★REFRAG:让AI生成内容更快更高效的新方法★
你是否遇到过这样的情况:向AI提问时,如果问题需要结合大量背景知识,回答速度就会变慢,甚至卡顿?就像在图书馆里找资料,如果管理员每次都要翻遍所有书架,自然效率低下。今天我们要介绍的REFRAG技术,就像给图书馆装了智能导航系统,让AI能快速定位关键信息。
一、为什么AI需要”减负”?
1.1 AI的”记忆负担”
现代AI模型(比如大家常用的聊天机器人)就像一个超大的知识库。当我们给AI提供很多背景信息时,它需要把这些信息全部记住(术语叫”长上下文处理”)。但就像人脑记太多东西会反应变慢,AI处理长文本时也会遇到两个麻烦:
- 🍄
响应延迟:生成第一个字的时间(TTFT)会明显增加 - 🍄
内存压力:需要存储的中间结果(KV缓存)会占用更多硬件资源
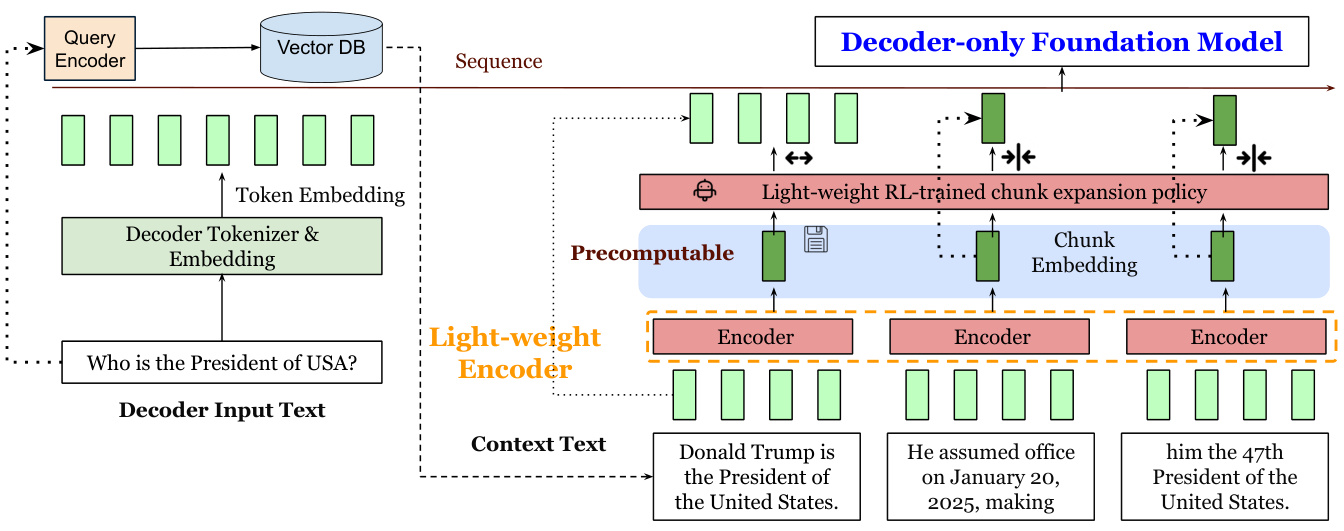
传统方法(左)需要处理所有上下文token,而REFRAG(右)使用压缩后的块嵌入
1.2 RAG场景的特殊性
在检索增强生成(RAG)这类应用中,AI的表现更加明显。想象你在写论文时,需要同时打开100篇相关文献:
- 🍄
其中只有5篇真正有用 - 🍄
很多内容存在重复 - 🍄
不同段落之间关联性不强
这种情况下,AI就像在处理大量低关联度的信息碎片,传统方法却要同等对待所有内容。
二、REFRAG的三步提速法
研究者提出的REFRAG框架就像给AI装了个智能预处理器,通过三个关键步骤实现加速:
2.1 压缩:化零为整
技术原理:
将长文本分割成多个块(比如每块16个词),用轻量级编码器(如RoBERTa)将每个块压缩成单个向量表示。
类比理解:
就像把整本书拆分成多个章节,每个章节用一句话概括核心内容。这样需要处理的信息量就大大减少了。
2.2 感知:智能识别关键块
通过强化学习训练策略网络,动态判断哪些块需要保持完整细节,哪些可以用压缩版:
# 简化版选择策略伪代码
def select_chunks(blocks, policy_net):
important_blocks = []
for i, block in enumerate(blocks):
if policy_net.predict(block) > threshold:
important_blocks.append(block)
return important_blocks
2.3 扩展:按需还原细节
在生成答案过程中,对标记为重要的块恢复完整信息,其他块保持压缩状态。就像写论文时:
- 🍄
常规引用用摘要版本 - 🍄
关键数据源展开原文
三、实际效果有多惊人?
3.1 速度提升对比
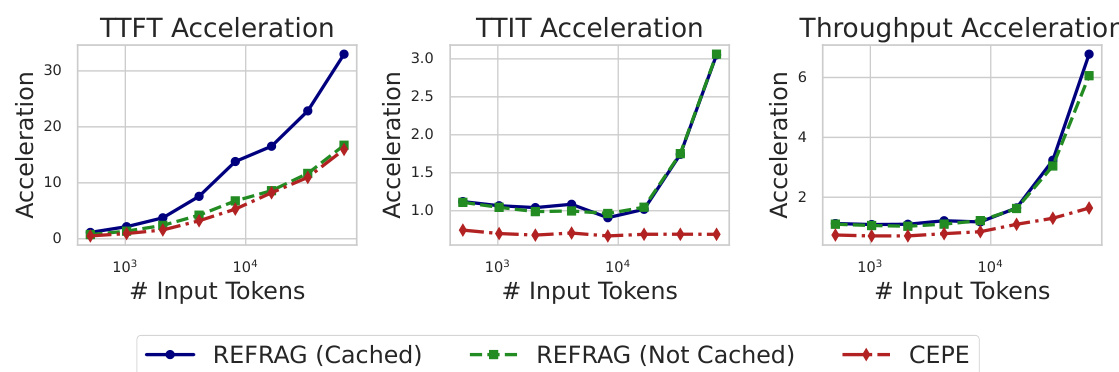
在16384 token长文本场景下,REFRAG-16比传统方法快16.5倍
3.2 性能保持验证
在多个数据集测试中,REFRAG在大幅提升速度的同时:
- 🍄
困惑度(模型预测准确度指标)保持稳定 - 🍄
在多轮对话场景下表现更优(见下表)
四、典型应用场景
4.1 智能客服系统
问题:用户连续追问时,AI需要结合历史对话和知识库
REFRAG方案:
- 🍄
历史对话分块压缩存储 - 🍄
当前问题实时检索相关块 - 🍄
动态决定哪些历史块需要展开
4.2 学术文献分析
场景:分析100篇相关论文时
优势:
- 🍄
压缩低相关段落节省内存 - 🍄
重要方法部分保持完整 - 🍄
支持更长的文献处理
4.3 代码助手
应用:帮助开发者理解大型代码库
效果:
# 传统方法需要处理全部代码token
full_code = load_entire_repo() # 内存占用大
# REFRAG方案
compressed_blocks = compress_repo(full_code)
important_blocks = policy.select(compressed_blocks)
response = generate_answer(important_blocks)
五、技术细节解密
5.1 训练策略
采用两阶段训练法:
-
持续预训练:用”段落预测”任务对齐编码器-解码器 -
微调阶段:针对具体任务(如QA)进行指令微调
5.2 课程学习设计
就像教孩子先学简单加减再学微积分,训练时采用渐进式难度:
- 🍄
初期:单块重建(压缩1块→还原) - 🍄
中期:多块组合(压缩2-4块→还原) - 🍄
后期:全量训练(任意块组合)
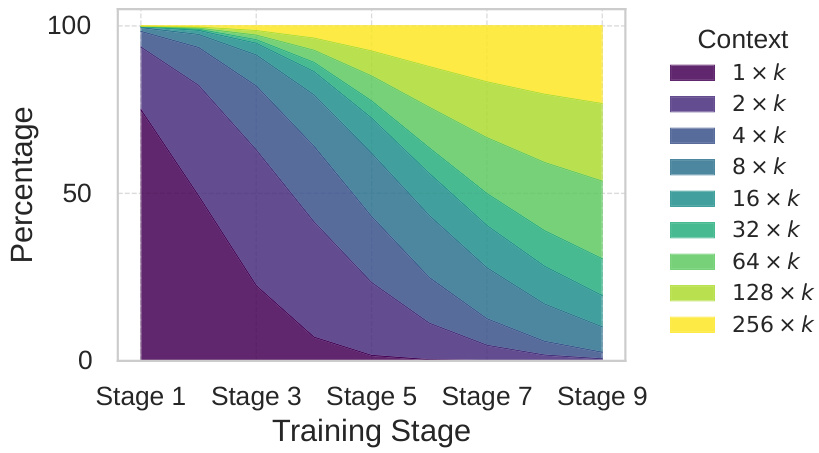
训练数据中长序列比例逐渐增加
5.3 RL策略网络
使用GRPO算法训练选择策略:
# 奖励函数设计
def calculate_reward(output, reference):
return -perplexity(output, reference) # 困惑度越低奖励越高
# 策略更新
policy_net.update(advantages, old_log_probs)
六、常见问题解答
Q1:REFRAG需要修改模型架构吗?
不需要。完全兼容现有LLM架构(如LLaMA),只需在推理阶段增加编码器模块。
Q2:压缩率k如何选择?
- 🍄
k=8:适合中等长度文本(4k-8k tokens) - 🍄
k=16:长文本场景(>8k tokens) - 🍄
k=32:极限压缩场景,性能略有下降
Q3:和其他方法(如CEPE)区别?
Q4:实际部署需要什么资源?
- 🍄
轻量级编码器(如RoBERTa-Large约350M参数) - 🍄
支持BF16精度的GPU(如A100) - 🍄
推理时需要额外存储块嵌入
七、未来发展方向
-
动态块大小:根据内容重要性自动调整块大小 -
多模态支持:扩展到图文混合场景 -
在线学习:实时更新重要块判断策略 -
硬件优化:定制化压缩指令集
REFRAG的出现让我们看到,AI系统就像智能手机——硬件性能提升很重要,但更需要智能化的资源调度算法。随着类似技术的不断突破,未来AI助手将能更流畅地处理复杂的长文本任务。
