Meta的生成式广告模型GEM:重新定义广告推荐AI的核心引擎
在当今数字广告领域,人工智能正以前所未有的速度推动着个性化推荐的发展。作为这一变革的核心驱动力,Meta的生成式广告推荐模型(GEM)正在彻底改变我们理解用户偏好和优化广告效果的方式。这个被称为“广告推荐系统中央大脑”的模型,不仅显著提升了广告转化率,还重新定义了大规模AI模型在商业应用中的可能性。
什么是GEM?揭秘Meta的广告推荐核心引擎
Generative Ads Recommendation Model(GEM)是Meta基于大语言模型范式构建的最先进广告基础模型,也是行业内推荐系统领域规模最大的基础模型。与传统广告推荐系统不同,GEM采用了一种全新的架构思路,能够同时处理海量用户行为数据和广告内容特征,从而生成更精准的预测结果。
GEM的核心价值在于它解决了广告推荐系统中的几个根本性挑战。每天,Meta平台上发生数十亿次的用户与广告互动,但真正有意义的信号——如点击和转化——却非常稀疏。GEM必须从这些海量但不平衡的数据中识别出有效模式,并泛化到各种不同的用户和行为类型。
该模型已经产生了实实在在的业务影响。数据显示,在Instagram上,GEM推动了广告转化率提升5%,在Facebook信息流中则提升了3%。更令人印象深刻的是,在第三季度对模型架构的改进使GEM从给定数据和计算资源中获得的性能收益翻了一番。
GEM的三大创新支柱:架构、知识转移与训练基础设施
GEM的突破性表现在三个关键领域的创新,这些创新共同构成了它超越传统推荐系统的基础。
可扩展的模型架构
GEM的架构设计允许模型参数数量不断增加的同时,持续生成更精确的预测。与最初的广告推荐排名模型相比,GEM在利用相同数据和计算资源时,驱动广告性能增益的效率提高了4倍。
这种效率提升源于GEM对两类特征的独特处理方式:
-
序列特征:如用户的活动历史记录 -
非序列特征:如用户属性(年龄、位置)和广告属性(广告格式、创意表现)
GEM为每种特征类型应用定制化的注意力机制,同时支持跨特征学习,这种设计显著提高了准确性,并使得每个注意力块的深度和广度都能灵活扩展。

高效的知识转移框架
GEM的真正价值在于它能将学到的知识有效传播给数百个面向用户的垂直模型。为此,Meta开发了直接转移和分层转移两种策略:
-
直接转移:使GEM能够在它训练过的相同数据空间内向主要垂直模型传递知识 -
分层转移:将GEM的知识提炼到特定领域的基础模型中,再由这些模型教导垂直模型
这些方法结合了知识蒸馏、表示学习和参数共享等一系列技术,实现了标准知识蒸馏两倍的转移效率。
强大的训练基础设施
训练GEM这样的巨型模型需要前所未有的计算资源。Meta重新设计了训练堆栈,在使用16倍更多GPU的同时,将有效训练FLOPS提高了23倍。更令人印象深刻的是,模型FLOPS利用率(MFU)——衡量硬件效率的关键指标——提高了1.43倍,表明GPU资源得到了更好的利用。
深入解析GEM的架构设计
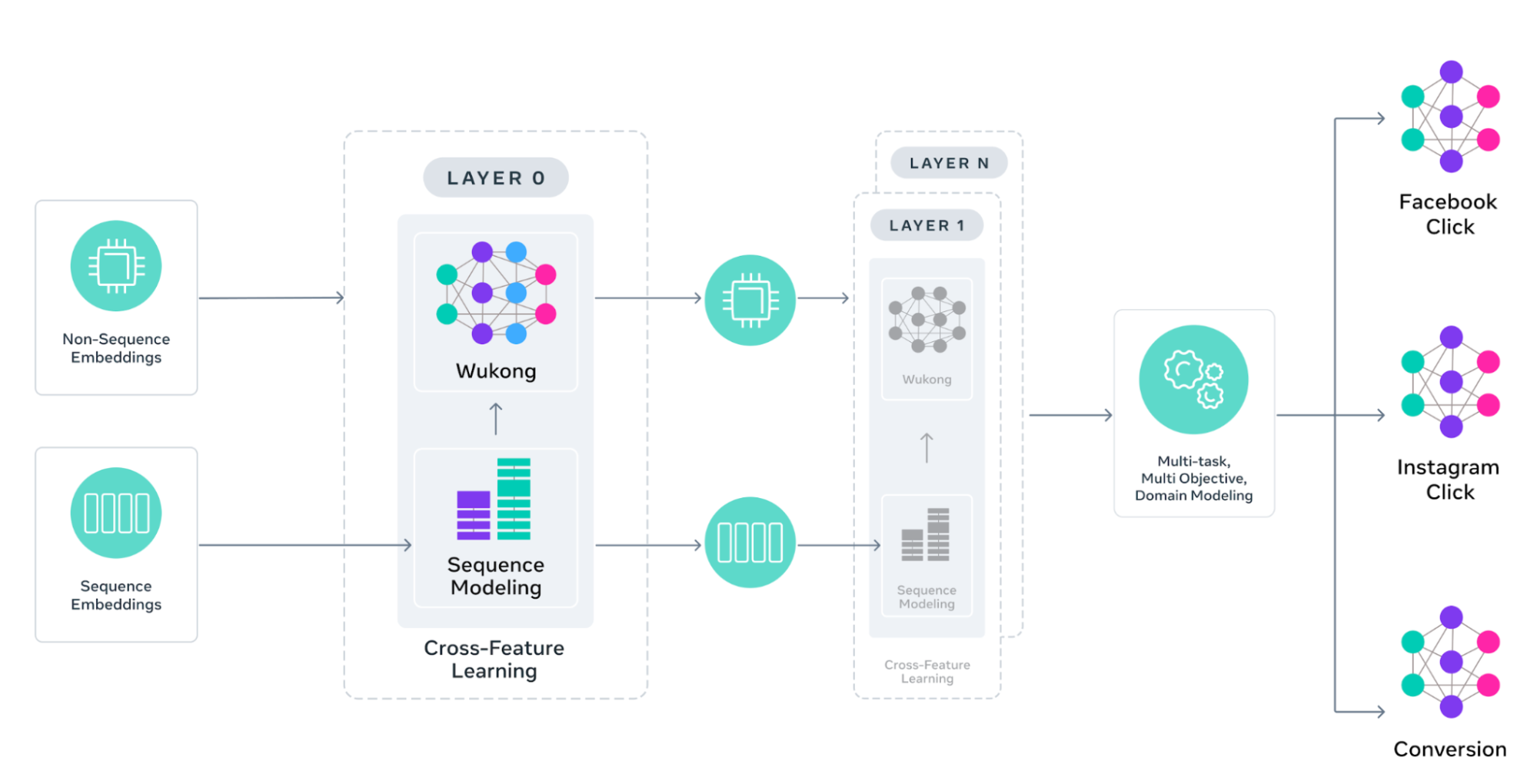
要理解GEM为何如此高效,我们需要深入了解它的架构设计思路。GEM的训练数据包括广告内容和用户参与数据,涵盖广告和有机互动。从这些数据中提取的特征被精心分类并分别处理,同时保持跨特征学习的能力。
非序列特征交互建模:理解用户与广告的匹配逻辑
在广告推荐中,理解用户属性如何与广告特征互动至关重要。GEM通过增强Wukong架构,使用具有跨层注意力连接的可堆叠分解机,让模型学习哪些特征组合最为重要。
每个Wukong块都可以垂直扩展(用于更深的交互)和水平扩展(用于更广的特征覆盖),从而能够发现日益复杂的用户-广告模式。这种设计使得GEM能够识别出那些不太明显但却极具价值的特征关联,比如特定年龄段用户在不同时间段对某类广告创意的反应模式。
离线序列特征建模:挖掘用户行为背后的意图
用户行为序列——包括广告/内容点击、查看和互动的长序列——包含了关于偏好和意图的丰富信号。传统架构难以高效处理如此长的序列,而GEM通过金字塔并行结构解决了这一挑战。
这种结构以金字塔形式堆叠多个并行交互模块,以大规模捕捉复杂的用户-广告关系。新的可扩展离线特征基础设施处理包含数千个事件的序列,而存储成本最小化,使GEM能够从更长的用户有机互动和广告互动历史中学习。
通过建模这些扩展的用户行为序列,GEM能更有效地发现模式和关系,从而对用户的购买旅程产生更深入、更准确的理解。例如,模型可以识别出用户从最初注意到产品到最终购买之间可能经历的多个中间步骤,并对每个步骤提供最相关的广告内容。
跨特征学习:保留完整用户旅程信息
现有方法通常将用户行为序列压缩为紧凑向量以供下游任务使用,但这有关键参与信号丢失的风险。GEM采用了不同的方法,在实现高效跨特征学习的同时保留完整的序列信息。
GEM的设计采用InterFormer架构,使用具有交错结构的并行摘要,在序列学习(如自定义变换器架构)和跨特征交互层之间交替进行。这使得模型能够在保持对完整用户旅程访问的同时,逐步完善其对序列的理解。
这种设计促进了高效的交互学习,同时保持了用户序列数据的结构完整性——使GEM能够扩展到更高层数而不会丢失关键行为信号。在实际应用中,这意味着即使用户的行为路径异常复杂多变,GEM仍然能够准确捕捉其核心兴趣点。
多域学习与特定领域优化
传统的广告推荐系统难以在广泛的产品生态系统中平衡学习——要么孤立地对待不同表面(从而错过有价值的跨平台洞察),要么同等对待(忽略平台特定行为)。像Facebook、Instagram和商务短信这样的不同Meta表面各有独特的用户行为和交互模式。
GEM通过从跨表面用户互动中学习,同时确保预测仍然适合每个表面的独特特征来解决这个问题。例如,这使得GEM能够利用Instagram视频广告参与度的洞察来改进Facebook信息流广告预测,同时针对每个领域的特定目标(如点击或转化)优化预测。
这种多域学习能力使得GEM能够打破平台壁垒,形成统一的用户理解,同时又不会忽视每个平台特有的用户交互模式。
最大化知识转移:GEM的后训练技术
GEM只有将其知识有效转移到数百个面向用户的垂直模型,才能产生真正影响。Meta开发了一套精致的后训练技术,确保GEM的智慧能够渗透到整个广告系统。
知识蒸馏:解决信号滞后问题
在Meta的广告系统中,垂直模型经常遭受陈旧监督的困扰,这是由于基础模型训练和评估的延迟,以及GEM或基础模型预测与垂直模型的表面特定目标之间的域不匹配造成的。这些垂直模型(学生)和GEM(老师)之间过时或错配的信号会随着时间推移降低学生模型的准确性和适应性。
为解决这个问题,Meta在训练期间使用学生适配器——一个使用最新真实数据细化老师输出的轻量级组件。它学习一种转换,能更好地将老师预测与观察结果对齐,确保学生模型在整个训练过程中获得更及时和领域相关的监督。
这种方法有效解决了大型基础模型与敏捷垂直模型之间的同步问题,使得整个系统能够保持预测的准确性和时效性。
表示学习:构建语义对齐的特征空间
表示学习是模型自动从原始数据中驱动有意义且紧凑特征的过程,从而实现更有效的下游任务,如广告点击预测。表示学习通过生成语义对齐的特征来补充知识蒸馏,支持从老师模型到学生模型的高效知识转移。
通过这种方法,GEM可以在不增加推理开销的情况下有效提高从基础模型到垂直模型的转移效率。这意味着整个系统能够获得更强大的推理能力,而不会牺牲响应速度或增加计算成本。
参数共享:实现高效知识复用
参数共享是一种多个模型或组件重用同一组参数以减少冗余、提高效率和促进知识转移的技术。
在GEM的上下文中,参数共享通过允许垂直模型有选择地融入基础模型的组件来实现高效的知识重用。这让更小、对延迟敏感的垂直模型能够利用基础模型的丰富表示和预先学习的模式,而无需承担其全部计算成本。
这三种技术组合使用,形成了一个完整的知识转移生态系统,确保GEM的智慧能够有效传递到整个广告模型舰队,从而为用户提供更加个性化和相关的广告体验。
GEM的训练之道:规模与效率的平衡艺术
训练GEM这种规模的模型是一项巨大的工程挑战,需要全新的训练方法和基础设施优化。GEM的操作规模通常只有现代大语言模型才能见到,训练它需要彻底改革我们的训练方案。
分布式训练策略
训练像GEM这样的大型模型需要在密集和稀疏组件之间精心编排并行策略。对于模型的密集部分,混合分片分布式并行等技术优化内存使用并减少通信成本,实现密集参数在数千个GPU上的高效分布。
相比之下,稀疏组件——主要用于用户和项目特征的大型嵌入表——采用使用数据并行和模型并行的二维方法,为同步效率和内存局部性进行了优化。
这种精细的并行策略确保GEM的各个组件都能以最高效率运行,无论是处理密集的矩阵计算还是稀疏的特征嵌入。
系统级GPU吞吐量优化
除了并行性,Meta还实施了一系列技术来饱和GPU计算吞吐量并减少训练瓶颈:
-
专为可变长度(锯齿状)用户序列和计算融合设计的定制内部GPU内核,利用最新的GPU硬件特性和优化技术 -
PyTorch 2.0中的图级编译,自动化关键优化,包括用于内存节省的激活检查点和用于提高执行效率的运算符融合 -
内存压缩技术,如用于激活的FP8量化和统一嵌入格式,以减少内存占用 -
通过NCCLX(Meta的NVIDIA NCCL分支)开发的不利用流式多处理器资源的GPU通信集合,消除通信和计算工作负载之间的争用,提高重叠和GPU利用率
这些优化措施共同确保了GPU资源得到最大化利用,避免了大模型训练中常见的资源闲置和瓶颈问题。
减少训练开销和作业启动时间
为提高训练敏捷性并最小化GPU空闲时间,Meta优化了有效训练时间——处理新数据所占用的训练时间比例。通过优化训练器初始化、数据读取器设置、检查点和PyTorch 2.0编译时间等,将作业启动时间减少了5倍。特别值得注意的是,通过缓存策略将PyTorch 2.0编译时间减少了7倍。
这些改进使得研究团队能够更快地迭代实验,加速模型开发进程,同时降低计算资源浪费。
开发生命周期中的GPU效率最大化
GPU效率在模型生命周期的所有阶段都得到了优化——从早期实验到大规模训练和后训练。在探索阶段,使用轻量级模型变体以比全尺寸模型低得多的成本加速迭代。这些变体支持超过一半的实验,以最小的资源开销实现更快的想法验证。
在后训练阶段,模型运行前向传递以为下游模型生成知识,包括标签和嵌入。与大型语言模型不同,GEM还执行连续在线训练以刷新基础模型。Meta增强了训练和后训练知识生成之间的流量共享,以及基础模型和下游模型之间的流量共享,以减少计算需求。
此外,GPU效率优化已应用于所有阶段,以提高端到端系统吞吐量。这种全生命周期的优化确保从实验到部署的每个环节都能高效利用宝贵的计算资源。
GEM的未来发展路径
广告推荐系统的未来将由对人们偏好和意图的更深入理解来定义,使每次互动都感觉个性化。对广告商来说,这转化为大规模的一对一连接,推动更强的参与度和成果。
展望未来,GEM将从Meta的整个生态系统中学习,包括用户在文本、图像、音频和视频等多种模态上的有机内容和广告内容互动。GEM的这些学习将扩展到覆盖Facebook和Instagram的所有主要表面。
这种更强的多模态基础有助于GEM捕捉点击、转化和长期价值背后的细微差别,为能够智能排名有机内容和广告的统一参与模型铺平道路,为用户和广告商提供最大价值。
Meta将继续扩展GEM,并通过在其架构上推进和在最新AI硬件上改进训练方案,在更大的集群上进行训练,使其能够从更多具有多样模态的数据中高效学习,以提供精确的预测。
Meta还将发展GEM,使其能够通过推理时缩放进行推理,以优化计算分配,支持以意图为中心的用户旅程,并实现代理性、洞察驱动的广告商自动化,从而推动更高的广告支出回报率。
关于GEM的常见问题
GEM是什么,它如何改进广告推荐?
GEM是Meta的生成式广告推荐模型,是一个基于大语言模型范式构建的广告基础模型。它通过三大创新改进广告推荐:可扩展的模型架构、高效的知识转移框架和强大的训练基础设施。与之前的系统相比,GEM在利用相同数据和计算资源时,驱动广告性能增益的效率提高了4倍。
GEM如何处理不同类型的用户数据?
GEM将数据特征分为两大类:序列特征(如用户活动历史)和非序列特征(如用户属性和广告属性)。它为每种特征类型应用定制化的注意力机制,同时支持跨特征学习。这种设计使GEM能够从更长的用户行为历史中学习,同时保持对特征间复杂交互的理解。
GEM如何将知识传递给其他广告模型?
GEM使用直接转移和分层转移两种策略。直接转移使GEM能在相同数据空间内向主要垂直模型传递知识,而分层转移则将GEM的知识提炼到特定领域的基础模型中,再由这些模型教导垂直模型。这些方法结合了知识蒸馏、表示学习和参数共享等技术,实现了标准知识蒸馏两倍的转移效率。
训练GEM这样的模型需要哪些技术支持?
训练GEM需要多维度并行策略、定制GPU内核、内存压缩技术和分布式训练框架。Meta的训练堆栈在使用16倍更多GPU的同时,将有效训练FLOPS提高了23倍,同时模型FLOPS利用率提高了1.43倍,表明硬件资源得到了显著更有效的利用。
GEM对未来广告推荐系统有什么影响?
GEM为广告推荐系统带来了范式转变,使系统能够从多模态数据中学习,理解更复杂的用户意图,并提供更加个性化的广告体验。未来,GEM将能够智能排名有机内容和广告,实现真正统一的用户参与模型,同时为广告商带来更高的投资回报。
结语
Meta的生成式广告模型GEM代表了广告推荐系统发展的重要里程碑。通过创新的架构设计、高效的知识转移方法和规模空前的训练基础设施,GEM不仅显著提升了广告性能,还为整个行业的未来发展指明了方向。
随着GEM不断进化,吸收更多模态的数据并扩展其推理能力,我们有理由相信,数字广告将变得更加相关、更有价值,同时更好地服务于用户和广告商的双重需求。在这个由AI驱动的广告新时代,GEM正扮演着核心引擎的角色,推动着整个领域向更加智能、高效的方向发展。
