

你是否曾经好奇过,机器人或增强现实系统是如何从简单的视频中理解 3D 世界的布局?这是一个复杂的问题,尤其是在视频拍摄时伴随着晃动摄像头或移动物体的情况下。NVIDIA 研究团队开发的 ViPE(视频姿势引擎)让这个过程变得更简单且更精确。本文将带你了解 ViPE 是什么、它为何对机器人和空间 AI 领域至关重要,以及它如何解决将 2D 视频转化为可用 3D 数据这一长期难题。
让我们从基础开始。想象一下,你正在开发一个需要理解真实空间的 AI 系统,比如自动驾驶汽车在街道上的导航或房间里拾取物体的机器人。这些系统依赖于精确的 3D 信息,但我们手头的大多数视频都是来自手机或摄像机的平面 2D 记录。ViPE 应运而生,它能自动从这些视频中提取关键的 3D 元素,包括摄像头校准细节、摄像头的移动路径以及显示真实距离的详细深度图。
为什么这令人兴奋?因为创建高质量的 3D 数据集过去需要昂贵的设备和大量时间。ViPE 改变了这一现状,它能处理日常视频,从而为训练高级 AI 模型构建大规模数据集。接下来,我会逐步讲解其工作原理,分享其核心功能,并回答你可能有的常见问题。
从视频中提取 3D 几何数据的难点在哪里?
在深入探讨 ViPE 之前,让我们先聊聊为什么这如此困难。我们生活在 3D 世界中,但视频将其记录为 2D。逆向推导原始 3D 结构需要推测摄像机的移动、镜头属性以及每个像素的深度。日常视频增加了额外的挑战:它们可能晃动、包含移动的人或车辆,并且来自未知的摄像头,如智能手机或行车记录仪。
传统的解决方案主要分为两大类,每种都有局限性:
- 🍂
经典方法如 SLAM 和 SfM:这些方法通过数学手段追踪帧间的特征并优化以获得准确性。在受控环境中表现良好,但遇到移动物体或未知摄像头设置时容易失效。例如,如果视频包含繁忙街道的动态场景,由于假设一切是静态的,整个重建可能失败。
- 🍂
深度学习模型:这些模型通过从海量数据中学习来处理噪声和变化,表现出色,但计算需求极大。处理长视频可能需要将其分割成短片段,失去整体一致性,或者处理速度过慢,难以用于大规模应用。
这就留下了一个空白:我们需要既准确又能应对现实世界复杂性、同时高效处理数千个视频的工具。ViPE 通过融合优化方法的精确性与学习模型的智能性填补了这一空白。
ViPE 的工作原理:逐步解析
ViPE 设计为一个处理视频的流水线,按帧构建 3D 理解。它基于关键帧方法,专注于重要帧以保持效率,类似于某些导航系统的工作方式,但升级为更通用的版本。
以下是其流程的高层概述:
-
输入准备:从任意原始视频开始。ViPE 支持标准透视摄像头、广角镜头、鱼眼镜头,甚至 360° 全景视频。
-
动态物体屏蔽:首先使用 GroundingDINO 和 Segment Anything (SAM) 等工具识别并屏蔽移动物体,如人和车辆,确保计算聚焦于静态背景。
-
关键帧选择:并非每个帧都完全处理。ViPE 根据运动选择关键帧——如果摄像头相对于上一个关键帧移动足够远,则添加新关键帧。运动通过密集光流(追踪像素移动)和稀疏跟踪(关键点)计算得出。
-
捆绑调整优化:这是核心部分。ViPE 构建一个图,其中帧为节点,节点间连接使用来自光流、跟踪和深度先验的约束。它优化摄像头姿势、内部参数(例如焦距)和稀疏 3D 地图。
-
深度对齐:最后,细化每帧的深度图,使其细节丰富、随时间一致,并以公尺为单位。
结果是:每段视频输出包括:
- 🍂
摄像头内部参数(校准参数)。 - 🍂
精确的摄像头姿势(随时间变化的位置和方向)。 - 🍂
密集深度图(以真实距离为单位)。

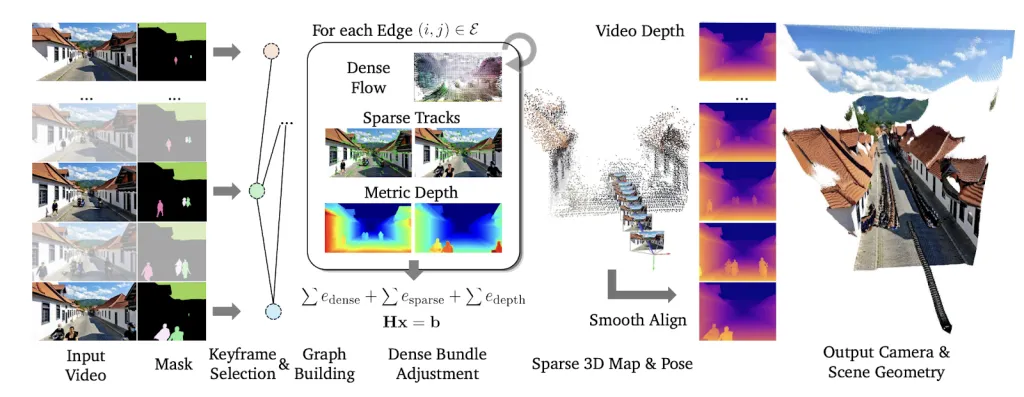
此图展示了关键组件:密集光流提供鲁棒性,稀疏跟踪提供精确性,公尺深度提供尺度。
ViPE 的核心创新
ViPE 不仅仅是简单混合,它是精心整合的。以下是其主要突破:
- 🍂
平衡约束:ViPE 在优化中使用三种输入:
- 🍂
密集光流来自学习网络,处理低光或运动模糊等恶劣条件。 - 🍂
稀疏特征跟踪用于精细细节,提高定位精度。 - 🍂
公尺深度先验来自单目模型,确保结果以真实尺度表示,而非相对。
- 🍂
- 🍂
处理动态性:通过高级分割屏蔽移动物体,ViPE 避免动态场景的错误。这对自拍或驾驶视频至关重要。
- 🍂
效率与通用性:在单 GPU 上运行 3-5 帧每秒,适用于标准分辨率(例如 640×480)。它支持多种摄像头,无需手动调整——自动优化内部参数。
- 🍂
高质量深度图:后处理通过与优化几何对齐的高分辨率深度估计,生成稳定、准确的深度图,即使在复杂场景中。


看看 ViPE 在棘手环境中生成令人惊叹的深度。
性能表现:ViPE 与其他工具的对比
ViPE 在 TUM(室内动态)和 KITTI(室外驾驶)等基准测试中表现优异,分别比未校准姿势估计基准高出 18% 和 50%。重要的是,它提供一致的公尺尺度,而其他方法往往给出不可用的变尺度结果。
在实际应用中,这意味着更好的表现。例如,在室内视频中有人移动时,ViPE 通过忽略动态性保持准确性。在室外驾驶中,它处理宽基线和未知摄像头。
ViPE 创建的数据集
ViPE 最大的影响之一是支持创建大规模数据集。研究人员使用它标注了:
- 🍂
Dynpose-100K++:约 10 万个现实世界的互联网视频(1570 万帧),包含姿势和几何数据,这些是具有挑战性的野外剪辑。 - 🍂
Wild-SDG-1M:100 万个 AI 生成视频(7800 万帧),来自扩散模型,质量高且多样。 - 🍂
Web360:2000 个全景视频,专为特定用途设计。
总计:约 9600 万帧。这些数据集可在 Hugging Face 上获取,供任何人用于训练 3D 模型,如 AI 世界生成。
如何开始使用 ViPE
准备好尝试了吗?ViPE 是开源的,你可以自行安装和运行。以下是基于可用代码的分步指南。
前提条件
- 🍂
配备 NVIDIA GPU 的机器(以提高效率)。 - 🍂
带有 PyTorch 等库的 Python 环境。
安装步骤
-
克隆仓库:
git clone https://github.com/nv-tlabs/vipe cd vipe -
安装依赖项:使用提供的 requirements 文件。
pip install -r requirements.txt -
下载预训练模型:按照仓库说明下载光流网络、深度估计器等权重。
在视频上运行 ViPE
-
准备视频文件(例如 input.mp4)。
-
运行主脚本:
python run_vipe.py --video_path input.mp4 --output_dir results --camera_model pinhole- 🍂
选项:使用 --camera_model fisheye适用于广角,或--panorama适用于 360°。
- 🍂
-
检查输出:你将在输出目录中找到姿势文件、内部参数和深度图。
此设置以 3-5 帧每秒处理,适合批量视频。
关于 ViPE 的常见问题
以下回答你可能有的问题,基于人们常问这类工具的问题。
ViPE 从视频中输出什么?
ViPE 接受原始视频,生成三项主要内容:摄像头内部参数(如焦距和畸变)、摄像头运动(随时间变化的姿势)和密集深度图(以公尺为单位的像素距离)。这些以文件形式保存,方便其他 AI 管道使用。
ViPE 与 COLMAP 或 ORB-SLAM 有何不同?
与 COLMAP 不同,COLMAP 处理图像集并假设已知内部参数,而 ViPE 按顺序处理视频并从头估计一切。相比 ORB-SLAM,它因整合学习组件而对动态和未知摄像头更具鲁棒性。
ViPE 能处理有移动物体的视频吗?
是的,这是其关键优势。它使用分割屏蔽移动物体(如汽车或人),优化聚焦静态部分。这使其适合现实世界视频,而经典方法则脆弱。
ViPE 的速度足够处理大规模数据集吗?
当然。以 3-5 帧每秒的单 GPU 速度,它标注了 9600 万帧的多样视频。相比之下,纯深度模型可能因内存问题处理长序列时崩溃。
ViPE 支持哪些摄像头类型?
它支持针孔(标准)、广角/鱼眼和 360° 全景。自动优化内部参数,无需手动校准。
深度图的准确性如何?
它们是公尺尺度和高质量的,帧间平滑对齐。基准测试显示姿势估计在 KITTI 上提升 50%。
我在哪里可以下载这些数据集?
它们在 Hugging Face 上:
- 🍂
Dynpose-100K++: https://huggingface.co/datasets/nvidia/vipe-dynpose-100kpp - 🍂
Wild-SDG-1M: https://huggingface.co/datasets/nvidia/vipe-wild-sdg-1m - 🍂
Web360: https://huggingface.co/datasets/nvidia/vipe-web360
ViPE 的设置复杂吗?
不算太复杂。GitHub 仓库有清晰说明。如果熟悉 Python 和 AI 工具,很快就能上手。
ViPE 对空间 AI 的重要性
想想更大的图景。空间 AI——理解并与 3D 空间交互的系统——需要大量数据来学习。ViPE 通过大规模标注视频使数据触手可及。对于机器人,这意味着更好的导航策略训练。在 AR/VR 中,它支持更真实的重建。即使在视频生成中,ViPE 的姿势能指导模型创建一致的 3D 内容。
作为处理 3D 数据的人,脆弱工具的挫败感我深有体会。ViPE 像一股清流——实用、强大且开放给所有人改进。
深入技术细节:好奇者的探索
如果你喜欢技术细节,让我们分解其方法论。
ViPE 中的捆绑调整
这是优化的核心。ViPE 将问题建模为图:
- 🍂
节点:关键帧,包含姿势和内部参数。 - 🍂
边:成对间的约束。
损失函数平衡:
- 🍂
密集光流的重新投影误差。 - 🍂
稀疏跟踪一致性。 - 🍂
深度正则化以强制公尺尺度。
它通过迭代优化快速收敛,感谢学习模型的良好初始值。
深度对齐过程
优化后,深度可能一致但细节不足。ViPE 使用平滑变换将高分辨率视频深度估计(来自管道中的模型)与优化结果对齐。这保持时间稳定性同时增加细节。
表:ViPE 中的约束比较
| 约束类型 | 目的 | 来源 |
|---|---|---|
| 密集光流 | 恶劣条件下鲁棒对应 | 学习的光流网络 |
| 稀疏跟踪 | 高精度定位 | 传统特征跟踪 |
| 公尺深度 | 真实世界尺度 | 单目深度先验 |
此表展示了 ViPE 如何协同元素获得更好结果。


从随意输入到详细 3D 输出。
潜在应用场景
- 🍂
训练 3D 模型:使用数据集进行多视图立体或新视图合成。 - 🍂
机器人模拟:标注视频创建真实训练环境。 - 🍂
AR 应用:提取姿势无缝叠加虚拟对象。 - 🍂
视频分析:理解监控或体育视频中的轨迹。
总结:ViPE 的未来
ViPE 不仅仅是工具,它是扩展 3D 感知的大门。通过解决标注瓶颈,它为更高级的空间智能铺平道路。如果你从事 AI、机器人或计算机视觉,不妨试试——代码和数据随时待你探索。
有更多问题?在评论区提出,我会根据本文内容回答。

