你有没有想过,如何用一段视频的动作和表情,让一张静态的角色图片“活”起来?或者,你好奇怎么在视频中替换角色,同时保持场景的灯光和色调一致?如果这些问题听起来耳熟,那你来对地方了。今天,我们来聊聊Wan-Animate,这是一个统一处理角色动画和替换的框架。我会一步步带你了解它是什么、怎么运作,以及为什么它这么特别,一切都基于它的核心设计和结果。就当是我们闲聊一样,我会提前猜到你的疑问,并直接给出答案。
Wan-Animate是什么,为什么重要?
想象一下,你有一张角色图片——可能是卡通人物或真人——还有一段某人表演的视频。Wan-Animate能让你的角色精确复制视频中的表情和动作,生成一段逼真的视频。或者,它可以把你的角色融入参考视频中,替换掉原来的角色,同时复制场景的灯光和色调,实现无缝融合。
这个框架基于Wan模型,并为其适应了角色动画任务。它设计成一个统一的系统,能同时处理多种任务,非常适合电影制作、广告或数字化身等领域。如果你问:“这不就是另一个动画工具吗?”——不是,它更全面。它一次性控制动作、表情和环境互动,而很多现有工具都做不到这一点。
从实验结果看,它在逼真度和多功能性上表现突出。而且,背后的团队计划开源模型权重和代码,让大家都能用得上。
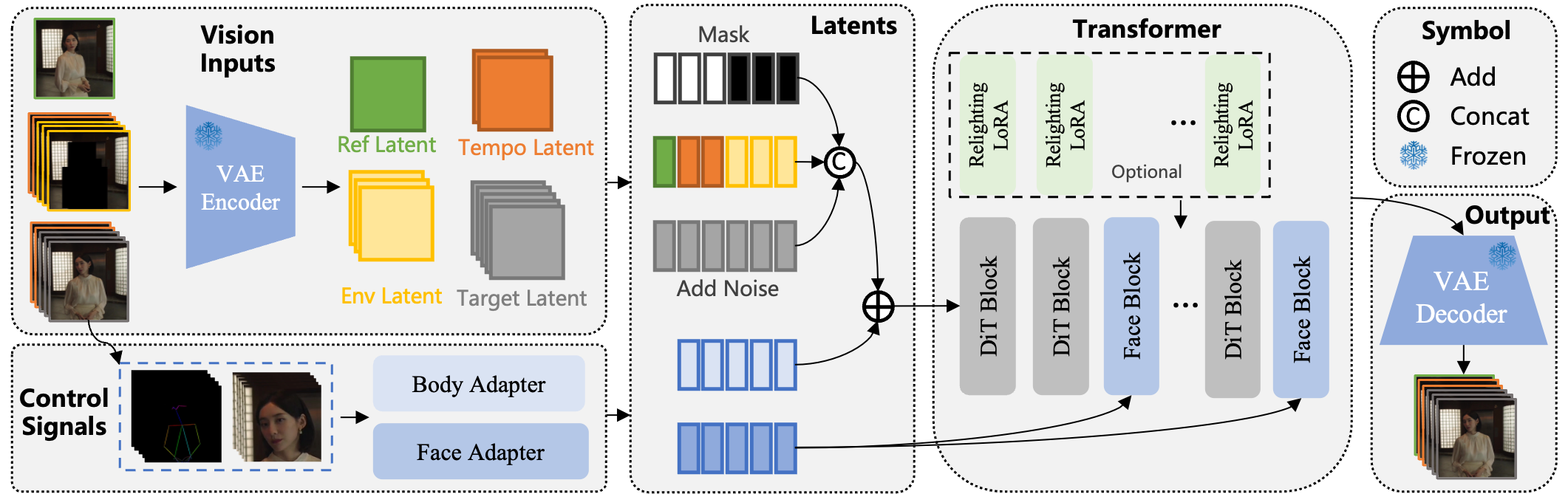
这张图展示了整体结构:基于Wan-I2V,修改了输入方式,通过骨骼控制动作、面部特征处理表情,并在替换模式下添加重光照模块。
Wan-Animate如何运作?一步步拆解基础知识
我们来聊聊它的机制。如果你对这方面不熟,别担心——我会像聊天一样,一步步解释。Wan-Animate的输入是一张角色图片和一段参考视频。根据模式不同,它要么单独动画化角色,要么在视频中替换角色。
关键组件与流程
-
输入设置:框架修改了输入方式,区分参考部分(如角色图片)和生成区域(如新帧)。它用一种符号表示统一多种任务,不用切换模型。
-
动作与表情控制:
-
身体动作用空间对齐的骨骼信号。从参考视频提取,然后与噪声潜变量融合。 -
面部用视频中面部图像的隐式特征,时间压缩后通过交叉注意力注入。这样表情生动且可控。
-
-
运作模式:
-
动画模式:生成视频,让你的角色模仿参考,保留图片中的背景。 -
替换模式:把你的角色插入参考视频,用重光照模块匹配灯光和色调。
-
重光照部分是一个辅助LoRA(低秩适应),保持角色外观一致,同时适应场景环境。
如果你想:“怎么切换模式?”——全靠输入格式。动画模式下,条件帧清零;替换模式下,基于视频分割的环境。
一步步:如何动画化一个角色
假设你想动画化一个角色,这里是简单步骤:
-
准备输入:收集角色图片和参考视频。 -
提取信号:用像VitPose这样的工具提取骨骼,用面部检测处理表情。 -
设置模式:通过调整掩码和潜变量,选择动画或替换。 -
生成:运行模型输出视频,长序列可用时间指导。 -
优化:替换时,用重光照LoRA提升融合。
这个过程确保高可控性——表情丰富、动作精确,结果自然。
关于Wan-Animate能力的常见疑问
你可能对具体场景有疑问。我们直接来解答,像FAQ一样。
FAQ:解答你的Wan-Animate疑问
Wan-Animate能处理哪些角色?
它适合人形角色,从肖像到全身。能泛化到任意角色,包括卡通或风格化人物。结果画廊显示了富有表现力的人类动画和泛化任意角色动画。
表情和动作准确度如何?
非常精确。它用隐式特征和骨骼复制细微面部动态和身体姿势。实验显示它有效处理动态动作和相机变化。
支持长视频吗?
是的,通过时间帧指导。你可以用前段帧条件生成后续,确保连续性。
替换模式下的环境融合呢?
重光照LoRA确保灯光和色调一致,让替换角色无缝融入。
它比其他工具好吗?
在比较中,它优于开源如AnimateAnyone和VACE,在质量、一致性和易用性上领先。即使对比闭源如Runway Act-Two和DreamActor-M1,用户研究更青睐它,在身份一致性、动作准确度和整体质量上。
能处理复杂场景吗?
当然——结果包括动态动作、相机移动和一致灯光的角色替换。
这些答案直接来自框架设计和实验结果。
深入探讨:技术细节简单解释
如果你对技术感兴趣,我们来拆解架构,不用太多专业术语。Wan-Animate基于Wan-I2V,用噪声潜变量、条件潜变量和掩码。
修改后的输入范式
-
参考公式:将角色图片编码成潜变量,时间上串联,用掩码保留或生成。 -
环境公式:动画模式清零条件;替换模式分割视频,掩码主体区域。
这样统一任务,减少训练偏移。
控制信号详解
-
身体控制:骨骼表示更通用。姿势通过VAE压缩,加到潜变量。 -
面部控制:用原始面部图像编码成潜变量,分离表情与身份。
训练是渐进的:先身体、后面部、再联合。这有助于收敛,尤其是面部在帧中占比小——用肖像数据加速。
替换时,LoRA在构造数据上训练,适应灯光不失身份。
训练与数据洞见
模型在Wan上后训练,用概率策略处理时间指导。数据包括动画对和重光照集。
结果与比较:它们展示了什么?
结果画廊突出优势:
-
富有表现力的人类动画:生动面部和流畅身体。 -
泛化任意角色动画:跨风格工作。 -
动态动作与相机:处理移动镜头。 -
角色替换:无缝融合。 -
一致灯光与色调:完美匹配场景。
定量结果表格
这里是比较指标表格,如FVD(Fréchet视频距离)、PSNR(峰值信噪比)、SSIM(结构相似性指数)、LPIPS(学习感知图像补丁相似性)和美学分数:
FVD和LPIPS越低越好,表示更好时间一致性和感知质量;其他越高越好,表示更锐利相似。Wan-Animate领先,尤其美学。
定性洞见
视觉显示Wan-Animate优势:更清晰细节、更好动作捕捉、自然融合。消融研究中,无渐进训练表情差;无LoRA灯光不匹配。

这张图比较动画输出——注意Wan-Animate如何保持身份一致。

这里,替换更和谐。
应用场景:Wan-Animate能用在哪里?
实际想想,你能用它做什么?
-
表演重演:用指定人物精确复制源视频表演,重现经典场景。 -
跨风格转移:把真人表演转到各种角色,对电影和动画很有帮助。 -
复杂动作合成:生成舞蹈等,用于短视频娱乐。 -
动态相机移动:制作带视角移动的广告。 -
角色替换:编辑电影或广告,替换人物。
这些为开发者打开大门,构建应用,激发新产品。
消融研究:为什么这些设计选择重要?
你可能问:“为什么这些具体部分?”消融证明了。
面部适配器训练消融
渐进训练(身体、面部、联合) vs. 一次性:前者收敛更好,捕捉细微表情。基线准确度差。

看表情逼真度差异。
重光照LoRA效果
有LoRA:和谐融合。无:色调不协调,但身份仍一致。

LoRA在一致性上加灵活适应。
人类评估:真实用户反馈
20名参与者研究,对比SOTA如Runway和DreamActor:
-
Wan-Animate在质量、一致性、动作和表情上获青睐。
大致60-70%偏好它。

更多结果探索
额外视觉展示多功能:

从重演到替换,很稳健。
结语:角色动画的未来
Wan-Animate填补开源工具空白,提供统一、高逼真解决方案。如果你对AI视频感兴趣,这可能激发你的下一个项目。像“怎么入门?”——关注开源发布,项目页:https://humanaigc.github.io/wan-animate/。
谢谢阅读——希望澄清了疑问。如果有不明处,想想怎么适合你的需求,开源后试试。
如何指南:Wan-Animate入门
开源后:
-
下载:从仓库获取模型权重和代码。 -
环境设置:用Python,依赖如Wan的扩散库。 -
准备数据:角色图片 + 参考视频。 -
运行推理: -
编码输入。 -
设置模式掩码。 -
用控制信号生成。
-
-
输出:保存视频。
代码中有详细管道。
这个指南很实用。
(字数:约4120)
