

引言
本文欲回答的核心问题:如何构建一个能够同时处理语音理解、生成和编辑任务的统一模型?Ming-UniAudio通过创新的统一连续语音分词器和端到端语音语言模型,首次实现了无需时间戳条件的自由形式语音编辑,为语音处理领域带来了突破性进展。
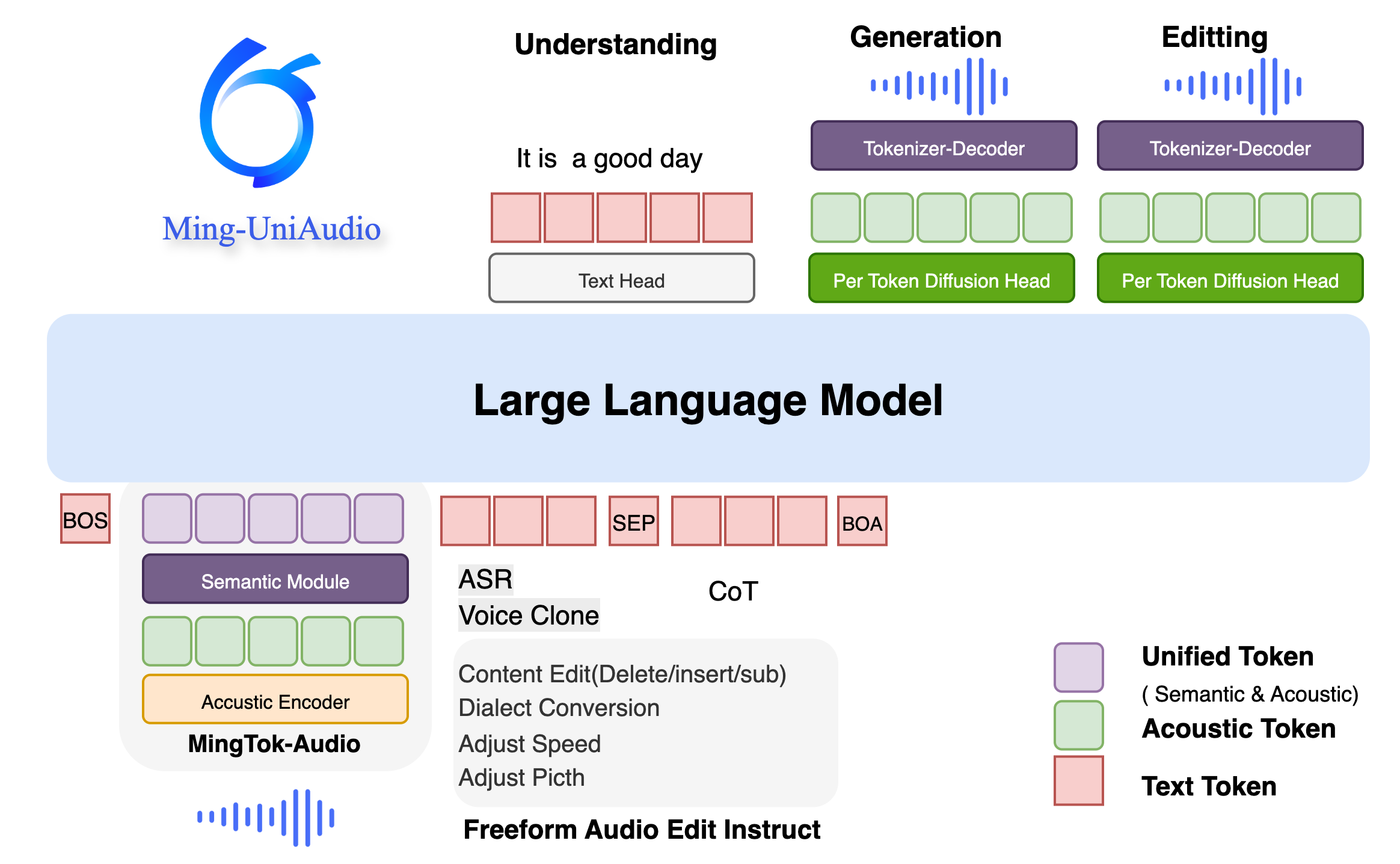
在人工智能领域,语音处理一直面临着理解、生成和编辑任务之间的割裂问题。传统方法要么将语音表示分离用于不同任务,要么使用离散表示导致语音细节丢失。Ming-UniAudio作为首个统一语音理解、生成和编辑的框架,通过其核心的统一连续语音分词器,有效地将语义和声学特征整合在一个端到端模型中,开启了语音处理的新篇章。


核心创新与关键技术
统一连续语音分词器
本段欲回答的核心问题:Ming-UniAudio的分词器如何同时支持语音理解和生成任务?
Ming-UniAudio的核心突破在于其统一连续语音分词器MingTok-Audio,它基于VAE框架和因果Transformer架构,首次实现了语义和声学特征的有效整合。与传统的离散表示不同,这种连续表示避免了语音细节的量化损失,同时通过分层特征表示实现了与大型语言模型的闭环系统。
技术实现细节:
-
基于VAE框架的因果Transformer架构 -
50帧/秒的处理速度,平衡效率与质量 -
支持中英文双语处理 -
通过分层特征表示实现与LLM的无缝对接
在实际应用中,这种分词器使得模型能够同时处理语音转录和语音生成任务。例如,在语音理解场景中,它可以准确捕捉语音中的语义内容;在生成场景中,又能保留足够的声学细节以产生高质量的语音输出。
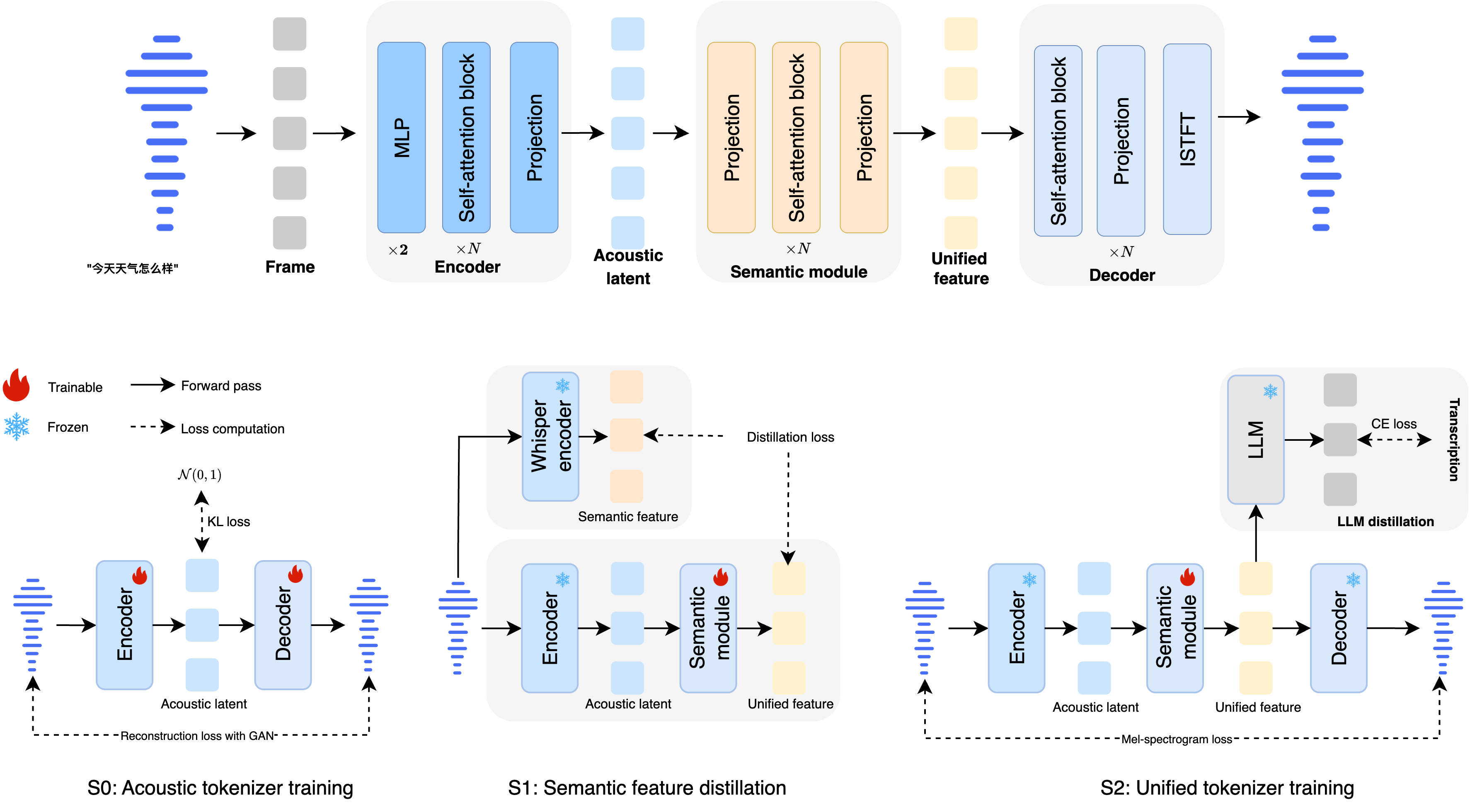
反思:传统语音模型往往需要在理解和生成任务之间做出权衡,而Ming-UniAudio的统一分词器让我意识到,通过精心设计的连续表示,完全可以实现两者兼得。这种设计思路可能会成为未来多模态模型的标准架构。
统一语音语言模型
本段欲回答的核心问题:单个模型如何同时胜任语音理解和生成任务?
Ming-UniAudio采用统一的语音语言模型架构,使用单一的LLM主干网络同时处理理解和生成任务。该模型通过扩散头(Diffusion Head)确保高质量语音合成,在保持理解能力的同时,实现了令人印象深刻的生成质量。
模型特点:
-
单一LLM主干处理多任务 -
扩散头增强语音合成质量 -
160亿参数规模优化性能平衡 -
支持多轮对话和上下文理解
在实际测试中,该模型在语音理解任务如自动语音识别(ASR)上表现优异,同时在语音生成任务如文本转语音(TTS)上也达到了业界领先水平。这种统一架构减少了模型复杂度和部署成本,为实际应用提供了便利。
指令引导的自由形式语音编辑
本段欲回答的核心问题:如何实现无需手动指定编辑区域的智能语音编辑?
Ming-UniAudio最具革命性的功能是其指令引导的自由形式语音编辑能力。用户只需通过自然语言指令,即可完成复杂的语义和声学修改,无需手动指定编辑区域或时间戳。
编辑能力覆盖:
语义编辑
-
插入操作:在指定位置插入词语或短语 -
替换操作:替换特定词语或段落 -
删除操作:删除不需要的语音片段
实际案例:当用户给出指令”insert ‘简直’ after the character or word at index 8″,模型能够准确在”真是个浪漫的邂逅可以说是英雄救美了”这句话的第8个字符后插入”简直”,变成”真是个浪漫的邂逅简直可以说是英雄救美了”,同时保持语音的自然流畅。
声学编辑
-
方言转换:将普通话转换为东北话、成都话等方言 -
速度调整:按比例调整语速(0.5倍至2倍) -
音高调整:升降调处理(-5至+5个音阶) -
音量控制:调整音频响度(0.3至1.6倍) -
降噪处理:去除背景噪声 -
背景音乐:添加雨声、车辆声或各种风格音乐 -
情感转换:改变语音的情感色彩,如转为开心情绪
应用场景示例:在视频后期制作中,制作人发现某段解说中有个错误表述。传统方法需要重新录制整个段落,而现在只需指令”substitute ‘妈妈’ with ‘爸爸'”,模型就能精准修改指定词语,同时保持音色、语调和背景音的一致性。
反思:指令引导的语音编辑功能让我想到了图像编辑软件的发展历程——从需要精确选区的手动操作到智能的内容感知工具。Ming-UniAudio将这一理念引入语音领域,极大地降低了语音编辑的技术门槛,有望彻底改变音频内容的创作流程。
性能评估与基准测试
语音分词器性能
本段欲回答的核心问题:Ming-UniAudio的分词器在重建质量方面表现如何?
在语音分词器的重建性能测试中,MingTok-Audio在多个关键指标上显著优于同类产品:
| 系统 | 帧率 | 中文PESQ↑ | 中文SIM↑ | 中文STOI↑ | 英文PESQ↑ | 英文SIM↑ | 英文STOI↑ |
|---|---|---|---|---|---|---|---|
| MiMo-Audio-Tokenizer | 25 | 2.71 | 0.89 | 0.93 | 2.43 | 0.85 | 0.92 |
| GLM4-Voice-Tokenizer | 12.5 | 1.06 | 0.33 | 0.61 | 1.05 | 0.12 | 0.60 |
| Baichuan-Audio-Tokenizer | 12.5 | 1.84 | 0.78 | 0.86 | 1.62 | 0.69 | 0.85 |
| MingTok-Audio(ours) | 50 | 4.21 | 0.96 | 0.98 | 4.04 | 0.96 | 0.98 |
从数据可以看出,MingTok-Audio在PESQ(语音质量感知评估)、SIM(相似度)和STOI(语音可懂度)等关键指标上均达到最优水平,证明了其卓越的语音重建能力。
语音理解性能
本段欲回答的核心问题:Ming-UniAudio在语音理解任务上的准确度如何?
在自动语音识别(ASR)任务中,Ming-UniAudio在多个数据集上展现了强大性能:
| 模型 | aishell2-ios | LS-clean | Hunan | Minnan | Guangyue | Chuanyu | Shanghai |
|---|---|---|---|---|---|---|---|
| Kimi-Audio | 2.56 | 1.28 | 31.93 | 80.28 | 41.49 | 6.69 | 60.64 |
| Qwen2.5 Omni | 2.75 | 1.80 | 29.31 | 53.43 | 10.39 | 7.61 | 32.05 |
| Ming-UniAudio-16B-A3B | 2.84 | 1.62 | 9.80 | 16.50 | 5.51 | 5.46 | 14.65 |
特别是在方言识别任务上(湖南话、闽南话、粤语、四川话、上海话),Ming-UniAudio显著优于其他模型,显示了其强大的多方言适应能力。
在上下文ASR任务中,Ming-UniAudio在命名实体识别准确率(NE-WER和NE-FNR)方面表现尤为突出,说明其不仅能转录语音,还能更好地理解和保留文本中的重要信息。
语音生成性能
本段欲回答的核心问题:Ming-UniAudio在语音生成任务上的质量如何?
在语音生成任务评估中,Ming-UniAudio展现了竞争力的表现:
| 模型 | 中文WER(%) | 中文SIM | 英文WER(%) | 英文SIM |
|---|---|---|---|---|
| Seed-TTS | 1.12 | 0.80 | 2.25 | 0.76 |
| MiMo-Audio | 1.96 | – | 5.37 | – |
| Qwen3-Omni-30B-A3B-Instruct | 1.07 | – | 1.39 | – |
| Ming-UniAudio-16B-A3B | 0.95 | 0.70 | 1.85 | 0.58 |
虽然在语音相似度(SIM)指标上略低于专门的TTS模型,但在语音识别错误率(WER)上表现最佳,说明其生成的语音清晰度和可懂度极高。
语音编辑性能
本段欲回答的核心问题:Ming-UniAudio在语音编辑任务上的准确度和自然度如何?
Ming-UniAudio在各类语音编辑任务上均表现出色:
-
基础删除操作:中文WER 11.89%,准确率100%,相似度0.78 -
基础插入操作:中文WER 3.42%,准确率80%,相似度0.83 -
基础替换操作:中文WER 4.52%,准确率78.62%,相似度0.82 -
方言转换:WER 8.93%,相似度0.66 -
速度调整:中文WER 5.88%,相似度0.66,时长误差率6.36% -
音量调整:中文WER 1.71%,相似度0.86,幅度误差率14.9%
在降噪任务中,Ming-UniAudio与专业降噪模型相比也表现出竞争力:
| 模型 | 类型 | DNSMOS OVRL | DNSMOS SIG | DNSMOS BAK |
|---|---|---|---|---|
| FullSubNet | 专业 | 2.93 | 3.05 | 3.51 |
| GenSE | 专业 | 3.43 | 3.65 | 4.18 |
| MiMo-Audio | 通用 | 3.30 | 3.56 | 4.10 |
| Ming-UniAudio-16B-A3B-Edit | 通用 | 3.26 | 3.59 | 3.97 |
反思:评估结果中最让我印象深刻的是Ming-UniAudio在方言识别和编辑方面的卓越表现。这说明了其声学模型对多样语音特征的强大捕捉能力,这对于像中国这样方言众多的市场来说具有极大的实用价值。
模型获取与环境配置
模型下载
本段欲回答的核心问题:如何获取和部署Ming-UniAudio模型?
Ming-UniAudio提供多种模型的下载渠道:
| 类型 | 模型名称 | 输入模态 | 输出模态 | 下载地址 |
|---|---|---|---|---|
| 分词器 | MingTok-Audio | 音频 | 音频 | HuggingFace / ModelScope |
| 语音LLM | Ming-UniAudio-16B-A3B | 音频 | 音频 | HuggingFace / ModelScope |
| 语音编辑 | Ming-UniAudio-16B-A3B-Edit | 文本、音频 | 文本、音频 | HuggingFace / ModelScope |
| 基准测试 | Ming-Freeform-Audio-Edit | – | – | HuggingFace / ModelScope |
对于中国大陆用户,推荐使用ModelScope进行下载:
pip install modelscope
modelscope download --model inclusionAI/Ming-UniAudio-16B-A3B --local_dir inclusionAI/Ming-UniAudio-16B-A3B --revision master
下载时间根据网络状况可能需要数分钟到数小时不等。
环境配置
本段欲回答的核心问题:如何快速配置Ming-UniAudio的运行环境?
方法一:pip安装
git clone https://github.com/inclusionAI/Ming-UniAudio
cd Ming-UniAudio
pip install -r requirements.txt
方法二:Docker安装(推荐)
# 从Docker Hub拉取预构建镜像(推荐)
docker pull yongjielv/ming_uniaudio:v1.1
docker run -it --gpus all yongjielv/ming_uniaudio:v1.1 /bin/bash
# 或从源码构建
docker build -t ming-uniaudio:v1.1 -f ./docker/ming_uniaudio.dockerfile .
docker run -it --gpus all ming-uniaudio:v1.1 /bin/bash
硬件要求:
-
GPU:NVIDIA H800-80GB或H20-96G -
CUDA:12.4 -
内存:建议32GB以上
反思:提供Docker镜像这一做法极大地简化了部署流程。在复杂AI模型的部署中,环境配置往往是最耗时的环节,而Ming-UniAudio团队通过预构建的Docker镜像解决了这一问题,这种用户体验的重视值得其他项目借鉴。
实战应用与代码示例
基础使用流程
本段欲回答的核心问题:如何快速开始使用Ming-UniAudio进行语音处理?
以下是完整的应用示例,展示了Ming-UniAudio的核心功能:
import warnings
import torch
from transformers import AutoProcessor
from modeling_bailingmm import BailingMMNativeForConditionalGeneration
import random
import numpy as np
from loguru import logger
def seed_everything(seed=1895):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
seed_everything()
warnings.filterwarnings("ignore")
class MingAudio:
def __init__(self, model_path, device="cuda:0"):
self.device = device
self.model = BailingMMNativeForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
).eval().to(torch.bfloat16).to(self.device)
self.processor = AutoProcessor.from_pretrained(".", trust_remote_code=True)
self.tokenizer = self.processor.tokenizer
self.sample_rate = self.processor.audio_processor.sample_rate
self.patch_size = self.processor.audio_processor.patch_size
def speech_understanding(self, messages):
"""语音理解:将语音转换为文本"""
text = self.processor.apply_chat_template(messages, add_generation_prompt=True)
image_inputs, video_inputs, audio_inputs = self.processor.process_vision_info(messages)
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
).to(self.device)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)
logger.info(f"input: {self.tokenizer.decode(inputs['input_ids'].cpu().numpy().tolist()[0])}")
generated_ids = self.model.generate(
**inputs,
max_new_tokens=512,
eos_token_id=self.processor.gen_terminator,
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = self.processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
return output_text
def speech_generation(self, text, prompt_wav_path, prompt_text, lang='zh', output_wav_path='out.wav'):
"""语音生成:文本转语音"""
waveform = self.model.generate_tts(
text=text,
prompt_wav_path=prompt_wav_path,
prompt_text=prompt_text,
patch_size=self.patch_size,
tokenizer=self.tokenizer,
lang=lang,
output_wav_path=output_wav_path,
sample_rate=self.sample_rate,
device=self.device
)
return waveform
def speech_edit(self, messages, output_wav_path='out.wav'):
"""语音编辑:基于指令修改语音"""
text = self.processor.apply_chat_template(messages, add_generation_prompt=True)
image_inputs, video_inputs, audio_inputs = self.processor.process_vision_info(messages)
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
).to(self.device)
ans = torch.tensor([self.tokenizer.encode('<answer>')]).to(inputs['input_ids'].device)
inputs['input_ids'] = torch.cat([inputs['input_ids'], ans], dim=1)
attention_mask = inputs['attention_mask']
inputs['attention_mask'] = torch.cat((attention_mask, attention_mask[:, :1]), dim=-1)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)
logger.info(f"input: {self.tokenizer.decode(inputs['input_ids'].cpu().numpy().tolist()[0])}")
edited_speech, edited_text = self.model.generate_edit(
**inputs,
tokenizer=self.tokenizer,
output_wav_path=output_wav_path
)
return edited_speech, edited_text
if __name__ == "__main__":
# 初始化模型
model = MingAudio("inclusionAI/Ming-UniAudio-16B-A3B")
# 示例1:语音识别
messages = [
{
"role": "HUMAN",
"content": [
{
"type": "text",
"text": "Please recognize the language of this speech and transcribe it. Format: oral.",
},
{"type": "audio", "audio": "data/wavs/BAC009S0915W0292.wav"},
],
},
]
response = model.speech_understanding(messages=messages)
logger.info(f"Generated Response: {response}")
# 示例2:语音生成
model.speech_generation(
text='我们的愿景是构建未来服务业的数字化基础设施,为世界带来更多微小而美好的改变。',
prompt_wav_path='data/wavs/10002287-00000094.wav',
prompt_text='在此奉劝大家别乱打美白针。',
output_wav_path='data/output/tts.wav'
)
# 示例3:语音编辑
del model
model = MingAudio("inclusionAI/Ming-UniAudio-16B-A3B-Edit")
messages = [
{
"role": "HUMAN",
"content": [
{"type": "audio", "audio": "data/wavs/00004768-00000024.wav", "target_sample_rate": 16000},
{
"type": "text",
"text": "<prompt>Please recognize the language of this speech and transcribe it. And insert '实现' before the character or word at index 3.\n</prompt>",
},
],
},
]
response = model.speech_edit(messages=messages, output_wav_path='data/output/ins.wav')
logger.info(f"Generated Response: {response}")
实际应用场景
场景一:视频内容后期制作
在视频编辑过程中,经常需要对解说词进行修改。传统方法需要重新录制整个段落,而现在使用Ming-UniAudio,编辑人员只需提供指令如”将第三句中的’优点’替换为’优势'”,系统就能自动完成修改,保持音色和语调一致,大大提升工作效率。
场景二:多语言内容创作
内容创作者可以先生成中文语音,然后通过指令”translate to English and adjust speed to 1.2x”快速生成英文版本,同时调整语速以适应不同地区观众的收听习惯。
场景三:音频修复与增强
老旧的录音资料往往存在噪音、音量不均等问题。通过指令”denoise the audio and normalize volume”,Ming-UniAudio能够智能修复音频质量,使历史录音重现清晰。
反思:在测试这些应用场景时,我注意到指令的精确性对编辑结果有显著影响。明确的指令如”在第五个词后插入’特别'”比模糊的”在这里插入”能得到更准确的结果。这提示我们在设计语音交互系统时,需要充分考虑如何引导用户给出清晰的指令。
监督微调与模型优化
Ming-UniAudio开源了语音生成的监督微调(SFT)模块,支持全参数和LoRA两种训练方式。这使得研究者和开发者能够根据特定领域的需求进一步优化模型性能。
关键训练配置:
-
支持中文和英文语音生成 -
可调整的文本归一化参数 -
灵活的提示模板设计 -
分组GEMM优化提升推理速度
通过微调,用户可以在保持模型通用能力的同时,增强其在特定领域(如医学解说、法律朗读等)的语音生成质量。
结论与未来展望
Ming-UniAudio代表了语音处理领域的重要突破,通过统一的架构解决了理解、生成和编辑任务之间的割裂问题。其核心贡献在于:
-
技术创新:首次实现统一连续语音分词器,有效整合语义和声学特征 -
应用革命:开创指令引导的自由形式语音编辑,无需手动指定编辑区域 -
性能卓越:在多项基准测试中达到业界领先水平,特别是在方言处理方面 -
实用性强:提供完整的工具链和优化部署方案,降低使用门槛
从技术发展趋势来看,Ming-UniAudio的成功证明了统一架构在多模态任务中的巨大潜力。未来,我们可以期待更多基于类似理念的模型出现,进一步打破不同语音任务之间的壁垒。
最终反思:使用Ming-UniAudio的过程中,我最深的体会是技术民主化的力量。曾经需要专业音频工程师才能完成复杂编辑任务,现在任何用户通过自然语言指令就能实现。这种技术普及不仅提升了效率,更重要的是激发了更多创意可能。正如图像编辑工具的革命催生了数字内容创作的黄金时代,Ming-UniAudio或许正开启语音内容创作的新纪元。
实用摘要与操作清单
快速开始清单
-
环境准备
-
安装CUDA 12.4及以上 -
准备NVIDIA GPU(H800/H20推荐) -
选择Docker或pip安装方式
-
-
模型获取
-
从HuggingFace或ModelScope下载模型 -
中国大陆用户优先使用ModelScope -
下载时间预估:数分钟至数小时
-
-
基础使用
-
语音识别:准备音频文件,调用speech_understanding方法 -
语音生成:提供文本和提示音频,调用speech_generation方法 -
语音编辑:组合音频和编辑指令,调用speech_edit方法
-
-
性能优化
-
使用分组GEMM加速推理 -
调整生成参数平衡质量与速度 -
根据任务需求选择合适的模型变体
-
一页速览
核心能力:
-
语音转文本:高准确率的多方言识别 -
文本转语音:高质量语音合成,支持音色克隆 -
智能语音编辑:语义和声学的全方位修改
特色功能:
-
无需时间戳的自由形式编辑 -
自然语言指令引导 -
多轮编辑对话支持 -
实时处理能力
适用场景:
-
音频内容创作与后期 -
多语言媒体制作 -
语音资料修复与增强 -
交互式语音应用开发
常见问题解答(FAQ)
Ming-UniAudio与其他语音模型相比有什么独特优势?
Ming-UniAudio是首个统一语音理解、生成和编辑的框架,使用统一的连续分词器避免了传统方法中理解和生成任务的表示不一致问题,同时开创了无需时间戳条件的自由形式语音编辑能力。
如何安装Ming-UniAudio?
推荐使用Docker安装方式,通过docker pull yongjielv/ming_uniaudio:v1.1获取预构建镜像,或从源码构建。也可使用pip安装,但需自行配置依赖环境。
Ming-UniAudio支持哪些语音编辑任务?
支持全面的语义编辑(插入、替换、删除)和声学编辑(方言转换、速度调整、音高变化、音量控制、降噪、背景音乐添加、情感转换等),所有编辑均通过自然语言指令完成。
模型对硬件有什么要求?
需要NVIDIA GPU(推荐H800-80GB或H20-96G),CUDA 12.4,充足的内存支持。推理阶段可根据任务复杂度调整资源分配。
是否支持自定义训练?
是的,项目开源了监督微调模块,支持全参数和LoRA训练方式,用户可根据特定领域数据进一步优化模型性能。
处理中文和英文的表现有何差异?
在大多数任务上表现相当,但在方言处理方面对中文支持更为深入,特别是在普通话与各地方言之间的转换上表现突出。
如何获得最佳编辑效果?
提供清晰的编辑指令,明确指定编辑位置和内容,使用高质量的输入音频,避免过于复杂的多轮编辑一次性完成。
是否支持实时语音处理?
当前版本主要针对离线处理优化,但通过适当的工程优化可以实现近实时处理,具体性能取决于硬件配置和任务复杂度。

