

音频驱动视频生成技术解析:WAN-S2V模型如何实现影视级角色动画
引言
在影视制作领域,角色动画生成一直是技术挑战的焦点。传统方法在处理复杂场景时往往力不从心,而阿里巴巴团队推出的WAN-S2V模型通过融合文本与音频控制,在电影级视频生成领域取得突破性进展。本文将深入解析这项技术的核心原理、数据处理流程及实际应用场景。
一、技术背景:音频驱动视频生成的发展
1.1 当前行业痛点
传统音频驱动模型主要存在三大局限:
- ❀
场景复杂度不足:多聚焦于简单对话场景 - ❀
运动幅度受限:角色动作幅度较小,缺乏动态感 - ❀
长视频稳定性差:多片段拼接时容易出现画面跳跃
1.2 WAN-S2V的创新突破
| 创新维度 | 传统方案 | WAN-S2V方案 |
|---|---|---|
| 控制方式 | 单一音频控制 | 文本+音频双模控制 |
| 适用场景 | 单人对话 | 影视级多角色互动 |
| 视频长度 | 短片段(<10秒) | 长视频(分钟级) |
| 动作丰富度 | 基础表情 | 全身复杂动作 |
二、数据处理:构建影视级训练素材库
2.1 数据采集策略
2.1.1 双轨数据收集机制
自动化筛选流程:
-
从OpenHumanViD等开源数据集获取原始视频 -
基于视频描述进行初筛(保留含人物描述的内容) -
通过VitPose进行2D姿态追踪,转化为DWPose格式
人工精筛标准:
- ❀
包含复杂人类活动(对话/歌唱/舞蹈) - ❀
画面包含完整人脸且无遮挡 - ❀
视频清晰度达标(采用Dover指标评估)
2.1.2 数据清洗指标
| 评估维度 | 工具/方法 | 具体标准 |
|---|---|---|
| 画面清晰度 | Dover指标 | 感知锐度>0.8 |
| 运动稳定性 | UniMatch光流预测 | 运动得分<0.3 |
| 细节锐度 | Laplacian算子 | 人脸/手部区域方差<0.1 |
| 审美质量 | 改进版美学预测器 | 评分>7.5/10 |
| 字幕遮挡 | OCR检测 | 人脸/手部无文字覆盖 |
2.2 视频标注体系
采用QwenVL2.5-72B进行多维度标注:
# 标注要素示例
- 镜头角度:低角度/平视/俯拍
- 角色特征:红色连衣裙/银色耳环
- 动作分解:右手抬起45度/头部左转30度
- 场景特征:现代办公室/暖色调灯光
三、模型架构:融合多模态控制的视频生成系统
3.1 核心架构图解

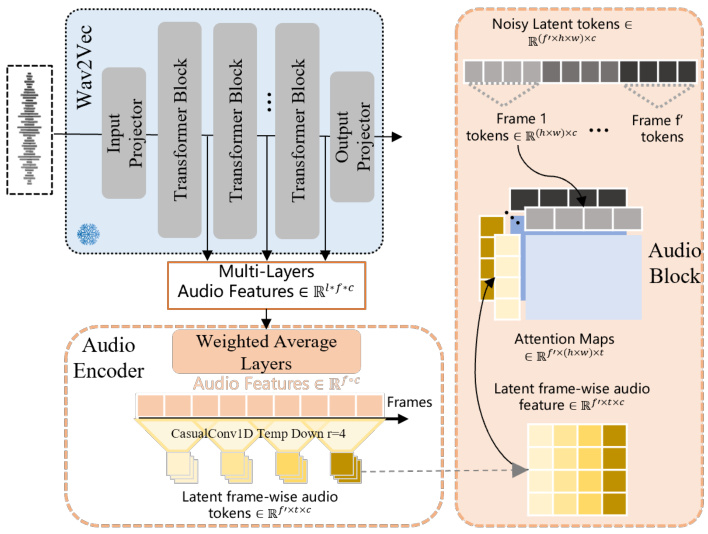
3.2 关键模块解析
3.2.1 多阶段训练策略
1. 音频编码器预训练
- 使用Wav2Vec提取多层级音频特征
- 通过加权平均层融合浅层节奏特征与深层语义特征
2. 全量预训练
- 混合FSDP+Context Parallel并行训练
- 支持可变分辨率输入(最大token数限制)
3. 高质量微调
- 在影视级数据上精细调整
- 采用监督微调(SFT)提升细节表现
3.2.2 长视频生成方案
采用改进版FramePack模块:
- 对早期帧进行高压缩比编码
- 近期帧保留完整信息
- 动态调整压缩比例(远景帧压缩比=3:1,近景帧=1:1)
四、实验验证:性能对比与场景应用
4.1 核心指标对比
| 指标 | EchoMimicV2 | MimicMotion | EMO2 | FantasyTalking | HY-Avatar | WAN-S2V |
|---|---|---|---|---|---|---|
| FID↓ | 33.42 | 25.38 | 27.28 | 22.60 | 18.07 | 15.66 |
| FVD↓ | 217.71 | 248.95 | 129.41 | 178.12 | 145.77 | 129.57 |
| SSIM↑ | 0.662 | 0.585 | 0.662 | 0.703 | 0.670 | 0.734 |
关键发现:
- ❀
在人物身份保持(CSIM)指标上领先0.677 - ❀
手部动作丰富度(HKV)表现优异 - ❀
面部表情多样性(EFID)显著优于竞品
4.2 典型应用场景
4.2.1 多角色互动场景


技术亮点:
- ❀
通过文本控制全局镜头运动 - ❀
音频驱动角色微表情变化 - ❀
支持多角色协同动作编排
4.2.2 长视频连续生成

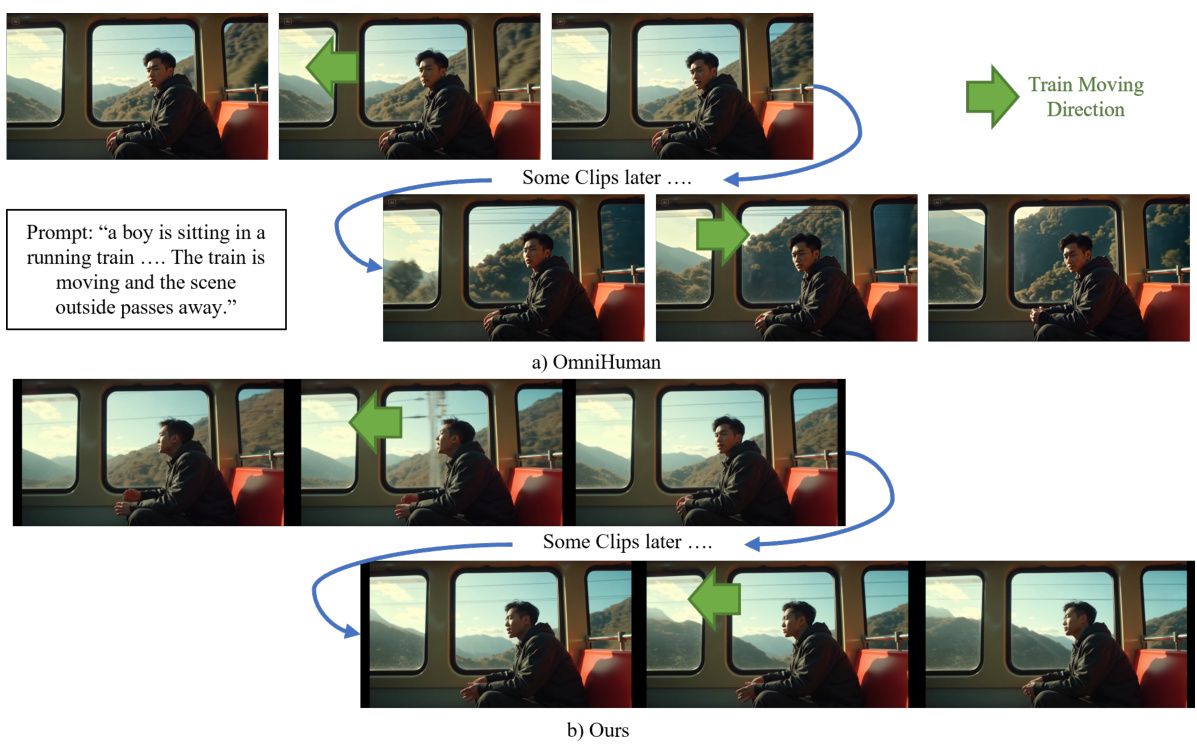
解决方案:
- ❀
采用Motion Frames压缩技术 - ❀
保持跨片段运动趋势一致性 - ❀
维持物品外观连续性(如纸张、道具)
五、技术应用指南
5.1 硬件配置建议
| 配置项 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU | 8×A100-80G | 8×H100-80G |
| 内存 | 640GB | 1TB |
| 存储 | 50TB SSD | 100TB NVMe |
5.2 典型工作流程
1. 准备参考图像(建议512x768分辨率)
2. 制作音频输入(支持WAV/FLAC格式)
3. 编写文本提示:
"中景镜头,角色穿着蓝色西装,在会议室进行激情演讲"
4. 设置生成参数:
- 帧数:120帧(4秒@30fps)
- 分辨率:1024x768
- 运动幅度:1.5(0-2范围)
六、常见问题解答(FAQ)
Q1: WAN-S2V与Hunyuan-Avatar的主要区别?
核心差异:
- ❀
架构设计:WAN-S2V采用全参数训练,Hunyuan-Avatar部分参数冻结 - ❀
适用场景:前者擅长影视级多角色,後者专注单角色高保真 - ❀
训练数据:WAN-S2V包含自研影视数据集
Q2: 如何处理音频与口型不同步问题?
解决方案:
-
使用Light-ASD进行音视频对齐检测 -
在训练阶段加入对抗性扰动增强 -
推理时采用滑动生成策略(每次生成4帧校验)
Q3: 长视频生成如何保证时间一致性?
关键措施:
- ❀
运动帧压缩技术(参考Zhang & Agrawala方案) - ❀
跨片段注意力机制 - ❀
关键物体追踪算法(通过文本提示锁定特征)
七、未来展望
WAN-S2V作为Vida系列的开篇之作,后续研究方向包括:
-
多角色复杂交互生成 -
舞蹈动作精确控制 -
实时视频驱动系统开发
这些技术突破将推动影视制作进入新的智能化时代,为创作者提供更强大的视觉表达工具。
相关数据集:
- ❀
OpenHumanViD - ❀
EMTD - ❀
Koala-36M

