

DeepConf: Enhancing LLM Reasoning Efficiency Through Confidence-Based Filtering
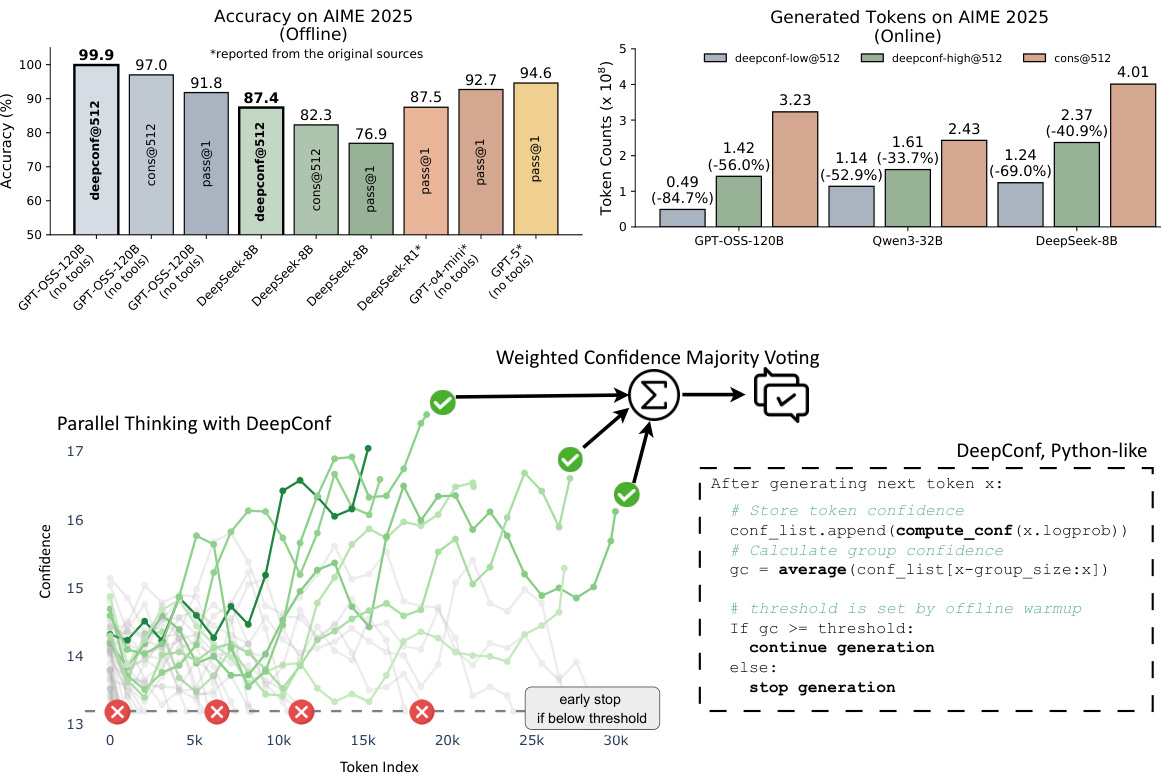
Figure 1: DeepConf system overview showing parallel thinking with confidence filtering

The Challenge of Efficient LLM Reasoning
Large language models (LLMs) have revolutionized complex reasoning tasks, but their computational demands present significant barriers to practical deployment. Traditional methods like majority voting improve accuracy by generating multiple reasoning paths, but suffer from:
-
Diminishing returns: Adding more reasoning paths yields smaller accuracy improvements -
Linear cost scaling: Each additional path increases compute requirements proportionally -
Quality blindness: All reasoning paths receive equal consideration regardless of quality
This article explores DeepConf, a novel approach that leverages internal confidence signals to optimize both reasoning quality and computational efficiency.
Understanding Model Confidence Metrics
DeepConf relies on three key confidence measurements to evaluate reasoning path quality:
1. Token-Level Confidence Indicators
| Metric | Calculation | Interpretation |
|---|---|---|
| Token Entropy | Measures prediction uncertainty at each step | |
| Token Confidence | Quantifies model certainty for top-k token predictions |

Figure 2: Confidence distribution comparison between correct (blue) and incorrect (red) reasoning paths

2. Trace-Level Confidence Aggregations
| Metric | Description | Use Case |
|---|---|---|
| Average Trace Confidence | Mean of all token confidences | Global quality assessment |
| Group Confidence | Sliding window average of token confidences | Localized quality monitoring |
| Bottom 10% Group Confidence | Mean of least confident segments | Identifies critical reasoning failures |
| Tail Confidence | Confidence of final reasoning segment | Captures conclusion reliability |
DeepConf Methodology
The system operates in two complementary modes:
1. Offline Mode: Post-Processing Optimization
Process Workflow:
-
Generate complete reasoning traces (4,096 paths per problem) -
Calculate confidence metrics for each trace -
Apply filtering and weighted voting
Key Techniques:
-
Confidence-Weighted Voting: Assigns higher weights to high-confidence traces -
Top-η% Filtering: Retains only highest-confidence traces (η=10% or 90%)
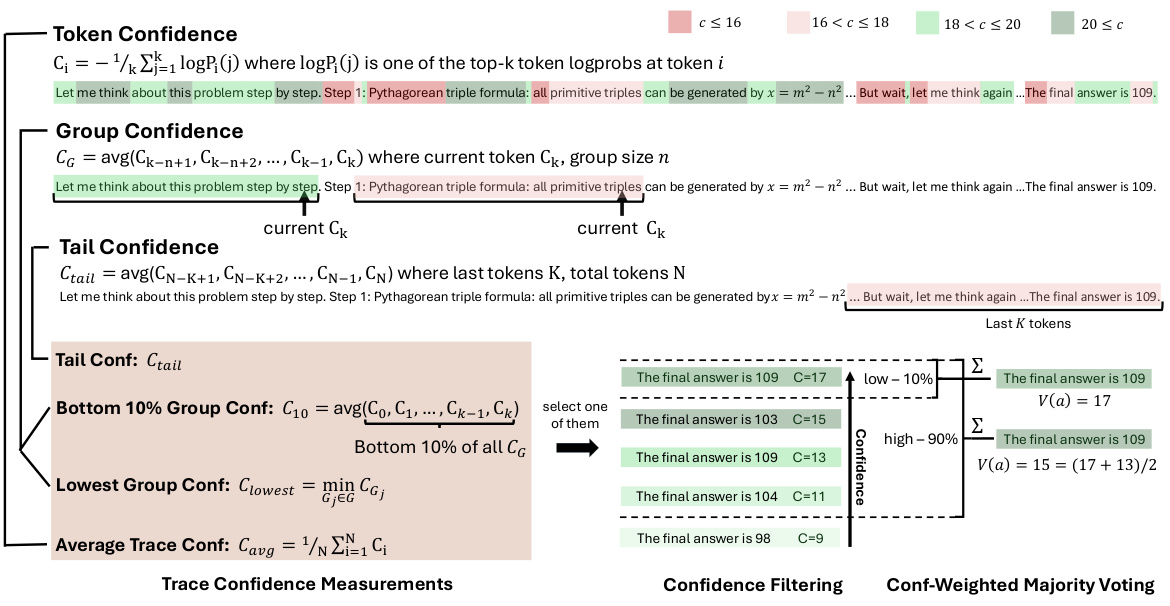
Figure 3: Offline confidence analysis and filtering architecture

2. Online Mode: Real-Time Generation Control
Implementation Strategy:
-
Warmup Phase: Generate initial batch (N=16 traces) to establish confidence baseline -
Dynamic Termination: -
Monitors group confidence during generation -
Stops trace generation when confidence drops below threshold
-
-
Adaptive Sampling: Adjusts total traces based on answer consensus
Algorithm Features:
-
Early stopping prevents wasting compute on low-quality paths -
Maintains accuracy while reducing token generation by up to 84.7% -
Two variants balance efficiency/accuracy tradeoffs
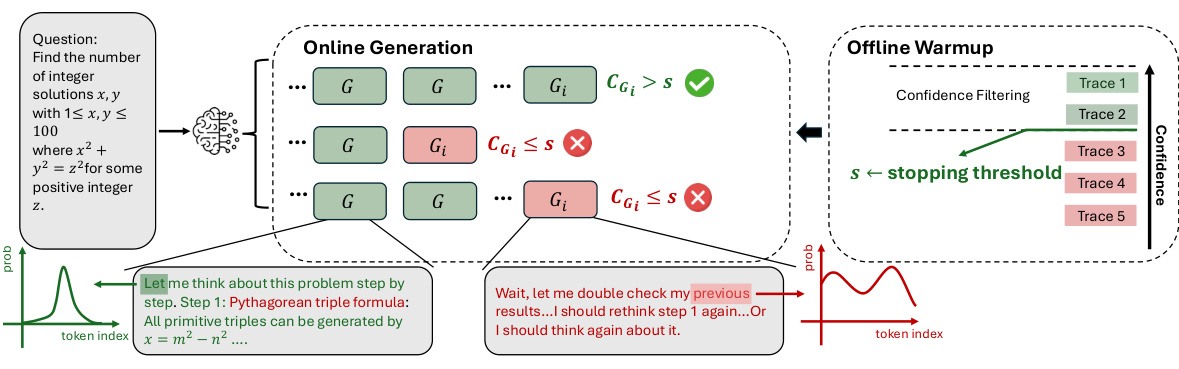
Figure 4: Real-time confidence monitoring during trace generation

Experimental Results
Performance Summary (AIME 2025 Benchmark)
| Model | Method | Accuracy | Token Reduction |
|---|---|---|---|
| GPT-OSS-120B | DeepConf@512 | 99.9% | 84.7% |
| Qwen3-32B | Majority Voting | 80.1% | Baseline |
| DeepSeek-8B | DeepConf-low | 86.4% | 69.0% |
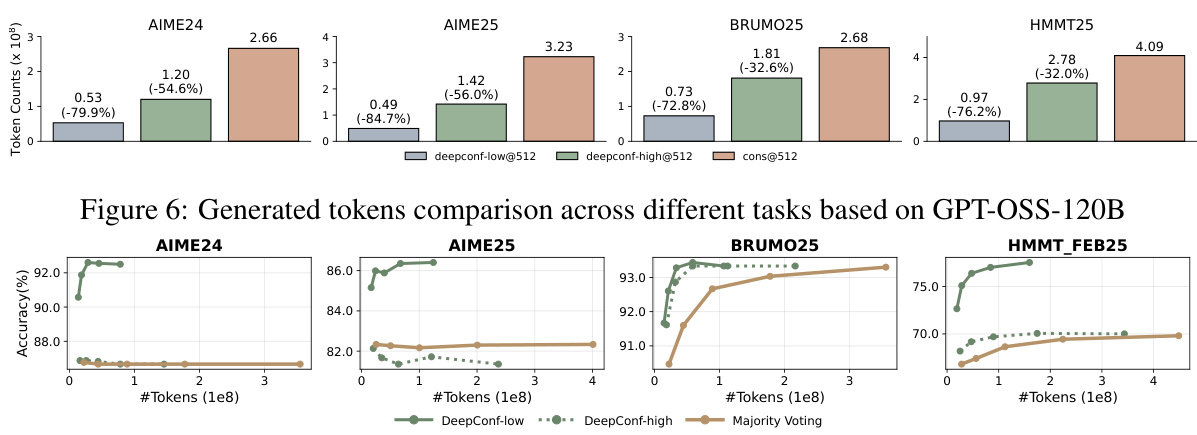
Figure 7: Token efficiency gains while maintaining accuracy

Key Findings:
-
Accuracy Improvements:
-
99.9% on AIME 2025 with GPT-OSS-120B (vs 97.0% baseline) -
9.38 percentage point gain on HMMT 2025 with DeepSeek-8B
-
-
Efficiency Gains:
-
84.7% token reduction on AIME 2025 (GPT-OSS-120B) -
77.9% reduction on AIME 24 (DeepSeek-8B)
-
-
Model Scalability:
-
Consistent improvements across 8B-120B parameter models -
Effective on both mathematical and STEM reasoning tasks
-
Implementation Details
Configuration Parameters
| Parameter | DeepConf-low | DeepConf-high |
|---|---|---|
| Filtering Threshold (η) | 10% | 90% |
| Consensus Threshold (τ) | 0.95 | 0.95 |
| Warmup Traces (N_init) | 16 | 16 |
| Group Window Size | 2048 tokens | 2048 tokens |
Integration with vLLM
Minimal code modifications required:
-
Add confidence tracking to LogprobsProcessor -
Insert early-stop check in output processor -
Enable via API parameters:
response = client.chat.completions.create(
model="gpt-oss-120b",
messages=[{"role": "user", "content": "Solve: x²+5x+6=0"}],
extra_body={
"enable_conf": True,
"window_size": 2048,
"threshold": 17
}
)
Practical Applications
Recommended Use Cases
| Application | Configuration | Expected Benefit |
|---|---|---|
| Real-time Tutoring | DeepConf-low | 60-80% compute savings |
| Technical Documentation | DeepConf-high | <5% accuracy impact |
| Research Assistance | Offline mode | Max accuracy priority |
| Code Generation | 1024-token window | Balance speed/quality |
Future Directions
-
Training Integration: Incorporate confidence signals into RL training -
Error Detection: Address overconfidence on incorrect paths -
Multi-Modal Extension: Apply to image-text reasoning tasks -
Confidence Calibration: Develop better uncertainty quantification
FAQ
Q: Does DeepConf require model retraining?
A: No, it works with existing models through inference-time modifications.
Q: How to choose window size?
A: Use 2048 tokens for math problems, 1024 for code generation.
Q: Is this compatible with Chinese text?
A: Yes, confidence metrics are language-agnostic.
Q: What’s the typical speed-accuracy tradeoff?
A: DeepConf-low reduces tokens by ~70% with accuracy gains in most cases.
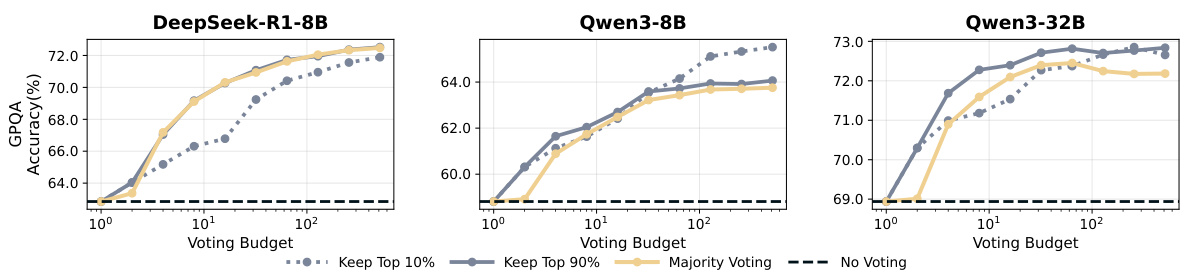
Figure 10: Performance on graduate-level STEM questions

Based on 2508.15260v1.pdf. Project page: jiaweizzhao.github.io/deepconf

