

最近,我在尝试把 Moonshot AI 的 Kimi K2 模型部署到 vLLM 上运行官方的 K2-Vendor-Verifier 基准测试时,遇到了一个让人头疼的问题:工具调用成功率只有不到 20%,远低于官方 API 的几乎 100% 表现。这让我不得不深入排查,最终发现了三个关键的兼容性问题,并和 Kimi 团队、vLLM 团队一起把问题彻底解决,成功率提升了 4.4 倍以上。
这篇文章就是那段调试经历的完整记录。如果你也正在把 Kimi K2 集成到 vLLM,或者对大模型工具调用(tool calling)的实现细节感兴趣,这篇内容应该能帮到你。
官方 API 的表现有多好?
先来看看官方的基准数据,这是直接调用 Moonshot AI 官方端点的结果:
| 模型名称 | 提供方 | finish_reason: stop | finish_reason: tool_calls | finish_reason: others | 结构验证错误 | 成功工具调用 |
|---|---|---|---|---|---|---|
| Moonshot AI | MoonshotAI | 2679 | 1286 | 35 | 0 | 1286 |
| Moonshot AI Turbo | MoonshotAI | 2659 | 1301 | 40 | 0 | 1301 |
可以看到,官方 API 在几千次请求中,工具调用的结构验证错误为 0,成功率接近完美。这也是我们希望在开源部署时能达到的标准。
我第一次在 vLLM 上跑的结果有多差?
我最初使用的环境:
-
✦ vLLM 版本:v0.11.0 -
✦ Hugging Face 模型:moonshotai/Kimi-K2-Instruct-0905(某个早期 commit)
结果如下:
| 模型名称 | finish_reason: stop | finish_reason: tool_calls | finish_reason: others | 结构验证错误 | 成功工具调用 |
|---|---|---|---|---|---|
| Kimi-K2-Instruct-0905(初始版本) | 3705 | 248 | 44 | 30 | 218 |
原本应该有 1200+ 次工具调用机会,结果只有 218 次成功解析,成功率不到 20%。这显然不是小问题,而是模型和 serving engine 之间的“沟通”彻底出了问题。
下面我把排查过程中发现的三个核心问题一一讲清楚。
问题一:add_generation_prompt 参数没有传进去
第一个现象是,很多本该触发工具调用的请求,最后却以 finish_reason: stop 结束,甚至连结构化的助手回复都没有生成,而是直接输出普通文本。
如何定位的?
我做了一个对比实验:
-
手动在外边调用 tokenizer 的 apply_chat_template,生成完整的 prompt 字符串。 -
把这个字符串直接送到 vLLM 的低级别 /v1/completions接口。
结果发现,这样操作后,大部分失败的案例都恢复正常了。这说明问题出在 vLLM 内部应用 chat template 的方式上。
根本原因是什么?
Kimi 的 tokenizer 在 apply_chat_template 时,支持一个关键参数 add_generation_prompt=True,这个参数会决定是否在 prompt 末尾加上表示“助手开始回复”的特殊 token:
正确结尾应该是:
...<|im_assistant|>assistant<|im_middle|>
但 vLLM 在调用时,并没有把 add_generation_prompt=True 传进去,导致 prompt 在用户消息后直接截断,模型完全不知道该轮到自己回复了,自然也不会生成工具调用。
为什么 vLLM 没传这个参数?因为 vLLM 出于安全考虑(参考 PR #25794),只会对函数签名中明确声明的参数进行传递。而 Kimi 早期版本的 tokenizer_config.json 把这个参数藏在了 **kwargs 里,vLLM 看到签名里没有,就直接忽略了。
怎么解决的?
我和 Kimi 团队沟通后,他们很快在 Hugging Face 模型的 tokenizer_config.json 中明确声明了 add_generation_prompt 参数,支持 vLLM 正常传递。同时我也在 vLLM 侧提交了 PR #27622,对常见的 chat template 参数做了白名单处理,避免类似沉默失败。
最佳实践:如果你要用 Kimi K2,请选择 chat template 已更新的版本:
-
✦ Kimi-K2-0905:commit 在 94a4053eb8863059dd8afc00937f054e1365abbd 之后 -
✦ Kimi-K2:commit 在 0102674b179db4ca5a28cd9a4fb446f87f0c1454 之后
问题二:空 content 被错误地转成了列表结构
修复第一个问题后,成功率提升了不少,但还有一批错误依然存在。
现象是什么?
我发现这些错误多出现在对话历史中包含工具调用、且某些消息的 content 字段为空字符串 '' 的场景。
为什么会出问题?
vLLM 为了内部统一表示,会把简单的 content: '' 自动升级成 content: [{'type': 'text', 'text': ''}] 这种多模态列表结构。
但 Kimi 的 Jinja chat template 原本只期望处理字符串类型的 content,当收到列表时,它会直接把列表的字符串表示插进 prompt,生成类似这样的错误片段:
...<|im_end|><|im_assistant|>assistant<|im_middle|>[{'type': 'text', 'text': ''}]<|tool_calls_section_begin|>...
这显然是畸形的,模型看到后就懵了。
正确应该是直接跳过空内容,生成:
...<|im_end|><|im_assistant|>assistant<|im_middle|><|tool_calls_section_begin|>...
怎么解决的?
Kimi 团队更新了 chat template,加入了对 content 类型判断的逻辑:
-
✦ 如果是字符串,直接渲染 -
✦ 如果是可迭代对象(如列表),正确处理其中的文本部分
更新后,这类格式错误基本消失。
问题三:工具调用 ID 解析器过于严格
还有一部分工具调用明明生成了,但 vLLM 解析时却报错丢弃了。
现象是什么?
通过查看原始文本输出,我发现模型偶尔会生成不符合官方规范的工具调用 ID,例如 search:2,而官方文档要求格式是 functions.func_name:idx。
为什么模型会生成非标准 ID?
Kimi 团队解释,这是因为对话历史中如果出现了非标准格式的工具调用 ID(如 search:0),模型容易被“带偏”,模仿生成类似的错误格式。
官方 API 之所以不受影响,是因为他们在调用模型前,会自动把历史中的工具调用 ID 全部规范化成标准格式,相当于加了一层防护。
vLLM 为什么解析失败?
vLLM 的工具调用解析器对格式要求很严格,用类似 function_id.split('.')[1].split(':')[0] 的方式提取函数名。一旦遇到没有 . 的 ID,就会抛 IndexError,整个工具调用被丢弃。
怎么解决的?
最根本的办法是:在发送请求前,把历史消息中的工具调用 ID 统一规范化成 functions.func_name:idx 格式。前两个问题的修复也大幅减少了模型生成错误 ID 的概率。
另外,我向 vLLM 社区提议增强解析器的容错能力(PR #27565),后续可能会有改进。
修复后的最终效果
所有修复落地、模型 chat template 更新后,我重新跑了一次完整的 K2-Vendor-Verifier 基准:
| 指标 | 数值 | 说明 |
|---|---|---|
| Tool-Call F1 Score | 83.57% | 工具调用触发时机的精确率和召回率的调和平均值 |
| Precision | 81.96% | 真正触发工具调用中的正确比例 |
| Recall | 85.24% | 应该触发工具调用时实际触发的比例 |
| Schema Accuracy | 76.00% | 生成的工具调用通过语法验证的比例 |
| 成功工具调用 | 1007 | 成功解析并验证通过的工具调用次数 |
| 模型尝试工具调用总数 | 1325 | 模型主动发起的工具调用次数 |
| 结构验证错误 | 318 | 解析或验证失败的次数 |
| 整体请求成功率 | 99.925% | 4000 次请求中成功完成的比例(3997/4000) |
成功解析的工具调用从最初的 218 提升到 1007,提升超过 4.4 倍,已经非常接近官方 API 的表现。

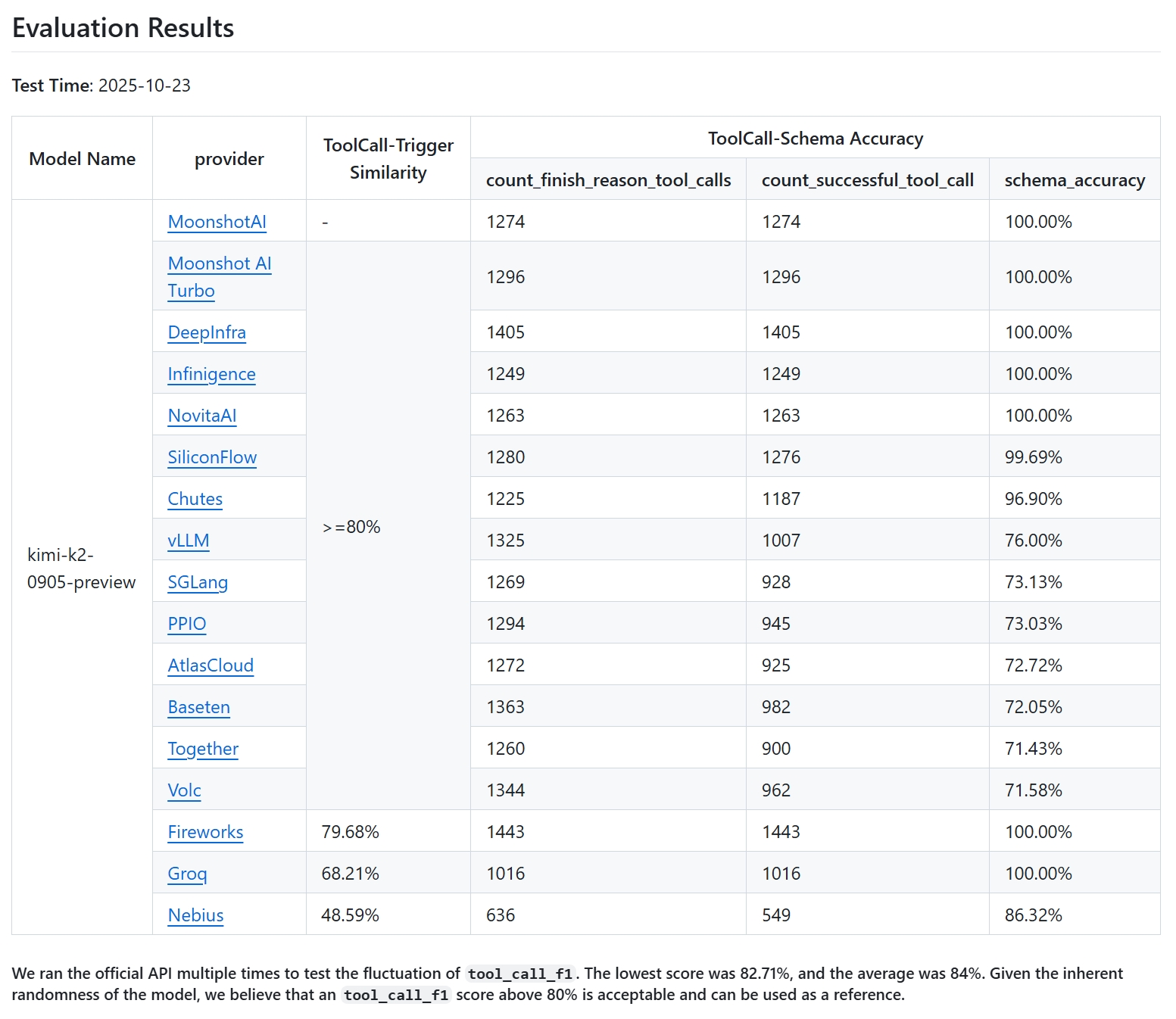
不过还有最后一点差距:vLLM 上会出现模型调用“当前请求中未声明的工具”(比如把历史里出现过的 img_gen 工具又 hallucinate 出来)。这是因为官方 API 内部使用了“Enforcer”机制,通过约束解码强制模型只能使用当前提供的工具,而 vLLM 目前还没有实现这一功能。Kimi 团队正在和 vLLM 团队合作推动这项特性落地。
这次调试给我带来的几点经验
-
chat template 是模型与 serving engine 的关键接口
集成新模型时,一定要仔细验证 template 在目标框架下的实际行为。 -
必要时剥开高层抽象
/v1/chat/completions很方便,但出问题时直接用/v1/completions+ 手动构造 prompt,能更快定位问题。 -
token ID 是最终真相
最疑难问题时,查看最终送进模型的 token 序列是最可靠的手段。 -
理解框架的设计哲学
vLLM 对**kwargs的严格处理是为了安全,理解这一点能避免走弯路。 -
开源生态的差距与机会
像 Enforcer 这样能显著提升可靠性的组件,目前多见于闭源服务,开源社区还有很多可以贡献的空间。
常见问题解答(FAQ)
现在用 Kimi K2 在 vLLM 上跑工具调用可靠吗?
可以,只要使用 chat template 已更新的模型版本(Kimi-K2-0905 的 94a4053 之后,或 Kimi-K2 的 0102674b 之后),成功率已大幅提升,和官方 API 差距主要在 Enforcer 特性上。
如何确认我用的模型版本是否已修复?
查看 Hugging Face 仓库的 commit 历史,确保在上述两个 commit 之后。推荐直接使用最新的模型卡。
我还需要手动做哪些额外处理吗?
建议在发送请求前,把对话历史中的工具调用 ID 统一规范化成 functions.func_name:idx 格式,能进一步减少模型被误导的概率。
vLLM 未来会支持 Enforcer 吗?
Kimi 团队正在和 vLLM 团队合作推进,值得期待。
调试类似问题时,有什么推荐的步骤?
-
先对比官方 API 表现确认基准 -
用手动 apply_chat_template + /completions 接口对比 -
检查最终 prompt 是否包含预期的特殊 token -
逐个排查 content 处理、工具 ID 格式等细节 -
必要时查看 token ID 序列
这次经历让我深刻感受到,开源社区和大模型厂商协作的力量。只要问题定位准确,大家都很愿意一起把体验推到最好。希望这篇复盘能帮你在部署 Kimi K2 时少走一些弯路。
(全文完,约 3500 字)

