

Uber 如何打造用于财务分析的对话式 AI 系统 Finch
How Uber Built a Conversational AI Agent for Financial Analysis
本文核心问题
Uber 是如何让财务分析从“写 SQL 查报表”变成“像和同事聊天一样获取实时财务数据”的?
在 Uber 这样一个每分钟都处理数百万笔交易的公司里,财务决策依赖的是“数据速度”。哪怕延迟几分钟,也可能影响全球范围的业务决策。Uber 工程团队发现,财务分析师们往往花费大量时间在数据提取上,而不是分析上。于是,一个嵌入 Slack、能理解自然语言的智能数据助手——Finch,诞生了。
目录
-
问题与目标:从数据碎片到即时洞察 -
Finch 是什么?核心功能与使用场景 -
架构设计:从数据层到语义层的智能协作 -
工作流程:Finch 如何理解并执行自然语言查询 -
性能与准确性:Uber 如何确保 Finch 可靠且高效 -
实践启示与反思 -
一页速览(One-Page Summary) -
常见问答 FAQ
问题与目标:从数据碎片到即时洞察
核心问题: Uber 为什么要为财务团队打造一个对话式 AI?
在 Finch 出现之前,Uber 财务团队的分析过程复杂且低效:
-
需要分别登录 Presto、IBM Planning Analytics、Oracle EPM、Google Docs 等多个平台; -
手动查找不同表格和系统的数据,耗时且易错; -
复杂查询必须通过写 SQL 完成,这要求非技术分析师具备数据库结构知识; -
若需额外支持,还要提交给数据科学团队,等待几个小时甚至几天。
问题的本质: 数据访问分散、技能门槛高、等待周期长。
Uber 的目标:
-
构建一个安全、实时的财务数据访问层; -
让分析师直接在 Slack 中用自然语言提问; -
系统自动理解意图、生成 SQL、调用数据源并返回结果。
于是,Uber 工程团队着手研发一套能“听懂人话、懂数据逻辑、会执行查询”的智能代理系统。
这个系统,就是——Finch。
Finch 是什么?核心功能与使用场景
核心问题: Finch 如何让财务数据查询变得像聊天一样自然?
1. 概述
Finch 是一个集成在 Slack 内部的 对话式财务数据智能体。
用户只需输入自然语言问题,Finch 就能:
-
解析语义 → 生成 SQL → 访问数据源; -
应用权限控制(RBAC); -
返回实时、格式化的查询结果; -
自动导出到 Google Sheets(当数据量较大时)。
使用示例:
用户:What was the GB value in US&C in Q4 2024?
Finch:Gross Bookings for US&C in Q4 2024 was $XXX million.
用户无需知道数据表名、字段名或结构。Finch 自动完成从意图识别到数据查询的全过程。
2. Finch 的独特价值
| 功能点 | Finch 的实现方式 | 用户收益 |
|---|---|---|
| 数据查询 | 自然语言转 SQL | 无需写 SQL |
| 数据准确性 | 基于单表数据集(Data Mart) | 减少表连接与错误 |
| 安全访问 | RBAC 权限控制 | 保护敏感信息 |
| 多模态输出 | Slack 内嵌结果 + Sheets 导出 | 可视化便捷 |
| 模糊匹配 | 语义别名识别(如“US&C”自动映射区域) | 提高自然语言理解度 |
| 实时响应 | 并行子代理执行 | 快速返回结果 |
架构设计:从数据层到语义层的智能协作
核心问题: Finch 的系统架构如何实现模块化、安全与高精度?
Uber 的设计目标是 “松耦合、高安全、强可扩展”。系统分为三层:
1. 数据层:简化与提速
-
使用 单表数据集(Single-table Data Mart) 存储关键指标。 -
避免复杂的多表连接,减少性能瓶颈。 -
数据表经人工策划,确保字段清晰、结构稳定。
价值:
这种方式让查询更快,也减少了 LLM 生成 SQL 时的结构混乱。
2. 语义层:自然语言到结构化数据的桥梁
-
基于 OpenSearch 存储字段与值的自然语言别名。 -
支持模糊匹配和多义词识别。
示例:
当用户输入 “US&C”,Finch 会自动映射到数据库中的 region = 'US and Canada'。
这层结构极大提高了模型生成 WHERE 条件的准确率。
3. 智能代理层:多代理协同架构
Finch 的智能代理系统基于 Uber 内部的 Generative AI Gateway 与 LangChain/LangGraph 框架。
主要组件:
-
Generative AI Gateway:统一接入多种大语言模型(LLM),可无缝切换或升级。 -
LangGraph:用于编排多智能体协作。 -
SQL Writer Agent:根据语义构建 SQL 查询。 -
Supervisor Agent:判断任务类型并分派给合适子代理。 -
Slack SDK & AI Assistant API:实现用户交互与状态反馈。 -
Google Sheets Exporter:用于导出大数据量结果。
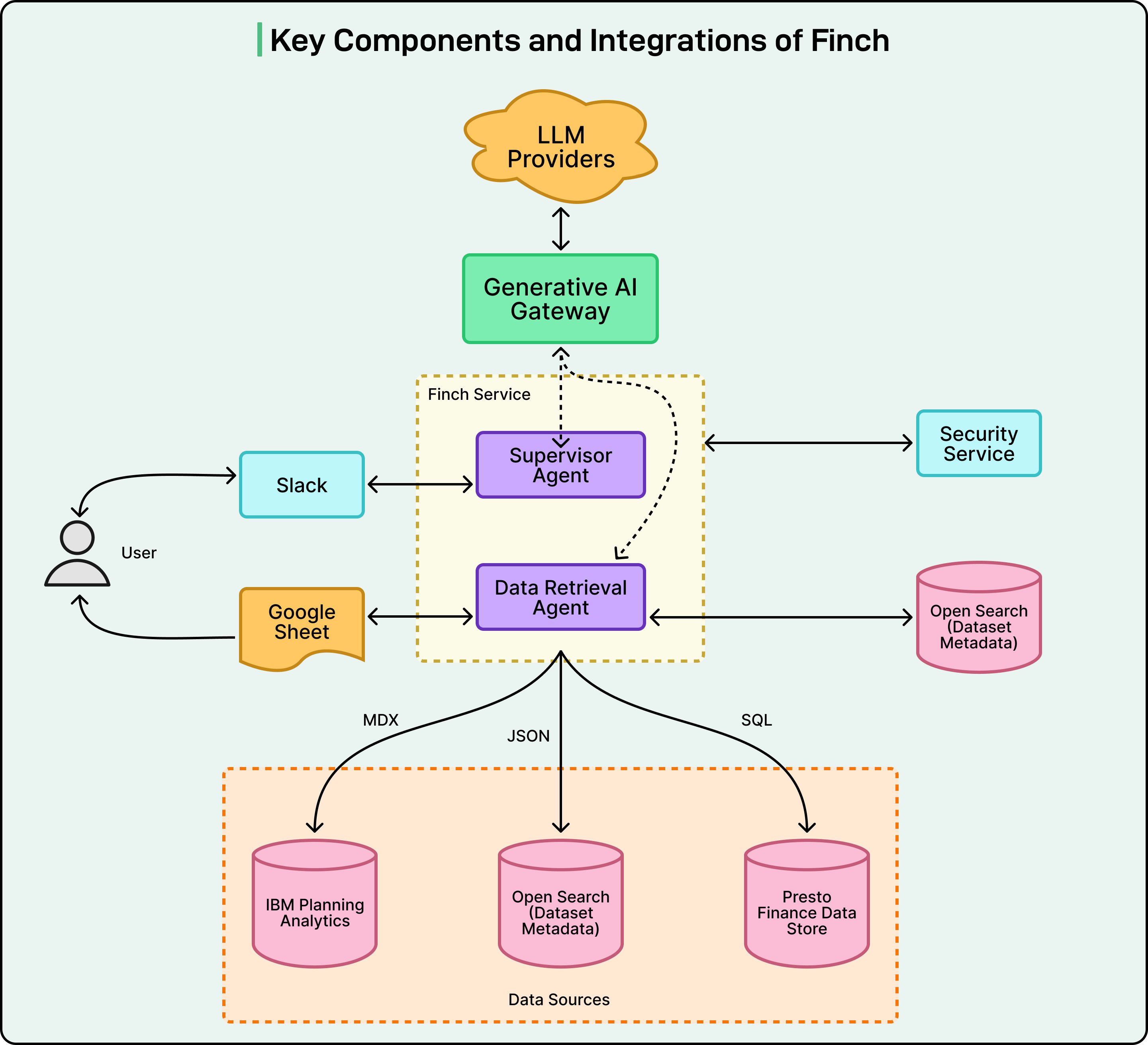
图片来源:Uber Engineering Blog

工作流程:Finch 如何理解并执行自然语言查询
核心问题: 当用户在 Slack 中输入一句话时,Finch 背后发生了什么?
步骤 1:消息接收与任务识别
-
用户在 Slack 输入问题; -
Supervisor Agent 接收输入,识别任务类型(数据检索 / 文档查询等); -
若是数据请求,任务转交 SQL Writer Agent。
步骤 2:语义解析与 SQL 构建
-
SQL Writer Agent 读取 OpenSearch 中的元数据; -
根据自然语言别名构建对应 SQL; -
选择正确数据表与过滤条件。
示例:
输入 “Compare US&C Q4 2024 with Q4 2023”,Finch 自动识别时间范围与区域字段并生成对比查询。
步骤 3:执行与实时反馈
-
Finch 执行 SQL 查询;
-
同时在 Slack 界面动态显示执行进度:
“Identifying data source…” → “Building SQL…” → “Executing query…”
-
查询结果以结构化消息返回;
-
若数据量大,自动导出到 Google Sheets。
步骤 4:多轮上下文理解
Finch 支持上下文保持。
当用户追问 “Compare to previous quarter”,系统会自动引用上次查询的上下文进行补全。
性能与准确性:Uber 如何确保 Finch 可靠且高效
核心问题: Finch 如何保证在大规模使用下仍能准确快速?
1. 持续准确性评估
Uber 为 Finch 建立了完整的测试与监控体系:
| 评估类型 | 说明 | 目标 |
|---|---|---|
| 子代理评估 | 比对生成 SQL 与“黄金查询” | 确保核心逻辑正确 |
| 任务路由准确性 | 检查 Supervisor 是否正确分派任务 | 防止错误路由 |
| 端到端验证 | 模拟真实查询场景 | 确认整体流程无误 |
| 回归测试 | 复跑历史查询比对结果 | 检测模型漂移 |
这种多层测试机制让 Finch 即便在模型或数据更新后,也能保持一致性输出。
2. 性能优化策略
-
并行子代理架构:任务分发到多个子代理并行执行,降低等待时间。 -
高效 SQL 优化:减少数据库负载,提高响应速度。 -
常用指标预取:缓存常见查询项,实现秒级响应。
结果:
即便面对高并发与复杂财务数据,Finch 仍能在几秒内返回结果,保持高可靠性。
实践启示与反思
核心问题: 从 Finch 的设计中,我们能学到什么?
“真正的智能系统,不是替代分析师,而是释放他们的时间。”
反思 1:技术的目标是“无摩擦”
Uber 并没有让财务分析师学习 SQL,而是让系统懂人话。
这种“以人为中心”的设计思路,是所有 AI 工具落地的关键。
反思 2:语义层是智能化的核心
LLM 并非万能。通过 OpenSearch 的语义映射,Finch 显著提升了模型的可解释性与稳定性。
这启示我们,语义结构化与人工策划数据集的结合,是企业级 AI 系统落地的关键平衡点。
反思 3:持续验证比单次部署更重要
Uber 用“黄金查询”和回归测试的机制,确保 Finch 不随时间漂移。
这说明,大模型应用的长期成功,取决于持续监控与反馈循环。
一页速览(One-Page Summary)
| 模块 | 功能要点 | 核心价值 |
|---|---|---|
| 目标 | 构建实时、安全、自然语言财务查询系统 | 提升决策速度 |
| 用户界面 | 集成于 Slack | 无需切换平台 |
| 核心技术 | LangGraph + OpenSearch + RBAC | 模块化、可扩展、安全 |
| 工作流程 | Supervisor → SQL Writer → Execution → Response | 清晰可追踪 |
| 性能保障 | 并行代理 + 缓存机制 | 秒级响应 |
| 准确性保障 | 多层评估与回归测试 | 稳定可靠 |
| 应用价值 | 让财务分析从“写 SQL”转为“问问题” | 提升团队生产力 |
常见问答 FAQ
Q1:Finch 能处理哪些类型的问题?
A1:支持基于自然语言的财务数据查询、对比分析与趋势检索。
Q2:Finch 是否需要访问多个数据库?
A2:不需要。它基于单表数据集(Data Mart),查询路径更短更快。
Q3:如何保证数据安全?
A3:通过角色访问控制(RBAC),确保敏感数据仅对授权用户可见。
Q4:Finch 是否依赖单一大模型?
A4:不是。通过 Generative AI Gateway,可自由切换或升级 LLM。
Q5:查询结果能导出吗?
A5:当数据量较大时,系统自动导出到 Google Sheets 并分享链接。
Q6:Finch 如何学习新的财务术语?
A6:语义层中的 OpenSearch 可动态更新别名和字段映射。
Q7:未来 Finch 会扩展哪些功能?
A7:将支持预测分析、报告生成及更丰富的财务自动化任务。
Q8:Finch 的最大意义是什么?
A8:它让数据访问“人性化”——分析师专注洞察,而不是查询。

