

The State of Large Language Models in 2025: The Rise of Reasoning, Falling Costs, and Future Horizons
As 2025 draws to a close, it has undoubtedly been another landmark year in the field of artificial intelligence, particularly for Large Language Models (LLMs). If you feel the pace of technological progress isn’t slowing but accelerating, you’re right. From reasoning models that can “show their work” to dramatically falling training costs and the continuous evolution of model architecture, the past year has been filled with substantive breakthroughs.
This article will guide you through the most important advancements in the LLM space in 2025, explain how these technologies are changing the way we interact with AI, and look ahead to 2026. We’ll avoid obscure jargon and explain in plain language: what actually happened this year, and why it matters to you.
Why 2025 Was the “Year of Reasoning”
Looking back over recent years, LLM development has had a distinct theme each year. You could summarize it like this:
-
「2022: RLHF + PPO」. This was the foundation for ChatGPT’s stunning debut, using human feedback to fine-tune model behavior. -
「2023: LoRA & Efficient Fine-Tuning」. Enabled people to customize smaller models for their needs at a lower cost. -
「2024: Mid-Training」. Major labs began focusing on optimizing training data, using synthetic data, adjusting data mixtures to make pre-training more refined. -
「2025: RLVR + GRPO」. The core focus was teaching models to “reason.”
So, what is “reasoning” in this context? For LLMs, reasoning isn’t just about giving an answer; it’s about the model demonstrating the 「intermediate steps of thought」 that led to that answer. Like a math teacher showing their work, not just the final result. This “process output” itself often significantly improves answer accuracy.
DeepSeek R1: The Opening Shock of 2025
In January 2025, the Chinese research institute DeepSeek released the paper for its R1 model, sending ripples across the field. R1 attracted intense attention for three key reasons:
-
「Powerful Open Performance」: DeepSeek R1 was released as an “open-weight” model (meaning its design details and, to an extent, its parameters are public), with performance rivaling the leading closed-source models (like ChatGPT, Gemini) of the time. This gave more researchers and developers access to cutting-edge technology. -
「Disruptive Cost Perception」: The R1 paper prompted a re-evaluation of the cost of its predecessor, DeepSeek V3. The conclusion was surprising: training a top-tier model might cost around 50 million or even 294,000. This significantly lowered the barrier to entry for top-tier AI model development. -
「Introducing RLVR & GRPO」: This was the core technical breakthrough. The R1 paper proposed 「Reinforcement Learning with Verifiable Rewards (RLVR)」 and employed the 「GRPO algorithm」. In simple terms, this is a new training method that allows a model to learn complex reasoning by solving a vast number of problems whose correctness can be automatically verified (like math or coding problems), without relying on expensive and scarce human annotations.

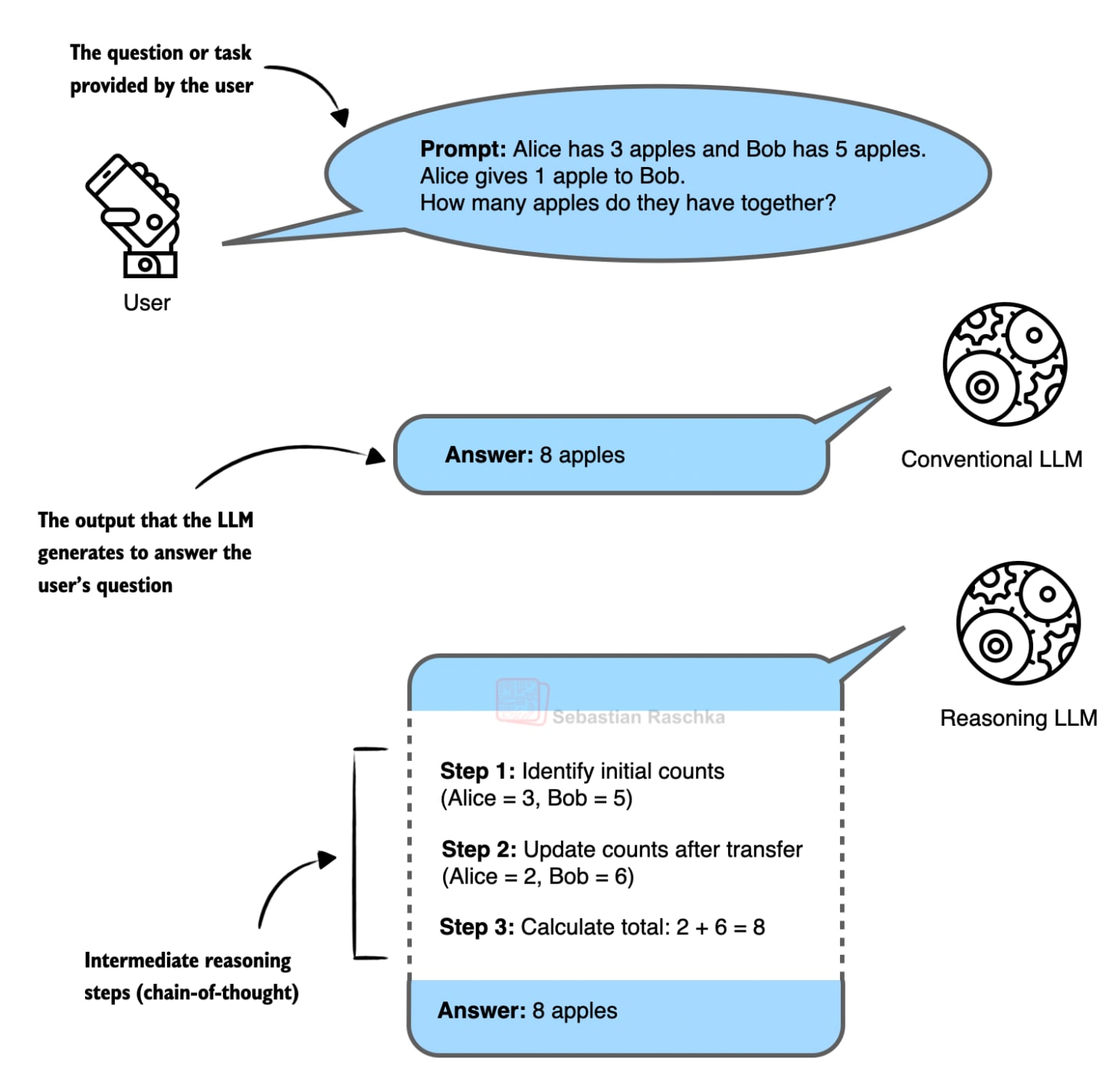
Figure 1: Comparison of reasoning model responses. On the left is a direct answer; on the right is an answer showing the chain of reasoning (thought process).
The “verifiable” in RLVR means the system can use deterministic methods (like running code, checking a math result) to automatically judge the correctness of a model’s output, providing a learning signal. This solves the bottleneck of previous RLHF methods, which required vast amounts of manual preference labeling.
「Following this, nearly every major LLM developer, both open and closed source, released a “reasoning” or “thinking” variant of their model.」 It’s fair to say DeepSeek R1 set the tone for LLM development in 2025.
GRPO: The 2025 Darling of Academic and Industrial Research
In an era of high LLM training costs, academia has often birthed efficient methods later widely adopted by industry. Previous years gave us 「LoRA」 (efficient fine-tuning) and 「DPO」 (Direct Preference Optimization).
The star of 2025 was undoubtedly 「GRPO」. Although introduced with the DeepSeek R1 paper, its clear concepts and relatively affordable experimental costs at certain scales quickly sparked a wave of research. Academics and industry researchers proposed various GRPO improvement techniques, such as:
-
「Zero Gradient Signal Filtering」 -
「Active Sampling」 -
「Token-Level Loss」 -
「No-KL Loss」
These weren’t just theoretical; they were successfully integrated into the training pipelines of state-of-the-art models like 「OLMo 3」 and 「DeepSeek V3.2」, making training more stable and efficient. Practitioners reported fewer training errors and significant performance gains after applying these tricks.
Model Architecture: Transformer Still Reigns, But Efficiency Optimizations Proliferate
Regarding model architecture, a fundamental fact remains: the most advanced models are still based on the 「decoder-style Transformer」. However, for efficiency, mainstream open-source models in 2025 widely adopted two techniques:
-
「Mixture of Experts (MoE) Layers」: Allows different parts of the model to specialize in different tasks, effectively increasing model size without a proportionate increase in compute cost. -
「Efficient Attention Mechanisms」: Like Grouped-Query Attention, Sliding Window Attention, etc., to reduce the computational overhead of processing long texts.
Beyond these, we saw more radical architectures aiming for linear efficiency enter practical view, such as 「Gated DeltaNets in Qwen3-Next and Kimi Linear」, and 「Mamba-2 layers in NVIDIA’s Nemotron 3」. The goal of these architectural explorations is clear: with the massive scale of model training and deployment today, any engineering optimization that saves costs holds immense commercial value.

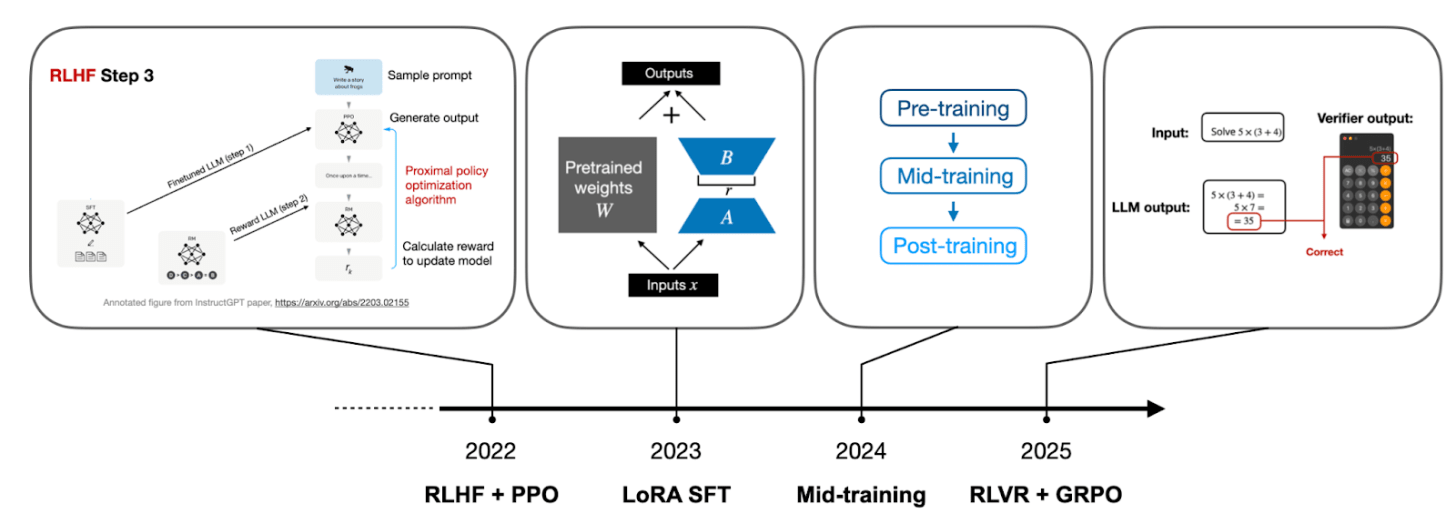
Figure 6: The evolution of LLM development focus. New techniques are added, but old ones don’t disappear; they form a cumulative technology stack.
「Prediction」: The core position of the Transformer architecture will likely hold for the next few years, but we will see more and more efficiency and engineering optimizations built around it. Meanwhile, alternative architectures like 「text diffusion models」 (e.g., Google’s Gemini Diffusion) may find a niche in specific tasks requiring extremely low latency, such as code completion.
Beyond Training: The Rise of Inference Scaling and Tool Use
2025 taught us that improving LLMs isn’t limited to “more training data” and “better architecture.” 「Inference scaling」 and 「tool use」 became crucial new dimensions.
What is Inference Scaling?
Simply put, it means allowing the model to “think more” while generating an answer. This may increase response time and compute cost, but for tasks where accuracy is far more important than speed (like solving complex math competition problems or programming puzzles), it’s entirely worthwhile. Models like 「DeepSeekMath-V2」 and 「GPT Heavy Thinking」 used extreme inference scaling to achieve gold-medal performance on top-tier math competition benchmarks.
Tool Use: A Powerful Weapon Against “Hallucination”
The problem of LLMs “confidently stating falsehoods” (hallucination) has been improving, thanks in large part to 「tool use」. Instead of forcing an LLM to memorize all knowledge (impossible and error-prone), we can teach it to call the right tool when needed.
-
Ask “Who won the 1998 FIFA World Cup?” -> The LLM calls a search engine API to fetch accurate info from FIFA’s official website. -
Ask a complex calculation -> The LLM calls a calculator API.
This not only improves accuracy but vastly expands the LLM’s capabilities. 「OpenAI’s gpt-oss」 was one of the earlier open-weight models designed specifically with tool use in mind. However, safely and controllably integrating tool use in the open-source ecosystem remains an evolving challenge.
The Benchmarking Dilemma: Reflections on the “Benchmaxxing” Era
A key term for 2025 was 「”benchmaxxing”」—an over-focus on boosting scores on public benchmark leaderboards, sometimes to the point of optimizing for the score rather than improving real-world capability.
A notable example was 「Llama 4」, which achieved impressively high scores on many benchmarks. However, users found its general capabilities and practical utility didn’t live up to the scores. The root issue is that when test sets are public and may be inadvertently or intentionally included in training data, benchmark scores gradually lose their power to measure a model’s generalization ability.
What does this mean for us?
-
「Benchmarks are a necessary threshold」: If a model scores very low on key benchmarks, it likely isn’t a good model. -
「But they are not a sufficient standard」: Two models with similarly high scores on the same benchmark does not mean the gap in their real-world performance is proportional to the score gap.
Evaluating a versatile LLM is far more complex than evaluating a simple image classifier. Currently, aside from continuously creating new, harder-to-“game” benchmarks and testing models in real scenarios, there’s no perfect solution.
How LLMs Are Changing Work: The Empowerer, Not the Replacer
Many worry that LLMs will replace human jobs. A more constructive view is: 「LLMs are powerful “enabling tools.”」 They give practitioners “superpowers,” remove friction from work, and allow people to focus on higher-value aspects.
In Programming
-
「I still write core code I care about」: For logic that requires deep understanding and correctness assurance (like training algorithms), doing it myself solidifies knowledge and ensures quality. -
「LLMs handle tedious boilerplate」: For example, adding command-line argument parsing to a script. This saves immense repetitive effort. -
「LLMs as advanced assistants」: They help spot issues, suggest improvements, and validate ideas.

Figure 14: An example of an LLM helping to quickly generate code boilerplate.
The 「key」 is discerning when to use an LLM and when to do it yourself. Use LLMs to enhance skills and efficiency, not to outsource thinking entirely. Codebases carefully designed and maintained by experts (even if those experts used LLM assistance) will likely remain far superior to codebases generated entirely from scratch by LLMs for the foreseeable future.
In Technical Writing & Research
-
「LLMs are excellent collaborators」: They can help check technical correctness, improve clarity, find literature, and suggest experimental ideas. -
「But they cannot replace expert depth」: A great technical book requires thousands of hours of the author’s investment and deep domain knowledge. LLMs can assist, but the core narrative, judgment, and knowledge structuring still depend on the human. -
「The same goes for readers」: LLMs are great for quick Q&A and introductory explanations. But to build systematic, deep understanding, following a structured learning path (books, courses) designed by experts remains more efficient.
「A Useful Analogy: Chess」
Chess AIs have long surpassed human champions, but human chess tournaments haven’t disappeared; they’ve arguably become more fascinating. Professional players use AI to explore new tactics, challenge their intuition, and analyze mistakes in depth. 「LLMs are to knowledge workers what AI is to chess players—a powerful partner that accelerates learning and expands the possible.」
2025 Surprises and 2026 Predictions
Surprising Developments in 2025
-
「Gold-Medal Reasoning Models」: Multiple models (both open and closed source) achieved gold-medal level performance on benchmarks at International Mathematical Olympiad difficulty in 2025, sooner than many expected. -
「Llama’s Fade, Qwen’s Rise」: In the open-source community, the Qwen series surpassed Meta’s Llama series in popularity and influence. -
「Architectural Borrowing Became Normal」: For example, Mistral AI adopted the DeepSeek V3 architecture for its flagship Mistral 3 model. -
「A Crowded Open-Source Arena」: Beyond Qwen and DeepSeek, Kimi, GLM, MiniMax, and Yi all entered the competition for top-tier open-source models. -
「OpenAI Released an Open Model」: The release of gpt-oss was a landmark event.
Predictions for 2026
-
「Diffusion Models Go Practical」: Text diffusion models like Gemini Diffusion may find a place in consumer applications (e.g., code completion) due to their extremely low latency. -
「Tool Use Becomes Standard」: The open-source community will gradually adopt and integrate local tool-use capabilities, enhancing the “agentic” properties of LLMs. -
「RLVR Expands Its Domain」: The training paradigm of reinforcement learning with verifiable rewards will expand from math and code into other domains requiring rigorous reasoning, like chemistry and biology. -
「Long-Context Models Partially Supplants RAG」: For document Q&A, as “small but capable” long-context models improve, the traditional “Retrieval-Augmented Generation (RAG)” approach may not be the only default solution. -
「A Shift in Progress Sources」: Noticeable performance gains will come more from 「peripheral improvements like inference scaling and tool calling」 rather than just breakthroughs in the core model training itself. Simultaneously, the industry will focus more on optimizing latency to avoid unnecessary “thinking” overhead.
Conclusion: Diversified Progress and the Unchanging Need for Judgment
The lesson from 2025 is clear: Progress in LLMs hasn’t come from a single “silver bullet” but from advancements across multiple fronts—「architecture, data, training paradigms, inference processes, and tool ecosystems」—all moving forward in parallel.
At the same time, model evaluation remains difficult, and benchmarks are imperfect. 「Ultimately, how and when to use these powerful systems still relies on good human judgment.」 As we look to 2026, we hope to witness more surprising progress while also gaining clearer, more transparent understanding of the roots of that progress.
Frequently Asked Questions (FAQ)
「1. What is “reasoning” ability in an LLM?」
For Large Language Models, “reasoning” ability refers to the model not only providing a final answer but also demonstrating the logical thought process and intermediate steps that led to it. This is akin to “showing your work” when solving a math problem and typically leads to more accurate answers.
「2. Why was DeepSeek R1 so significant?」
Released in early 2025, DeepSeek R1 demonstrated that powerful reasoning capabilities could be trained efficiently using reinforcement learning techniques (RLVR/GRPO). As an open-weight model, it showed performance competitive with closed-source models and significantly lowered cost expectations for training top-tier models.
「3. What’s the difference between RLVR and traditional RLHF?」
RLHF (Reinforcement Learning from Human Feedback) relies on manually labeled preference data, which is costly and scarce. RLVR (Reinforcement Learning with Verifiable Rewards) uses data whose correctness can be automatically verified (like math problems, runnable code) as a training signal, enabling lower-cost, large-scale training of reasoning abilities.
「4. LLM benchmark scores were so high in 2025; why does the actual experience sometimes not match?」
This phenomenon is called “benchmaxxing.” Because many benchmark datasets are public, models may have directly or indirectly “seen” similar questions during training, leading to inflated scores. This reminds us that benchmark scores are a necessary reference but do not fully represent a model’s general capability or practical utility.
「5. Will LLMs make programmers or technical writers obsolete?」
Currently, LLMs act more as powerful “enabling tools.” They automate tedious work (like writing boilerplate code, checking for errors), allowing professionals to focus more on core tasks requiring creativity, deep thinking, and judgment. They are changing how we work, not simply replacing jobs.
「6. For the average user, what was the biggest LLM advance in 2025?」
The most直观 advance was likely the proliferation of models that can “show their thinking” (various “deep think” modes), making AI responses more trustworthy and understandable. Simultaneously, model capabilities in complex problem-solving (math, programming) and tool use (web search, calculator calls) improved significantly.
「7. What are the most important directions for LLM development in 2026?」
Focus is expected in these areas: 1) Expanding reasoning training (RLVR) to broader scientific fields; 2) Making tool use and agentic capabilities standard for LLMs; 3) Continuously optimizing model architecture and inference efficiency to reduce costs; 4) Exploring better ways to utilize private data for domain specialization.

