

随着人工智能技术的飞速发展,语音合成(TTS)技术已经从简单的机器朗读进化为能够理解上下文、模拟复杂情感并支持多语言实时交互的先进系统。在众多开源模型中,Qwen3-TTS 凭借其强大的端到端架构、极低的延迟表现以及卓越的语音还原能力,成为了开发者和研究人员的关注焦点。
本文将基于官方文档与技术报告,深入剖析 Qwen3-TTS 的技术细节、模型架构、多样化的应用场景以及详尽的性能评估数据,帮助您全面了解这款工具的潜力与应用方法。
核心概览与技术突破
Qwen3-TTS 是一款覆盖中文、英文、日语、韩语、德语、法语、俄语、葡萄牙语、西班牙语和意大利语等 10 种主要语言及其多种方言语音特征的文本转语音模型。它不仅仅是一个朗读工具,更是一个具备强大上下文理解能力的智能语音生成系统。它能够根据指令和文本语义自适应地控制语调、语速和情感表达,显著提升了对噪声文本的鲁棒性。

为了满足不同场景的需求,Qwen3-TTS 在技术层面实现了四个关键维度的突破:
1. 强大的语音表征能力
该模型搭载了自研的 Qwen3-TTS-Tokenizer-12Hz 分词器。这一组件不仅实现了高效的声学压缩,还完成了语音信号的高维语义建模。它能够完整保留副语言信息(如呼吸声、停顿)和声学环境特征,并通过轻量级的非 DiT(Diffusion Transformer)架构,实现了高速、高保真的语音重建。这意味着生成的声音不仅清晰,而且富有“人味”。
2. 通用端到端架构
Qwen3-TTS 采用了离散多码本大语言模型架构。这种架构实现了全信息的端到端语音建模,彻底避开了传统语言模型(LM)+ 扩散模型方案中常见的信息瓶颈和级联误差。这种设计不仅显著增强了模型的通用性,还提升了生成效率和性能上限,使得单一模型即可应对多种复杂的语音生成任务。
3. 极低延迟的流式生成
对于实时交互场景(如实时对话助手),延迟是至关重要的指标。Qwen3-TTS 基于创新的“双轨”混合流式生成架构,使得单个模型能够同时支持流式和非流式生成。在实际应用中,它可以在输入单个字符后立即输出首个音频包,端到端合成延迟低至 97ms。这一表现完全满足了实时交互场景的严苛要求。
4. 智能文本理解与语音控制
模型支持基于自然语言指令的语音生成。用户可以通过文本灵活控制音色、情感和韵律等多维声学属性。通过深度整合文本语义理解,模型能够自适应地调整语调、节奏和情感表达,真正实现了“所想即所得”的拟人化输出效果。
模型架构与版本选择
架构设计
Qwen3-TTS 的架构设计旨在平衡生成质量与推理效率。其核心在于结合了高维语义建模与轻量级声码器的优势,通过离散码本作为中间表示,让语言模型直接预测语音单元。这种设计使得模型在保持高音质的同时,极大降低了计算开销。

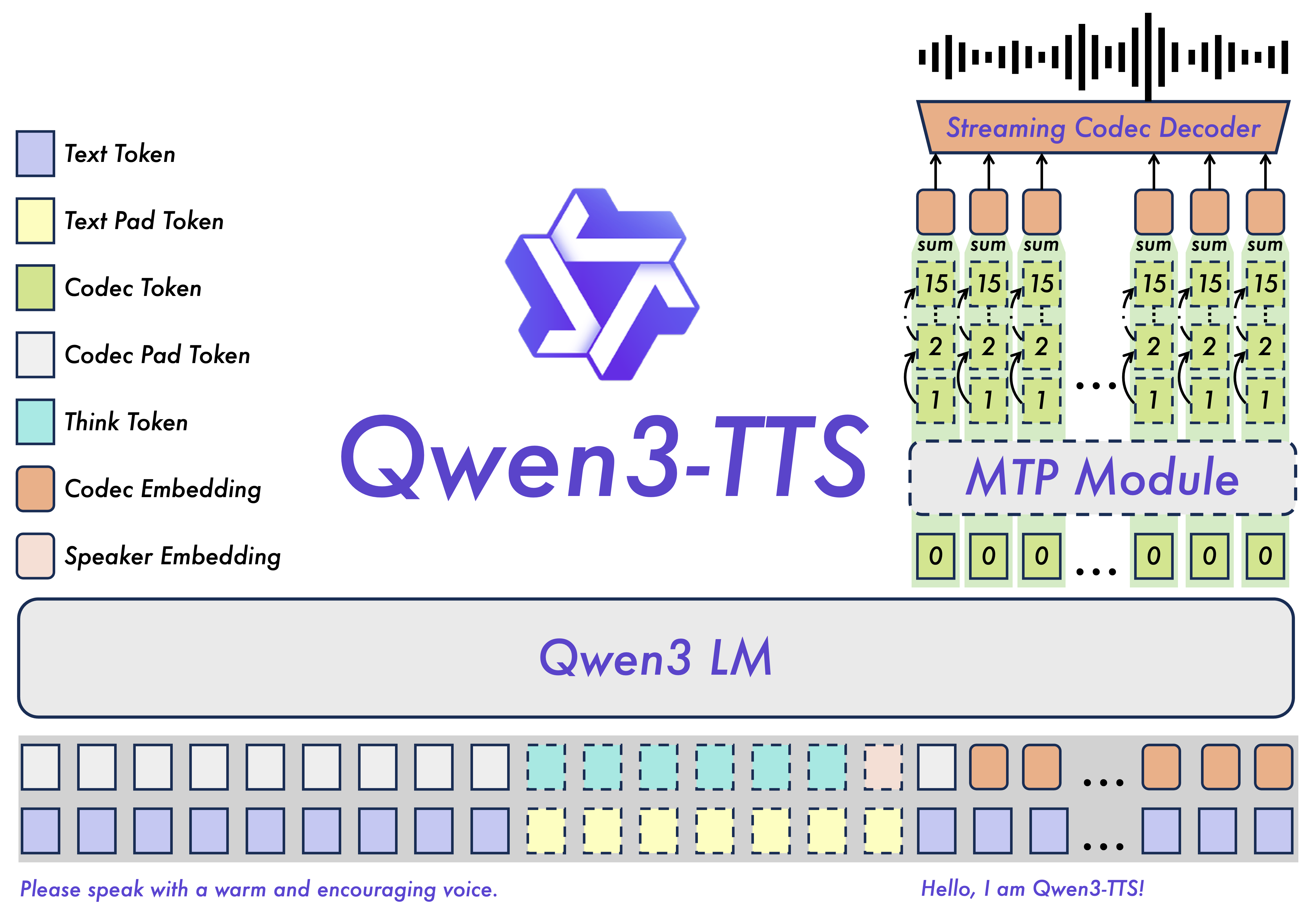
现有模型版本与下载指南
为了适应不同的开发需求,Qwen3-TTS 发布了多个不同规格的模型。以下是已发布模型的详细介绍,您可以根据具体应用场景选择最合适的版本。
Tokenizer
所有模型的语音编解码基础。
-
Qwen3-TTS-Tokenizer-12Hz: 负责将输入语音编码为码本,并将码本解码回语音。
主要生成模型对比表
| 模型名称 | 主要功能特性 | 语言支持 | 流式生成 | 指令控制 |
|---|---|---|---|---|
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | 根据用户提供的描述进行声音设计(如音色、年龄、性格)。 | 中、英、日、韩、德、法、俄、葡、西、意 | ✅ 支持 | ✅ 支持 |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | 通过用户指令控制目标音色;支持 9 种覆盖不同性别、年龄、语言和方言组合的高级音色。 | 中、英、日、韩、德、法、俄、葡、西、意 | ✅ 支持 | ✅ 支持 |
| Qwen3-TTS-12Hz-1.7B-Base | 基础模型,支持从用户音频输入进行 3 秒快速声音克隆;可用于微调其他模型。 | 中、英、日、韩、德、法、俄、葡、西、意 | ✅ 支持 | – |
| Qwen3-TTS-12Hz-0.6B-CustomVoice | 支持 9 种高级音色,覆盖各种组合。体积较小。 | 中、英、日、韩、德、法、俄、葡、西、意 | ✅ 支持 | – |
| Qwen3-TTS-12Hz-0.6B-Base | 基础模型,支持 3 秒快速声音克隆;可用于微调。体积较小。 | 中、英、日、韩、德、法、俄、葡、西、意 | ✅ 支持 | – |
如何下载:
在 qwen-tts 包或 vLLM 中加载模型时,模型权重会自动下载。但如果运行环境不适合在执行时下载,可以使用以下命令手动下载。
通过 ModelScope 下载(推荐中国大陆用户):
pip install -U modelscope
modelscope download --model Qwen/Qwen3-TTS-Tokenizer-12Hz --local_dir ./Qwen3-TTS-Tokenizer-12Hz
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local_dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-Base --local_dir ./Qwen3-TTS-12Hz-1.7B-Base
modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-Base --local_dir ./Qwen3-TTS-12Hz-0.6B-Base
通过 Hugging Face 下载:
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-TTS-Tokenizer-12Hz --local_dir ./Qwen3-TTS-Tokenizer-12Hz
huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local_dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-Base --local_dir ./Qwen3-TTS-12Hz-1.7B-Base
huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-Base --local_dir ./Qwen3-TTS-12Hz-0.6B-Base
快速上手:环境配置与使用指南
环境搭建
最快的使用方式是从 PyPI 安装 qwen-tts Python 包。为了避免依赖冲突,强烈建议在一个新的、隔离的环境中配置。
创建 Python 3.12 环境:
conda create -n qwen3-tts python=3.12 -y
conda activate qwen3-tts
安装核心包:
pip install -U qwen-tts
如果您打算本地开发或修改代码,可以从源码安装:
git clone https://github.com/QwenLM/Qwen3-TTS.git
cd Qwen3-TTS
pip install -e .
性能优化建议:
建议安装 FlashAttention 2 以减少显存占用并提升推理速度。
pip install -U flash-attn --no-build-isolation
注意:如果机器内存小于 96GB 且 CPU 核心较多,建议限制并发任务数:
MAX_JOBS=4 pip install -U flash-attn --no-build-isolation
FlashAttention 2 仅在模型加载为 torch.float16 或 torch.bfloat16 时可用。
Python 包使用实战
1. 自定义语音生成
适用于 Qwen3-TTS-12Hz-1.7B/0.6B-CustomVoice 模型。您可以指定语言、说话人以及情感指令。
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# 单条推理
wavs, sr = model.generate_custom_voice(
text="其实我真的有发现,我是一个特别善于观察别人情绪的人。",
language="Chinese", # 也可以设为 "Auto" 或省略以自适应;如果明确知道目标语言,建议显式设置。
speaker="Vivian",
instruct="用特别愤怒的语气说", # 如不需要,可省略。
)
sf.write("output_custom_voice.wav", wavs[0], sr)
支持的预设说话人列表:
| 说话人 | 声音描述 | 母语 |
|---|---|---|
| Vivian | 明亮、略带锋芒的年轻女性声音。 | 中文 |
| Serena | 温暖、温柔的年轻女性声音。 | 中文 |
| Uncle_Fu | 沉稳、低沉醇厚的资深男性声音。 | 中文 |
| Dylan | 清晰自然的年轻北京男性声音。 | 中文(北京方言) |
| Eric | 活泼、略带沙哑明亮的成都男性声音。 | 中文(四川方言) |
| Ryan | 节奏感强烈的动态男性声音。 | 英文 |
| Aiden | 阳光、中音清晰的美国男性声音。 | 英文 |
| Ono_Anna | 轻盈灵动的俏皮日本女性声音。 | 日语 |
| Sohee | 情感丰富的温暖韩国女性声音。 | 韩语 |
2. 声音设计
适用于 Qwen3-TTS-12Hz-1.7B-VoiceDesign 模型。您可以通过自然语言描述来创造声音,例如“萝莉女声”、“低沉男声”等。
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
wavs, sr = model.generate_voice_design(
text="哥哥,你回来啦,人家等了你好久好久了,要抱抱!",
language="Chinese",
instruct="体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
)
sf.write("output_voice_design.wav", wavs[0], sr)
3. 声音克隆
适用于 Qwen3-TTS-12Hz-1.7B/0.6B-Base 模型。只需提供一个参考音频片段及其转录文本,即可克隆音色。
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
ref_audio = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone.wav"
ref_text = "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you."
wavs, sr = model.generate_voice_clone(
text="I am solving the equation: x = [-b ± √(b²-4ac)] / 2a? Nobody can — it's a disaster (◍•͈⌔•͈◍), very sad!",
language="English",
ref_audio=ref_audio,
ref_text=ref_text,
)
sf.write("output_voice_clone.wav", wavs[0], sr)
高级用法:复用提示特征
如果您需要多次使用同一个参考音色(避免重复计算特征),可以先构建提示。
prompt_items = model.create_voice_clone_prompt(
ref_audio=ref_audio,
ref_text=ref_text,
x_vector_only_mode=False,
)
wavs, sr = model.generate_voice_clone(
text=["Sentence A.", "Sentence B."],
language=["English", "English"],
voice_clone_prompt=prompt_items,
)
4. 声音设计后克隆
这是一个非常实用的组合工作流:
-
使用 VoiceDesign 模型合成一段符合目标角色的短参考音频。 -
将该音频输入 Base 模型的 create_voice_clone_prompt构建可复用提示。 -
调用 generate_voice_clone生成新内容,无需每次重新提取特征。这对于保持角色长文本一致性非常有用。
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# 第一步:使用 VoiceDesign 模型创建参考音频
design_model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
ref_text = "H-hey! You dropped your... uh... calculus notebook? I mean, I think it's yours? Maybe?"
ref_instruct = "Male, 17 years old, tenor range, gaining confidence - deeper breath support now, though vowels still tighten when nervous"
ref_wavs, sr = design_model.generate_voice_design(
text=ref_text,
language="English",
instruct=ref_instruct
)
sf.write("voice_design_reference.wav", ref_wavs[0], sr)
# 第二步:使用 Base 模型构建克隆提示
clone_model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
voice_clone_prompt = clone_model.create_voice_clone_prompt(
ref_audio=(ref_wavs[0], sr), # 或者使用文件路径 "voice_design_reference.wav"
ref_text=ref_text,
)
# 第三步:复用提示生成多条内容
sentences = [
"No problem! I actually... kinda finished those already? If you want to compare answers or something...",
"What? No! I mean yes but not like... I just think you're... your titration technique is really precise!",
]
wavs, sr = clone_model.generate_voice_clone(
text=sentences,
language=["English", "English"],
voice_clone_prompt=voice_clone_prompt,
)
for i, w in enumerate(wavs):
sf.write(f"clone_batch_{i}.wav", w, sr)
5. Tokenizer 编解码
如果仅需对音频进行编码和解码用于传输或训练,可以使用 Qwen3TTSTokenizer。
import soundfile as sf
from qwen_tts import Qwen3TTSTokenizer
tokenizer = Qwen3TTSTokenizer.from_pretrained(
"Qwen/Qwen3-TTS-Tokenizer-12Hz",
device_map="cuda:0",
)
enc = tokenizer.encode("https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/tokenizer_demo_1.wav")
wavs, sr = tokenizer.decode(enc)
sf.write("decode_output.wav", wavs[0], sr)
本地 Web UI 演示部署
安装 qwen-tts 包后,可以直接运行 qwen-tts-demo 启动 Web 界面。
启动命令示例:
# CustomVoice 模型
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --ip 0.0.0.0 --port 8000
# VoiceDesign 模型
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --ip 0.0.0.0 --port 8000
# Base 模型
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base --ip 0.0.0.0 --port 8000
之后在浏览器访问 http://<your-ip>:8000。
Base 模型的 HTTPS 注意事项:
为了防止现代浏览器在远程访问时出现麦克风权限问题,Base 模型部署建议/必须运行在 HTTPS 服务下。可以使用 --ssl-certfile 和 --ssl-keyfile 启用 HTTPS。
生成自签名证书(有效期 365 天):
openssl req -x509 -newkey rsa:2048 \
-keyout key.pem -out cert.pem \
-days 365 -nodes \
-subj "/CN=localhost"
以 HTTPS 模式运行 Demo:
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base \
--ip 0.0.0.0 --port 8000 \
--ssl-certfile cert.pem \
--ssl-keyfile key.pem \
--no-ssl-verify
然后访问 https://<your-ip>:8000。
vLLM 集成与推理优化
vLLM 提供了对 Qwen3-TTS 的首日支持(Day-0 support),通过 vLLM-Omni 可以进行高效的部署和推理。目前支持离线推理,在线服务将在后续版本支持。
离线推理示例
首先克隆 vLLM-Omni 仓库并进入示例目录:
git clone https://github.com/vllm-project/vllm-omni.git
cd vllm-omni/examples/offline_inference/qwen3_tts
执行不同的任务:
# 单个样本 CustomVoice 任务
python end2end.py --query-type CustomVoice
# 批量样本 CustomVoice 任务
python end2end.py --query-type CustomVoice --use-batch-sample
# 单个样本 VoiceDesign 任务
python end2end.py --query-type VoiceDesign
# 批量样本 VoiceDesign 任务
python end2end.py --query-type VoiceDesign --use-batch-sample
# 单个样本 Base 任务(in-context learning 模式)
python end2end.py --query-type Base --mode-tag icl
深度性能评估
为了客观衡量 Qwen3-TTS 的性能,研究团队在多个基准测试集上进行了详尽的评估。所有推理均在 dtype=torch.bfloat16 和 max_new_tokens=2048 设置下运行。
1. 语音生成基准
零样本语音生成 – Seed-TTS 测试集
衡量指标:词错误率(WER),越低越好。
| 模型 | 中文 WER | 英文 WER |
|---|---|---|
| Seed-TTS (Anastassiou et al., 2024) | 1.12 | 2.25 |
| MaskGCT | 2.27 | 2.62 |
| E2 TTS | 1.97 | 2.19 |
| F5-TTS | 1.56 | 1.83 |
| Spark TTS | 1.20 | 1.98 |
| Llasa-8B | 1.59 | 2.97 |
| KALL-E | 0.96 | 1.94 |
| FireRedTTS 2 | 1.14 | 1.95 |
| CosyVoice 3 | 0.71 | 1.45 |
| MiniMax-Speech | 0.83 | 1.65 |
| Qwen3-TTS-25Hz-0.6B-Base | 1.18 | 1.64 |
| Qwen3-TTS-25Hz-1.7B-Base | 1.10 | 1.49 |
| Qwen3-TTS-12Hz-0.6B-Base | 0.92 | 1.32 |
| Qwen3-TTS-12Hz-1.7B-Base | 0.77 | 1.24 |
分析: 在 Seed-TTS 测试集上,Qwen3-TTS-12Hz-1.7B-Base 在英文部分表现最佳,中文部分仅次于 CosyVoice 3,整体表现出极强的一致性和低错误率。
2. 多语言语音生成
TTS 多语言测试集
衡量指标:WER(内容一致性,越低越好)和余弦相似度(SIM,说话人相似度,越高越好)。
| 语言 | Qwen3-TTS-12Hz-1.7B-Base WER | Qwen3-TTS-12Hz-1.7B-Base SIM | MiniMax WER | ElevenLabs SIM |
|---|---|---|---|---|
| 中文 | 0.777 | 0.799 | 2.252 | 0.677 |
| 英文 | 0.934 | 0.775 | 2.164 | 0.613 |
| 德语 | 1.235 | 0.775 | 1.906 | 0.614 |
| 意大利语 | 0.948 | 0.817 | 1.543 | 0.579 |
| 葡萄牙语 | 1.526 | 0.817 | 1.877 | 0.711 |
| 西班牙语 | 1.126 | 0.814 | 1.029 | 0.615 |
| 日语 | 3.823 | 0.788 | 3.519 | 0.738 |
| 韩语 | 1.755 | 0.799 | 1.747 | 0.700 |
| 法语 | 2.858 | 0.714 | 4.099 | 0.535 |
| 俄语 | 3.212 | 0.792 | 4.281 | 0.676 |
分析: Qwen3-TTS-12Hz-1.7B-Base 在大多数语言的 WER(内容准确性)和 SIM(说话人相似度)之间取得了极佳的平衡。特别是在中文、英语、意大利语、葡萄牙语和法语上,其综合性能优于对比模型 MiniMax 和 ElevenLabs。
3. 跨语言语音生成
Cross-Lingual 基准
衡量指标:混合错误率(英文为 WER,其他为 CER,越低越好)。
| 任务 | Qwen3-TTS-12Hz-1.7B-Base | CosyVoice3 | CosyVoice2 |
|---|---|---|---|
| 英转中 | 4.77 | 5.09 | 13.5 |
| 日转中 | 3.43 | 3.05 | 48.1 |
| 韩转中 | 1.08 | 1.06 | 7.70 |
| 中转英 | 2.77 | 2.98 | 6.47 |
| 日转英 | 3.04 | 4.20 | 17.1 |
| 韩转英 | 3.09 | 4.19 | 11.2 |
| 中转日 | 8.40 | 7.08 | 13.1 |
| 英转日 | 7.21 | 6.80 | 14.9 |
| 韩转日 | 3.67 | 3.93 | 5.86 |
| 中转韩 | 4.82 | 14.4 | 24.8 |
| 英转韩 | 5.14 | 5.87 | 21.9 |
| 日转韩 | 5.59 | 7.92 | 21.5 |
分析: 在 12 项跨语言任务中,Qwen3-TTS-12Hz-1.7B-Base 在 9 项任务上取得了最佳成绩,显著优于 CosyVoice 系列模型,展现了强大的跨语言迁移能力。
4. 可控语音生成
InstructTTSEval 评估
衡量指标:属性感知与合成准确率(APS),描述-语音一致性(DSD),响应精度(RP)。
| 类型 | 模型 | 英文 APS | 英文 DSD | 英文 RP |
|---|---|---|---|---|
| Voice Design | Qwen3TTS-12Hz-1.7B-VD | 82.9 | 82.4 | 68.4 |
| Voice Design | Mimo-Audio-7B-Instruct | 80.6 | 77.6 | 59.5 |
| Voice Design | Hume | 83.0 | 75.3 | 54.3 |
| Target Speaker | Qwen3TTS-12Hz-1.7B-CustomVoice | 77.3 | 77.1 | 63.7 |
| Target Speaker | Gemini-flash | 92.3 | 93.8 | 80.1 |
分析: 在语音设计任务中,Qwen3-TTS 表现出色,各项指标均大幅领先于 Mimo 和 Hume 等模型。虽然 Gemini-flash 在目标说话人任务上表现优异,但作为一个通用大模型,Qwen3-TTS 作为一个专用 TTS 模型在可控性上的表现依然极具竞争力。
5. 语音分词器基准
语义语音分词器对比
衡量指标:PESQ (感知语音质量), STOI (短时客观可懂度), UTMOS (主观 MOS 预测), SIM (相似度)。
| 模型 | PESQ_WB | STOI | UTMOS | SIM |
|---|---|---|---|---|
| SpeechTokenizer | 2.60 | 0.92 | 3.90 | 0.85 |
| X-codec 2 | 2.43 | 0.92 | 4.13 | 0.82 |
| Mimi | 2.88 | 0.94 | 3.87 | 0.87 |
| Qwen-TTS-Tokenizer-12Hz | 3.21 | 0.96 | 4.16 | 0.95 |
分析: 自研的 Qwen-TTS-Tokenizer-12Hz 在所有关键指标上均大幅领先于业界主流分词器(如 Mimi, X-codec 2 等),这为 Qwen3-TTS 的高保真重建奠定了坚实基础。
DashScope API 使用
为了方便用户快速体验,Qwen3-TTS 也提供了 DashScope API 接口。
常见问题解答 (FAQ)
Q: Qwen3-TTS 支持哪些语言?
A: 目前支持中文、英语、日语、韩语、德语、法语、俄语、葡萄牙语、西班牙语和意大利语共 10 种主要语言,并包含多种方言音色。
Q: Base 模型和 CustomVoice 模型有什么区别?
A: Base 模型主要用于声音克隆,即输入一段参考音频来模仿其音色。CustomVoice 模型则内置了多种预设的高级音色(如 Vivian, Ryan 等),并支持通过指令改变情感和语调,更适合直接使用固定角色的场景。
Q: 声音设计和声音克隆哪个效果更好?
A: 这取决于具体需求。如果您有特定的目标音频样本,声音克隆能最大程度还原该音色。如果您想创造一个不存在的人物形象(如“年轻、活泼的美国女孩”),声音设计模型可以根据文本描述生成相应的声音,甚至可以结合两者,先用设计模型生成参考音频,再用克隆模型批量生成内容。
Q: 推理需要什么样的硬件配置?
A: 建议使用支持 CUDA 的 GPU。虽然文档未给出最低显存要求,但考虑到 1.7B 参数量及 FlashAttention 的使用,建议显存在 8GB 以上以获得流畅体验,使用 bfloat16 精度可以进一步节省显存。
Q: 如何实现流式生成?
A: Qwen3-TTS 的模型架构原生支持流式生成。在使用 vLLM 或 qwen-tts 包时,只需调用相关接口即可利用其 97ms 的低延迟特性输出音频流。
Q: 为什么 Web UI 部署 Base 模型需要 HTTPS?
A: 这是因为 Base 模型的 Web UI 需要调用浏览器的麦克风来录制参考音频。现代浏览器出于安全策略,通常只允许在 HTTPS(或 localhost)环境下访问麦克风。因此,远程访问必须配置 SSL 证书。
Q: 12Hz 和 25Hz 模型有何区别?
A: 12Hz 模型使用了更先进的 12Hz Tokenizer(Qwen-TTS-Tokenizer-12Hz),具有更高的压缩比和语义建模能力。从评估数据来看,12Hz 模型在音质(PESQ, STOI)和大多数 WER 指标上通常优于 25Hz 模型。

