AI’s next destination.
For everyday users, the practical takeaway is: Stop thinking of AI as a search engine on steroids—it’s becoming a thinking tool. Learning to ask good questions, validate results, and collaborate with AI will be the core skill of the next era.
One final detail: When I first saw the correct sugar loaf transcription, my instinct was to check if AI had accessed external databases. Then I remembered—there are no databases for 1758 Albany merchant records. That’s when I realized we might be at a genuine inflection point. Not because AI is powerful, but because it’s demonstrating the ability to make reasonable inferences from incomplete information—what we thought was uniquely human expert work.
And that ability is the essence of all scholarship.

