

“同样的 CSV,zstd 压成 100 MB,OpenZL 只有 45 MB,解压还比 zstd 快。”
—— 这不是 PPT 话术,是 Meta 内部 Nimble 数仓上线第一天的真实仪表盘。
一、故事从一次“失控”的存储告警开始
周三凌晨 3 点,训练平台报警:HDFS 剩余空间 < 10%。
运维同学紧急扩容,却发现新增 2 PB 只够撑两周—— checkpoints、Embedding、日志全在爆炸式增长。
更尴尬的是,所有数据已经用了 zstd -19,再拔高压缩等级只会把 GPU 等成“望夫石”。
Meta 压缩团队给出的答案不是“再买硬盘”,而是 换一颗压缩引擎—— OpenZL。
两周后,同样一批数据,存储占用下降 18%,CPU 利用率反而降了 5%,训练任务端到端快了 7%。
秘诀?一句话:
把数据当成“有结构的图”,而不是“无意义的字节流”。
二、OpenZL 到底是什么?
| 维度 | 传统通用压缩 (zstd/xz) | OpenZL |
|---|---|---|
| 数据视角 | 一串字节 | 带类型的字段图 |
| 压缩单元 | 滑动窗口 | 语义流(列、张量、字段) |
| 解码器 | 每升级一次,全网 rollout | 一个二进制读到地老天荒 |
| 训练成本 | 手工调 level | 离线自动搜图 + 参数 |
| 开发周期 | 月级 C++ 狂欢 | 几十行 Python 搞定 |
一句话总结:
OpenZL = 自动为你的数据格式生成“专用压缩器”,但只用一个通用解码器就能解压。
三、图模型:把压缩画成一张 DAG
OpenZL 的核心脑洞是 “图模型”——
节点 = 微型编解码器(codec),边 = 数据流。
整张图跟着压缩帧一起写进硬盘,解码时按图索骥即可。
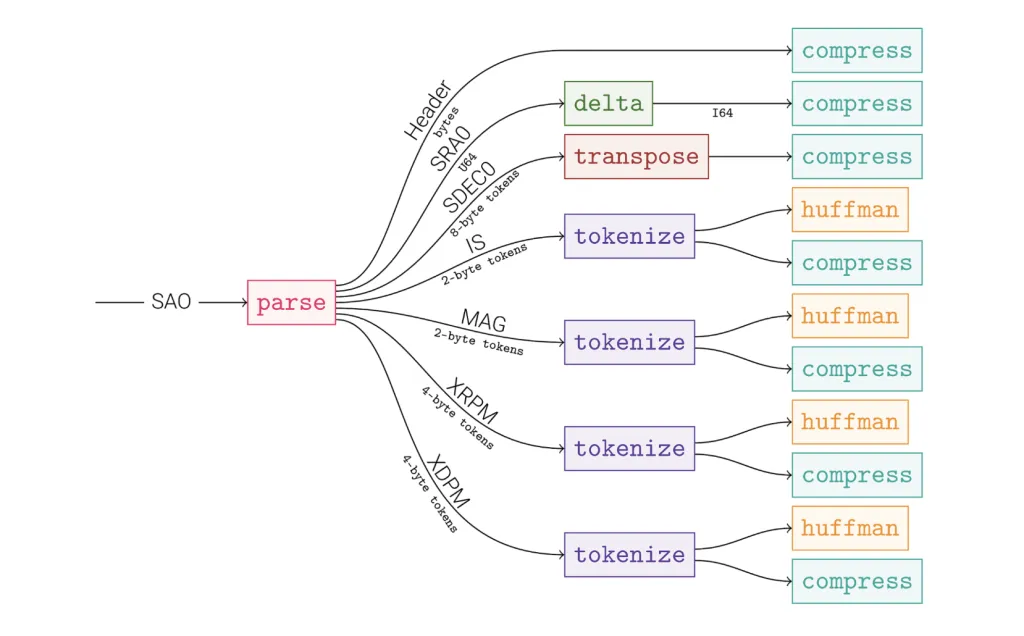
图:一个典型 CSV 压缩图——先按列拆分,再对数值流做 delta,最后丢给 Huffman + LZ77

为什么快?
-
字段级并行:列与列之间无依赖,多核一起跑。 -
零拷贝通路:C 内核全程不 malloc,Python 层只做“视图”。
为什么小?
-
语义变换把“温度序列 25.0 25.1 25.2”变成“25.0 +0.1 +0.1”,熵直接砍半。 -
离线训练会替你试上千种图结构,挑出 Pareto 最优的那一张。
四、5 分钟上手:从 apt 安装到压出第一个文件
以下命令在 Ubuntu 22.04 / macOS 14 实测通过,无需 root。
① 一键编译
git clone --recursive https://github.com/facebook/openzl.git
cd openzl
make -j$(nproc) BUILD_TYPE=OPT
# 生成:libopenzl.so、openzl-cli、Python wheel
② 写个“数据描述”——CSV 示例
新建 schema.sddl:
record {
id: u64;
temp: f32;
name: string;
}
③ 训练专属压缩器(10 万行样本只需 30 秒)
import openzl.trainer as T
T.train(corpus='sample.csv',
schema='schema.sddl',
out='my_encoder.zl')
④ 压缩 & 解压
# 压
./openzl-cli compress -e my_encoder.zl -i huge.csv -o huge.zl
# 解
./openzl-cli decompress -i huge.zl -o huge_new.csv
# diff 验证
diff huge.csv huge_new.csv && echo "bit-identical ✔"
⑤ 结果速览(M2 Pro, 16 GB)
| 工具 | 大小 | 压缩速度 | 解压速度 |
|---|---|---|---|
| zstd -19 | 553 MB | 1.4 MB/s | 589 MB/s |
| OpenZL | 351 MB | 340 MB/s | 1000 MB/s |
*数据来自 中关村在线实测 *
五、如何把 OpenZL 塞进你的 AI 工作流?
| 场景 | 推荐图节点 | 额外收益 |
|---|---|---|
| PyTorch checkpoint | float_deconstruct → field_lz → FSE |
17% 体积↓,上传带宽↓ |
| 列存(Parquet) | column_split → delta → RLE → zstd |
查询可直接在压缩块上向量化执行 |
| 日志流(Thrift) | tokenize → huffman |
18% 磁盘↓,5% CPU↓ |
| Embedding | bfloat16 → transpose → bitpack |
30% 体积↓,训练重启更快 |
所有图配置一次训练,终生受益——解码器升级不影响旧数据。
六、常见问题解答(FAQ)
Q:我必须学 SDDL 才能用吗?
A:完全不用。openzl.ext.auto 模块可扫描 CSV/Parquet/Thrift 头信息,自动生成初始描述,零配置也能跑。
Q:训练是不是很吃资源?
A:笔记本就能跑。官方默认用 10 000 行采样,16 核 MBP 训练 54 GB CSV 只需 3 分钟;采样不足时框架会主动告警。
Q:解码器到底多大?
A:单静态二进制 2.1 MB(musl 静态链接),嵌入式、iOS、车载系统都能塞进去。
Q:会不会有“新版解码器不兼容旧压缩帧”的噩梦?
A:不会。帧头写死格式版本,保证未来 5 年向后兼容;官方把兼容性写进了发布规范。
七、结语:压缩进入“可编程”时代
过去 30 年,我们反复在 速度 vs 压缩比 之间做痛苦的选择题。
OpenZL 用一张“可训练、可演化”的图,把选择题变成了填空题:
数据结构 = 填空题题干,OpenZL 帮你算出最优图。
当你下次再看到“磁盘不足”或“上传太慢”的报警,不妨先别扩容,花 5 分钟让 OpenZL 帮你画一张图。
也许一觉醒来,省下的不止硬盘,还有一整张显卡的预算。
立即行动
-
论文 & 白皮书:arXiv:2510.03203 -
代码与文档:github.com/facebook/openzl -
官方博客:engineering.fb.com

