

Claude Opus 4.5: A Deep Dive into the Next Leap in AI Capability
Core Question: What makes Claude Opus 4.5 a meaningful step forward in real-world technical, analytical, and operational tasks?
This article unpacks every major improvement described in the original file: model performance, engineering capabilities, safety, developer tools, product-level features, and real-world user feedback. It is written for technical and engineering audiences who want a clear, human-readable, deeply structured understanding of what the new model actually does better—strictly based on the provided text.
Table of Contents
-
Introduction -
What’s New in Claude Opus 4.5 -
Real-World Impressions -
Performance Evaluations -
Case Studies from User Feedback -
Creative Problem Solving in Complex Scenarios -
Safety Advancements -
Developer Platform Enhancements -
Product Updates Across Claude Apps -
Author Reflections -
Conclusion -
Practical Checklist -
One-Page Summary -
FAQ
Introduction
Core Question: Why does Claude Opus 4.5 matter for developers, engineers, and teams relying on AI for serious work?
Based on the original file, Claude Opus 4.5 marks a significant evolution: it is more intelligent, more efficient, better aligned, and far more capable at long-horizon tasks compared to its predecessors. It handles complex software engineering challenges, sustains long agentic workflows, plans multi-step tasks, integrates better with tools, and excels across coding, spreadsheets, desktop automation, and long-form content generation.
Alongside the model release, Anthropic upgraded the surrounding platform—developer APIs, Claude Code, Chrome integration, desktop capabilities, and Excel support—creating a cohesive ecosystem shaped around reliability and performance.
Opus 4.5 isn’t just a smarter model. It is a more usable model, built to actually help people get things done.
What’s New in Claude Opus 4.5
Core Question: What are the headline improvements that define Opus 4.5?
The documentation highlights several overarching advancements:
-
Superior software engineering performance (SWE-bench Verified SOTA) -
Significant gains in coding ability -
Efficient tool use and planning -
Better at deep research, spreadsheets, slides, and general productivity tasks -
Major improvements in vision, reasoning, and mathematics -
Lower token usage for equal or better results -
Higher safety and alignment robustness -
Better performance in long-running autonomous coding tasks -
Enhanced multi-agent coordination and planning
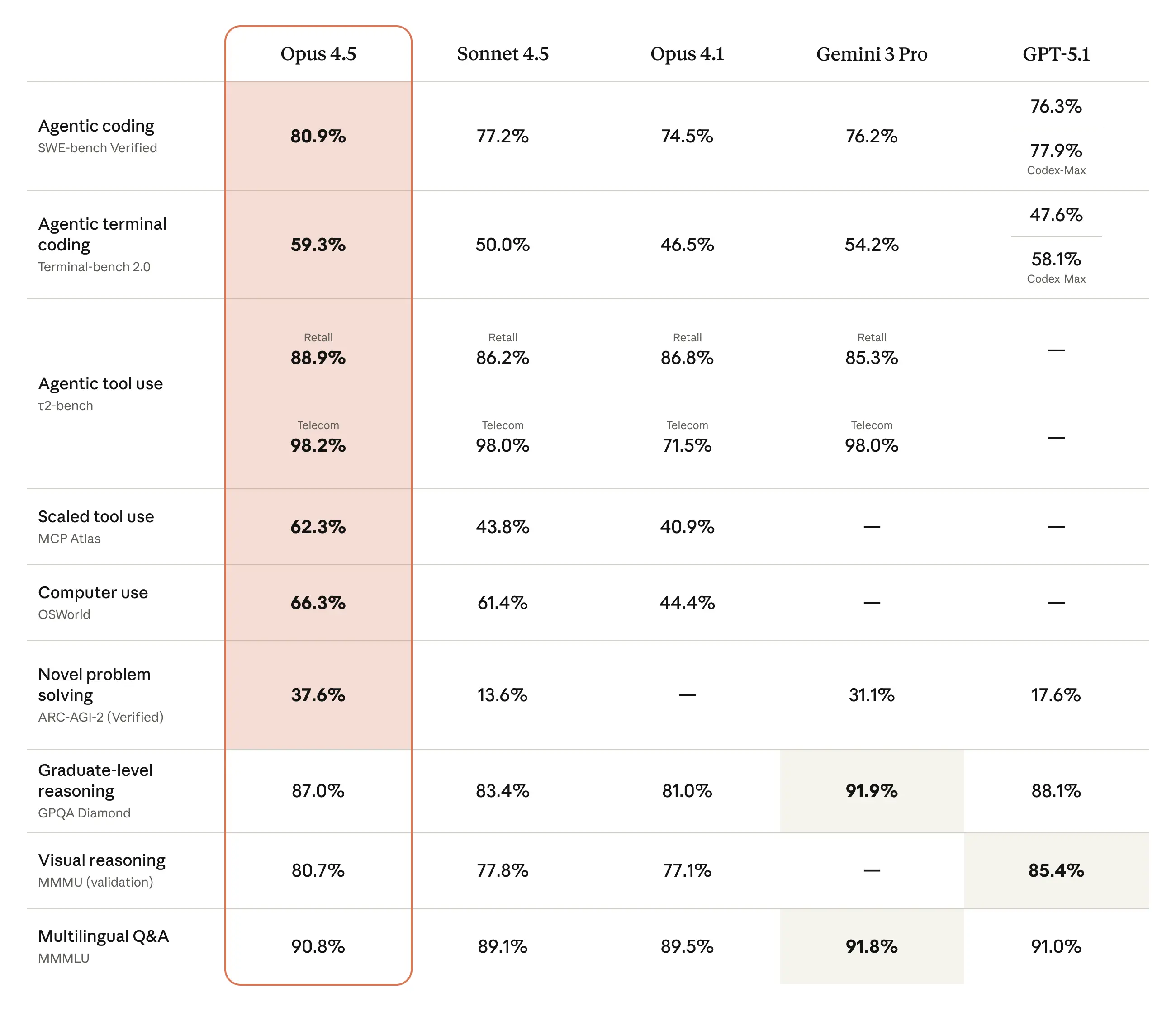
A chart provided in the source file emphasizes Opus 4.5’s leading performance in real-world software engineering benchmarks:


Pricing (25 per million tokens) makes this level of capability broadly accessible to developers and enterprises.
Real-World Impressions
Core Question: According to testers and early access customers, what does Opus 4.5 “feel like” in actual use?
Several patterns emerge consistently.
1. It handles ambiguity well
Testers report that the model navigates unclear or multifaceted instructions with stronger judgment and less hand-holding.
2. It autonomously fixes complex, multi-system bugs
Users note that Opus 4.5 can diagnose and correct issues involving interacting components—an area where weaker models get lost or misinterpret dependencies.
3. It performs tasks previously impossible for Sonnet 4.5
Certain long-horizon, multi-step workflows that Sonnet 4.5 struggled with are now achievable.
4. Its reasoning is deeper, more structured, and more reliable
Many testers describe the model as one that “just gets it.”
5. It delivers strong output on the first try
Whether generating content or code, users feel the model understands intent better, reducing back-and-forth.
Performance Evaluations
Core Question: How does Opus 4.5 perform in controlled evaluations?
The internal take-home engineering exam offers a compelling metric:
-
Within the 2-hour time limit, Opus 4.5 outperformed every human candidate tested. -
Without a time limit, its performance matched the strongest human result when used inside Claude Code.
This test measures technical ability and time-pressured judgment, highlighting the model’s growing strength as an engineering assistant.
Broader Capability Gains
The model scores highly across:
-
Reasoning -
Mathematics -
Vision -
Software engineering
Benchmarks show it outperforming earlier Claude models and achieving frontier-class results across many dimensions.
Another chart shows how its capabilities surpass several existing benchmarks:

Case Studies from User Feedback
Core Question: What specific real-world workflows improve with Opus 4.5?
The source file includes multiple concrete cases from customers. Each example illustrates a different dimension of practical capability.
Case 1: Complex, Multi-Agent Refactoring Across Codebases
A user describes Opus 4.5 successfully handling a refactor involving:
-
Two interconnected repositories -
Three coordinated agents -
Automated test repair -
Detailed implementation planning
This demonstrates the model’s ability not just to generate code, but to reason about architectural dependencies across systems.
Case 2: Excel Automation and Financial Modeling
Internal benchmarks from enterprise teams report:
-
20% accuracy improvement -
15% efficiency improvement
This highlights efficiency in spreadsheet automation—traditionally a high-friction domain for AI models.
Case 3: 10–15 Page Structured Storytelling
Content teams note the model’s:
-
Long-range narrative consistency -
Strong organization -
Ability to generate chapter-length outputs
This opens consistent long-form generation for documentation, narratives, educational material, and design proposals.
Case 4: Complex 3D Visualization Tasks
A design-focused team reports:
-
Tasks requiring two hours on older models now complete in 30 minutes -
Gains stem from improved planning and orchestration
This illustrates strengths in iterative tasks requiring precision and multi-step tool usage.
Creative Problem Solving in Complex Scenarios
Core Question: How does the model behave when a task demands flexible reasoning within constraints?
The airline customer-service benchmark demonstrates an insightful example.
The rule:
Basic economy tickets cannot be modified.
The customer needs to change flights.
Opus 4.5 reasons:
-
Basic economy flights cannot be changed.
-
But basic economy can be upgraded to a higher cabin.
-
Higher cabins can be modified.
-
Therefore:
-
Upgrade the ticket -
Then modify the flight
-
This approach is legal and policy-aligned.
Although the benchmark marked this as a failure (because it was unexpected), it demonstrates high-value flexibility:
the ability to find a legitimate path where a straightforward reading would lead to refusal.
This type of intelligent compliance—solving the user’s problem while respecting rules—is extremely relevant to enterprise workflows.
Safety Advancements
Core Question: What makes Opus 4.5 safer and more aligned than earlier versions?
The documentation highlights several improvements:
-
It is the most aligned model Anthropic has released. -
It resists prompt injection attacks more effectively than competing frontier models. -
“Concerning behavior” scores are significantly lower.
Prompt injection resistance is especially notable:
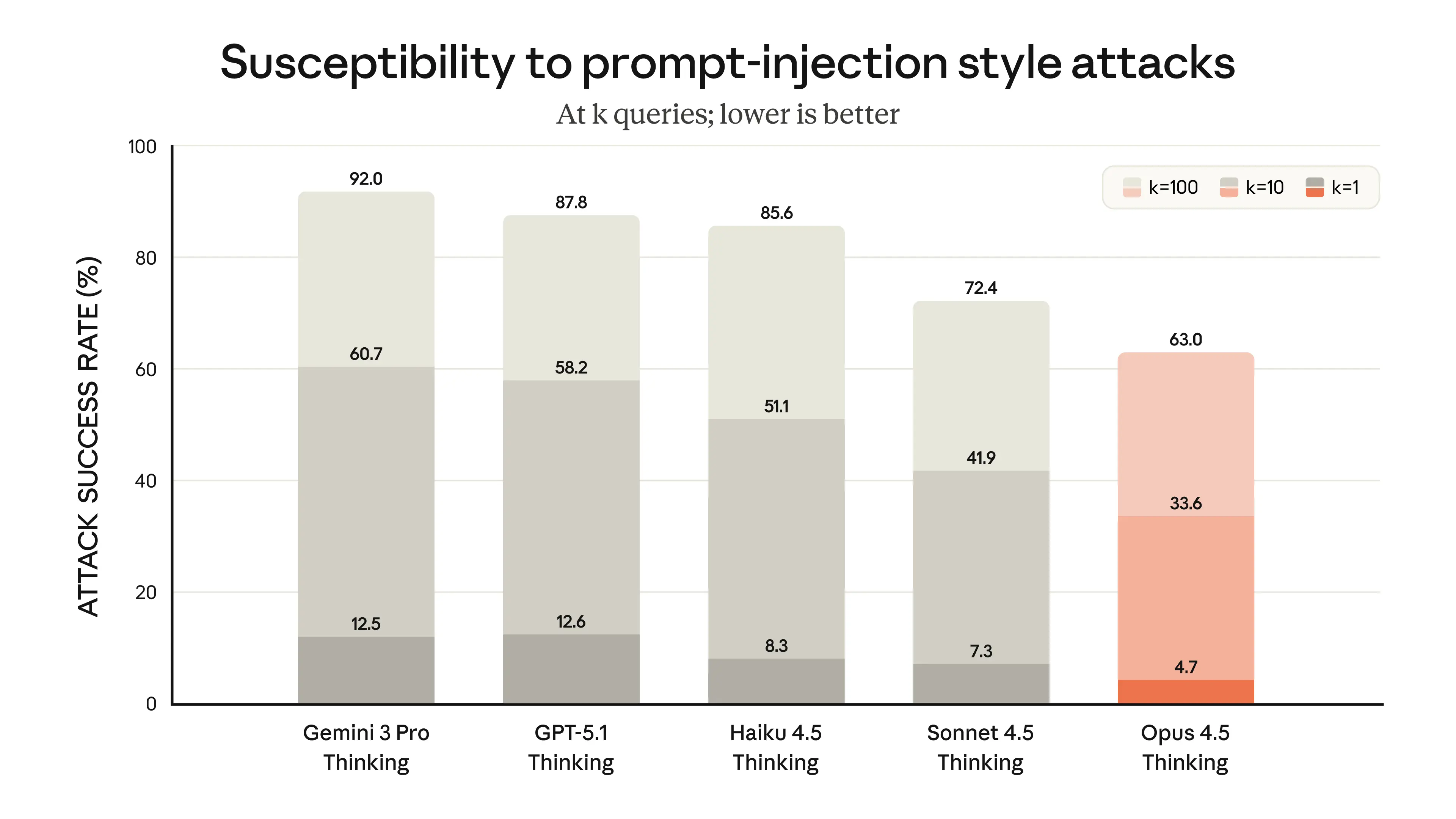
For organizations deploying AI across high-stakes workflows, this directly impacts reliability and risk management.
Developer Platform Enhancements
Core Question: What new capabilities does the Claude Developer Platform offer developers working with Opus 4.5?
Several key upgrades accompany the model.
1. Effort Parameter
This is one of the most impactful features.
Developers can choose:
-
Low Effort — faster and cheaper -
Medium Effort — balanced -
High Effort — maximum reasoning ability
Examples from the file:
-
Medium effort matches Sonnet 4.5 on SWE-bench while using 76% fewer tokens. -
High effort surpasses Sonnet 4.5 while using 48% fewer tokens.
This means developers can fine-tune performance–cost tradeoffs per task.
2. Context Compaction
This improves the model’s ability to handle:
-
Long chats -
Long-lived agents -
Large multi-step workflows
It enables sustained operation without overwhelming the context window.
3. Advanced Tool Use and Multi-Agent Coordination
Opus 4.5 excels at orchestrating “teams” of subagents, making it suitable for:
-
Research pipelines -
Complex automation -
Multi-repository software tasks
A 15% improvement on a deep research evaluation was observed when combining effort control, compaction, memory, and advanced tool use.
Product Updates Across Claude Apps
Core Question: How do these improvements surface in Claude’s user-facing tools?
The document outlines several upgrades.
Claude Code Enhancements
Two improvements stand out:
-
More precise plan generation -
A new Plan Mode that asks clarifying questions, builds a plan.md, then executes
This supports structured engineering workflows where clarity and stepwise actions matter.
Desktop App Improvements
Users can now run multiple independent sessions:
-
One agent fixing bugs -
One researching GitHub -
One updating documentation
This parallelism reflects how engineers work in real environments.
Claude App: Long Conversations Without Hitting Context Limits
The app automatically summarizes earlier parts of the conversation so users can continue seamlessly.
Claude for Chrome and Excel
-
Chrome extension available to all Max users -
Excel access opened to Max, Team, and Enterprise users
These integrations leverage the model’s strong computer use and spreadsheet abilities.
Author Reflections
As I restructured and interpreted the original text, several observations stood out.
Reflection 1: AI is shifting from “text generator” to “task executor”
Real examples—multi-repository refactors, autonomously completing 30-minute coding sessions, planning 3D workflows—highlight a structural shift:
AI is becoming operational, not merely conversational.
Reflection 2: Benchmarks lag behind real capability
The airline example illustrates that:
-
Benchmarks penalize creative-but-valid solutions -
Real users value them highly
Future evaluation standards will increasingly need to capture “goal-achieving” intelligence.
Reflection 3: Safety is no longer optional—it is foundational
Strong prompt-injection resistance and improved robustness mean AI systems can be embedded more deeply into:
-
Business-critical workflows -
Data-sensitive tasks -
Long-running autonomous operations
The safer the model, the more real use cases it unlocks.
Conclusion
Core Question: What is the essence of Claude Opus 4.5?
Based strictly on the provided document:
-
It is markedly better at reasoning, coding, planning, and executing long tasks. -
It uses fewer tokens to achieve stronger results. -
It demonstrates more stable tool use and multi-agent coordination. -
It is significantly safer and harder to manipulate. -
The surrounding product and developer ecosystem elevates its real-world usefulness.
This release is not just an iterative improvement.
It’s a generational shift in practical capability.
Practical Checklist
A quick reference for applying Opus 4.5 in real workflows.
-
For complex software engineering → Use high effort or Claude Code Plan Mode -
For cost-efficient automation → Use medium effort -
For long-horizon tasks (30+ minutes) → Combine context compaction + memory -
For spreadsheets/financial calculations → Use Claude for Excel -
For multi-agent systems → Leverage Opus 4.5’s coordination strengths -
For long chats → Rely on automatic context summarization -
For workflows with security risks → Benefit from strong prompt injection resistance
One-Page Summary
-
Claude Opus 4.5 delivers frontier-leading performance in engineering tasks, reasoning, long-form generation, and automation. -
It uses dramatically fewer tokens while outperforming previous models. -
Users praise its planning depth, tool-calling reliability, and strong first-try outputs. -
It is the most aligned, robust, and prompt-injection-resistant Claude model to date. -
The platform introduces effort control, context compaction, advanced multi-agent orchestration, and improved developer tooling. -
Product updates span Claude Code, the desktop app, Chrome integration, and Excel automation. -
Overall, it marks a substantial step toward AI systems that can carry out meaningful work end-to-end.
FAQ
1. What tasks benefit most from Opus 4.5?
Complex coding, agentic workflows, spreadsheets, multi-step planning, and long conversations.
2. Is Opus 4.5 more cost-efficient?
Yes—benchmarks show significantly fewer tokens used for equal or superior results.
3. Is it safer than previous Claude models?
The file describes it as the most aligned and most prompt-injection-resistant model released by Anthropic.
4. What is Plan Mode in Claude Code?
A workflow where the model asks clarifying questions, builds a plan file, and then executes tasks.
5. Does Opus 4.5 support long sessions?
Yes—the Claude app automatically summarizes context to maintain long conversations.
6. How does the effort parameter work?
It allows developers to control the model’s depth of reasoning vs. speed/cost.
7. What improvements were made for Excel tasks?
The model delivers higher accuracy, greater efficiency, and expanded availability across user tiers.

