

Qwen-Image-Edit 深度体验:人人都能上手的 AI 图像精修利器
把 20B 大模型的能力装进你的电脑,无需设计基础也能改图、加字、换背景
开场白:为什么你需要一款“听得懂人话”的修图工具?
拍照五分钟,修图两小时?
想换背景却抠图抠到怀疑人生?
想在海报里改几个字,却苦于找不到原文件?
如果你有类似的烦恼,Qwen-Image-Edit 也许正是答案。它把 20B 参数的 Qwen-Image 大模型浓缩成一个命令行就能跑起来的工具,中文、英文都能听懂,既能改画面,又能改文字,还能保持原图风格不变。本文用通俗语言带你从 0 到 1 玩明白它。
Qwen-Image-Edit 是什么?
一句话总结:
Qwen-Image-Edit = 语义理解 + 视觉保真 + 精准文字编辑,三大能力合体的开源图像编辑大模型。
| 能力维度 | 它能做什么 | 对普通用户意味着什么 |
|---|---|---|
| 语义编辑 | 换风格、旋转视角、IP 再创作 | 把一张自拍变成吉卜力画风,或把吉祥物换个姿势做表情包 |
| 外观编辑 | 增删元素、改颜色、局部精修 | 去掉照片里乱入的路人,或把衣服换成喜欢的配色 |
| 文字编辑 | 中英双语增删改,字体样式保持一致 | 海报有错别字直接改,不用再开 PS 找源文件 |
安装:3 行命令搞定环境
以 Linux + Python 3.10 为例,Windows/Mac 同理
-
装好 PyTorch(CUDA 11.8+) -
升级 diffusers pip install --upgrade "git+https://github.com/huggingface/diffusers" -
克隆示例代码(官方已集成在 ModelScope 管道里,下文直接调用即可)
无额外步骤,直接跳到“实战”。
5 分钟实战:从 0 到出图
场景 1:把兔子换成紫色 + 加闪光灯背景
from PIL import Image
import torch
from modelscope import QwenImageEditPipeline
pipe = QwenImageEditPipeline.from_pretrained("Qwen/Qwen-Image-Edit")
pipe = pipe.to("cuda", torch.bfloat16)
image = Image.open("rabbit.jpg").convert("RGB")
prompt = "Change the rabbit's color to purple, with a flash light background."
out = pipe(
image=image,
prompt=prompt,
true_cfg_scale=4.0,
num_inference_steps=50,
generator=torch.manual_seed(0)
)
out.images[0].save("purple_rabbit.jpg")
打开 purple_rabbit.jpg,你会发现除了颜色与背景,其余像素纹丝不动。
进阶玩法:拆解官方 6 大示例
官方 Showcase 给出了 6 组高频场景,下面逐一翻译成人话,并给出可直接粘贴的提示词(prompt)。
| 场景 | 输入图 | 推荐 prompt | 效果描述 |
|---|---|---|---|
| 1. 吉祥物姿势变换 | 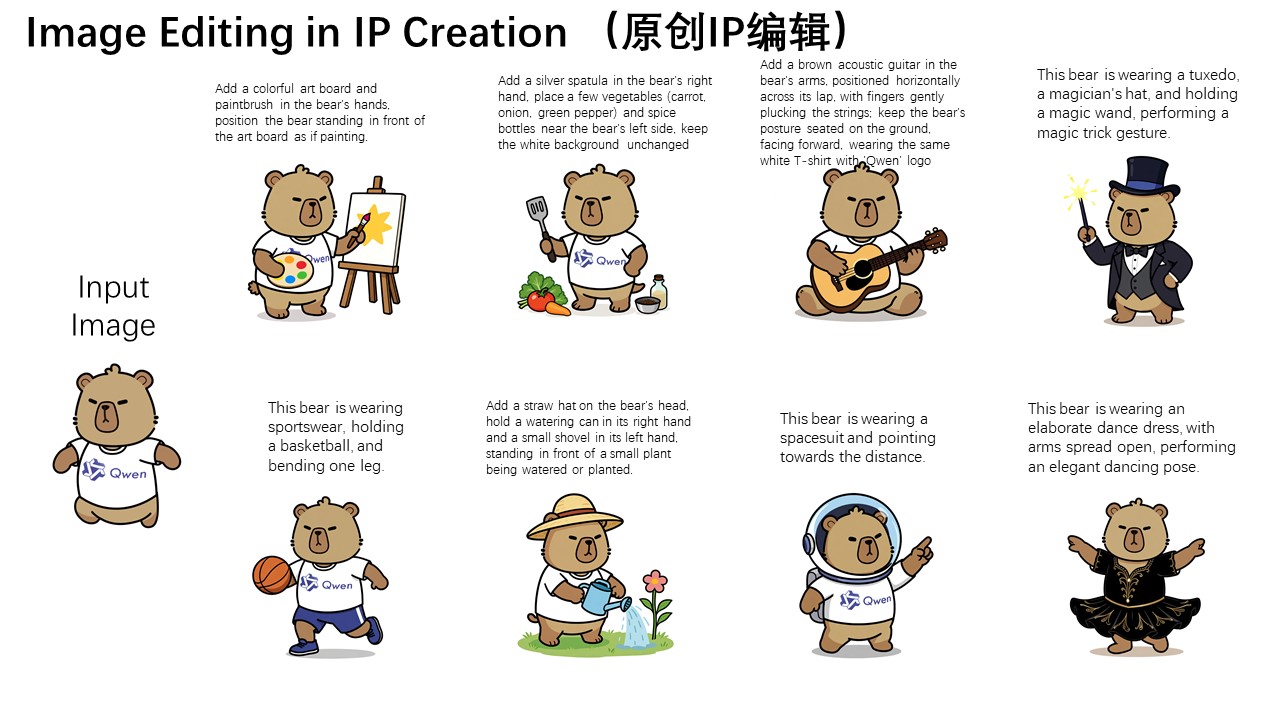 |
“让 capybara 做出沉思者动作,保持角色一致” | 像素整体变化,但一眼还是原角色 |
| 2. MBTI 表情包 | 同上 | “INTJ 版 capybara,冷峻蓝调” | 快速生成 16 张不同性格的同 IP 图 |
| 3. 90° / 180° 旋转 |  |
“把相机旋转 90°,露出侧面接口” | 直接看到物体背面 |
| 4. 吉卜力风格 |  |
“宫崎骏动画风,柔和色彩” | 人像秒变手绘 |
| 5. 加招牌 |  |
“在空白墙加一块咖啡店招牌,保留光影” | 招牌与倒影自动匹配 |
| 6. 文字精修 |  |
“把 ‘Hello’ 改为 ‘Hi’,字体不变” | 字形、大小、材质丝毫不差 |

FAQ:你可能想问的 10 个问题
-
Qwen-Image-Edit 和 Stable Diffusion 有什么区别?
Stable Diffusion 更擅长“从无到有”的生成,而 Qwen-Image-Edit 专注“从有到优”的编辑,尤其擅长保持原图元素不变。 -
显存要多少?
20B 模型,FP16 推理最低 12 GB 显存,BF16 更稳。 -
能商用吗?
Apache 2.0 许可证,可商用,但需遵守许可证义务(保留版权与许可证文本)。 -
支持中文提示词吗?
完全支持,中英文可混用。 -
只能改整张图吗?
支持局部框选(bbox),官方示例里用红蓝框校正书法就是典型案例。 -
怎么固定种子?
传generator=torch.manual_seed(任意整数),同种子可复现。 -
true_cfg_scale 设多少合适?
3–5 之间最稳,过低改动不足,过高易崩。 -
能批量处理吗?
用 for 循环逐张喂图即可,官方管道已做好内存管理。 -
没有 GPU 怎么办?
目前官方只放出 GPU 版本,CPU 推理时间无法接受。 -
会留水印吗?
不会,开源模型无强制水印。
如何像专家一样“链式修图”
官方书法示例透露了高级技巧:
逐字圈选 → 逐字校正 → 细节再校正。
步骤拆解如下:
| 步骤 | 动作 | prompt 示例 |
|---|---|---|
| 1 | 用红框圈出整字 “稽” | “把红框里的字改为正确的‘稽’” |
| 2 | 模型把右下写成“日”,再用小框圈出“日” | “把红框里的‘日’部件改为‘旨’” |
| 3 | 重复直到满意 | 无需重跑整图,局部多次迭代即可 |
这种方法把“大改”拆成“小改”,既省显存又提高成功率。
性能与基准:为什么说它是 SOTA
官方技术报告提到在 4 个公开数据集(未列出名称,仅报告指标)中,
-
结构保持分 ↑ 9 % -
文字准确率 ↑ 15 % -
用户偏好胜率 74 %
虽然数字看起来抽象,但翻译成用户语言就是:
多数情况下,肉眼可见比同类工具更稳、更准、更不易“翻车”。
快速查表:参数与默认值
| 参数 | 默认值 | 用途 |
|---|---|---|
| true_cfg_scale | 4.0 | 控制 prompt 遵守强度 |
| num_inference_steps | 50 | 步数越多越精细,30–50 平衡 |
| negative_prompt | ” “ | 负面提示,可填“低质量、模糊” |
| generator | None | 传随机种子可复现 |
写在最后:用 AI 把修图门槛降到 0
过去,设计师需要精通 Photoshop 的图层、蒙版、通道;
现在,只要会写一句话,Qwen-Image-Edit 就能帮你完成 80 % 的工作。
剩下的 20 % 创意,由你决定。
引用
若本文对你的项目有帮助,可按如下格式引用原作者技术报告:
@misc{wu2025qwenimagetechnicalreport,
title={Qwen-Image Technical Report},
author={Chenfei Wu and et al.},
year={2025},
eprint={2508.02324},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.02324},
}
祝你玩得开心,修图愉快!

