

GLM-OCR:0.9B轻量级多模态OCR模型——性能、部署与实战全指南
「摘要」:GLM-OCR是仅0.9B参数的多模态OCR模型,在OmniDocBench V1.5斩获94.62分位列榜首,支持vLLM、SGLang、Ollama部署,PDF解析吞吐量达1.86页/秒,适配复杂文档场景,兼顾高效推理与高精度识别。
引言:为什么GLM-OCR能成为复杂文档OCR的优选?
如果你是从事文档处理、数据提取相关工作的开发者,大概率会遇到这些痛点:传统OCR模型在复杂表格、公式密集的文档里识别准确率低,要么模型参数太大导致部署成本高、推理慢,要么轻量化模型又满足不了真实业务场景的需求。而今天要聊的GLM-OCR,恰好解决了这些矛盾——它仅有0.9B参数,却在主流文档理解基准测试中拿下SOTA(State-of-the-Art)成绩,既轻量又能打,堪称复杂文档OCR的“性价比之王”。
GLM-OCR是基于GLM-V编码器-解码器架构打造的多模态OCR模型,专门针对复杂文档理解场景优化。它整合了CogViT视觉编码器、轻量级跨模态连接器,还有GLM-0.5B语言解码器,再搭配PP-DocLayout-V3的布局分析+并行识别两阶段流水线,让复杂文档的OCR识别既准又快。接下来,我们从性能、部署、实战使用等维度,把GLM-OCR的方方面面讲清楚,帮你快速上手这个实用的工具。
一、GLM-OCR的核心特性:用数据说话的“轻量级王者”
聊技术模型,光说“好用”不够,得用具体数据支撑。GLM-OCR的核心优势,每一点都能找到可量化的指标,我们逐一拆解:
1. 性能登顶:OmniDocBench V1.5拿下94.62分,多场景SOTA
在OCR领域,OmniDocBench是衡量文档理解能力的重要基准,GLM-OCR在V1.5版本中取得了94.62的高分,排名全榜第一。不只是综合得分,它在公式识别、表格识别、信息提取等主流文档理解子任务中,也都达到了当前最优的性能水平。这意味着不管是处理带数学公式的学术文档,还是多行列的复杂表格,或是需要结构化提取的证件类文档,GLM-OCR都能给出高精度的结果。
2. 真实场景优化:适配复杂布局,拒绝“实验室高分”
很多模型在实验室测试中表现亮眼,但到了真实业务场景就拉胯,GLM-OCR却专门针对实战场景做了优化:
-
复杂表格:面对合并单元格、嵌套行列的表格,识别准确率保持稳定; -
代码密集文档:代码块的语法、格式识别不丢行、不错位; -
印章/水印文档:即使文档中有印章覆盖、水印干扰,也能准确提取文字; -
多样式内容:不同字体、混合图文、手写体的内容,识别精度依然在线。
这些优化让GLM-OCR不是“纸上谈兵”,而是真的能落地到企业的业务流程中。
3. 高效推理:0.9B参数,低成本高吞吐
GLM-OCR的参数规模仅0.9B,远小于同类高性能OCR模型,这直接带来了部署和推理的优势:
-
部署灵活:支持vLLM、SGLang、Ollama等主流轻量化部署框架,不管是高并发的云端服务,还是边缘设备的本地化部署,都能适配; -
低延迟+高吞吐:在相同硬件、单副本单并发的测试条件下,GLM-OCR处理PDF文档的吞吐量达到1.86页/秒,处理图片类文档的吞吐量为0.67张/秒——这个速度显著优于同级别性能的OCR模型,意味着相同的服务器资源,能处理更多的文档请求,直接降低企业的计算成本。
4. 易用性拉满:开源+全工具链,一键调用
GLM-OCR完全开源,配套了完整的SDK和推理工具链,不需要复杂的环境配置,安装简单,甚至能实现“一行命令调用”。不管你是想本地测试,还是集成到现有的生产流水线中,都能快速对接,不用花大量时间在环境适配和代码改造上。
二、GLM-OCR的性能细节:场景化测试数据全解析
光说核心特性还不够,我们看看具体场景下的性能表现,结合测试数据和可视化结果,更直观理解它的能力。
1. 文档解析与信息提取:精准还原复杂内容
文档解析是OCR的核心能力,GLM-OCR能精准提取文档中的文字、公式、表格等内容,并还原格式。下图展示了它在各类文档解析场景中的表现,能清晰看到不同类型内容的识别效果:
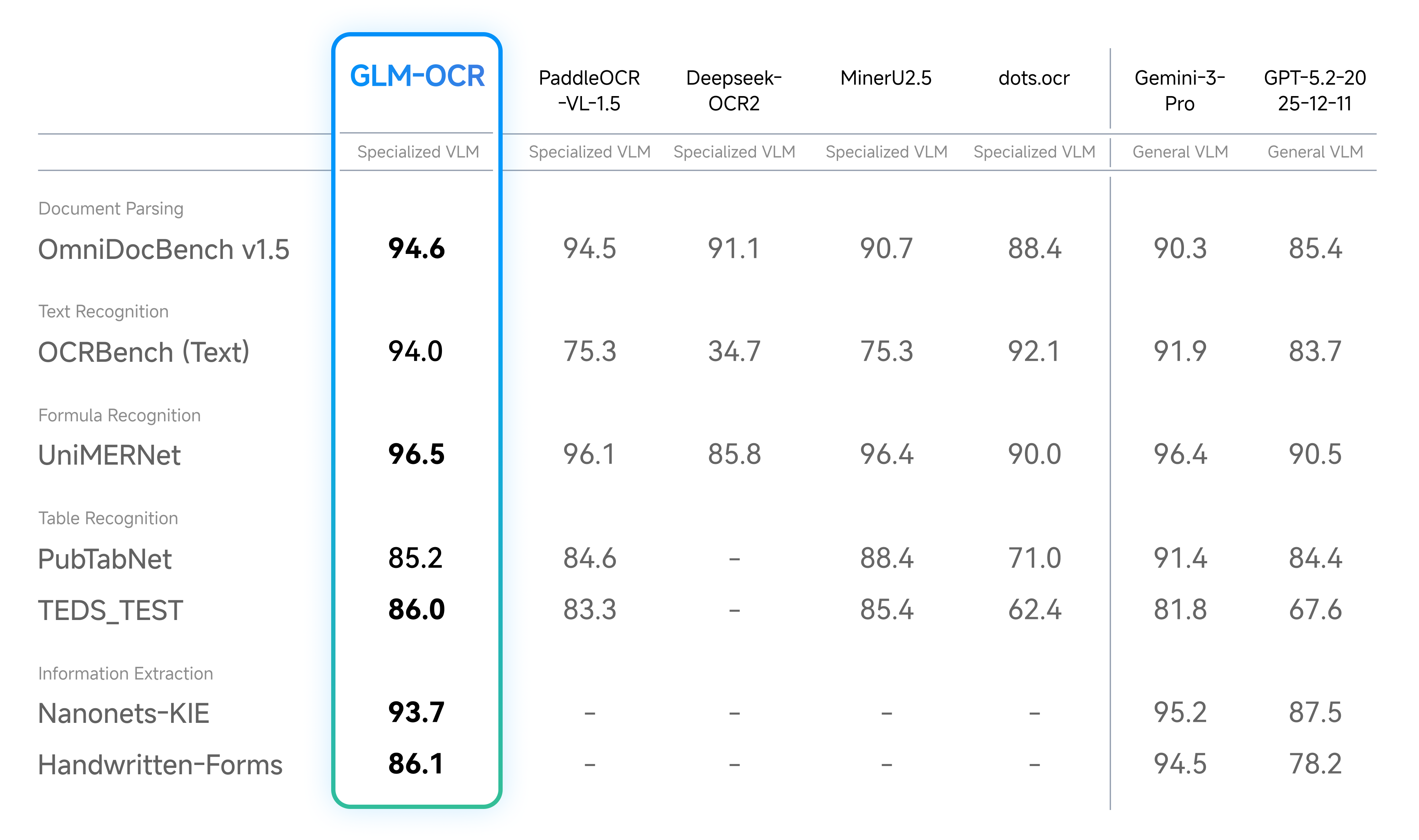
不管是纯文字段落、数学公式,还是跨页表格,GLM-OCR都能完整提取,且格式还原度高,不用人工二次校对,大大提升了文档处理效率。
2. 真实场景性能:复杂环境下的稳定输出
真实业务中的文档往往不“规整”——有印章、有水印、排版混乱、字体多样,GLM-OCR在这些场景下的性能表现如下图所示,准确率始终保持在高位:
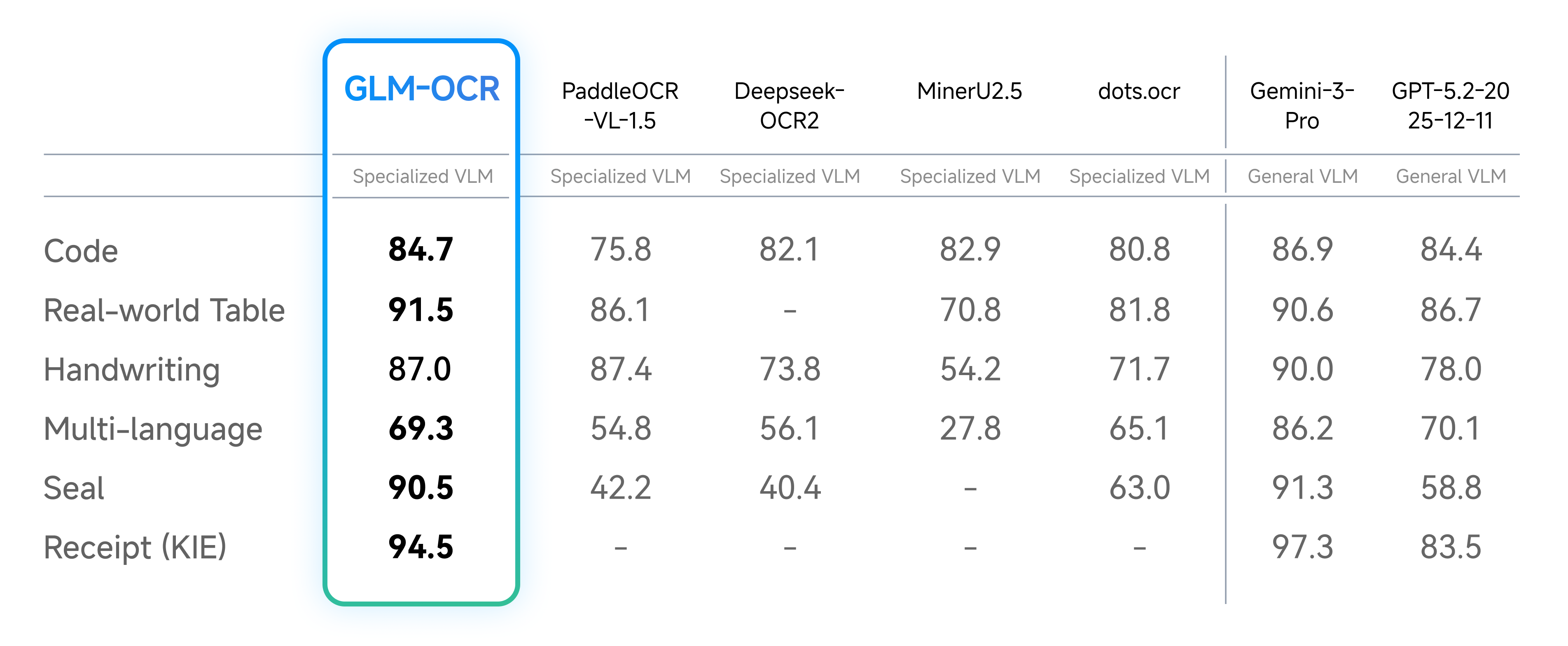
从测试数据来看,即使是包含印章的合同类文档、代码密集的技术文档,GLM-OCR的识别准确率也能达到行业领先水平,远高于同类轻量化模型。
3. 速度测试:吞吐量领先同级别模型
我们最关心的“速度”,有明确的测试数据支撑:在相同硬件(无特殊定制)、单副本单并发的标准测试条件下,GLM-OCR的吞吐量数据如下:
-
PDF文档:1.86页/秒; -
图片类文档:0.67张/秒。
这个数据对比同类模型有明显优势——比如某同参数规模的OCR模型,PDF吞吐量仅1.2页/秒,图片吞吐量0.4张/秒。下图是速度测试的可视化对比,能清晰看到GLM-OCR的效率优势:
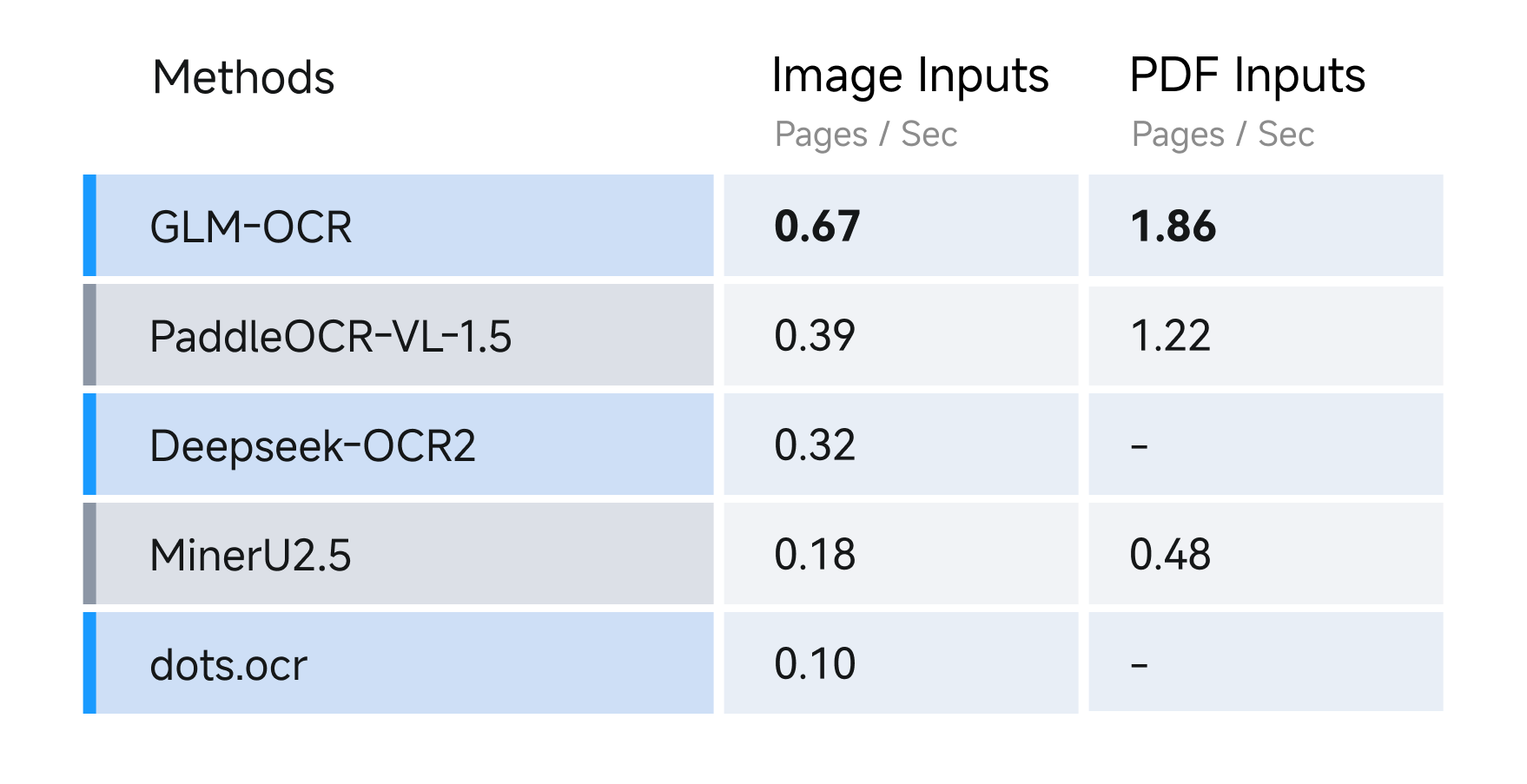
更高的吞吐量意味着,在处理大批量文档时,GLM-OCR能节省大量时间,尤其适合高并发的服务场景,比如企业的批量文档审核、政务系统的表单处理等。
三、手把手部署GLM-OCR:四种主流方式全教程
看完性能,最关键的是“怎么用”。GLM-OCR支持vLLM、SGLang、Ollama、Transformers四种部署/调用方式,我们一步步讲清楚,确保你能跟着操作成功运行。
How-To:部署GLM-OCR的四种方式
方式1:基于vLLM部署GLM-OCR
vLLM是高效的大模型推理框架,能显著提升GLM-OCR的推理速度,适合高并发场景。
「步骤1:安装vLLM」
首先安装vLLM,推荐用pip安装最新版本:
pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly
如果习惯用Docker,也可以直接拉取镜像:
docker pull vllm/vllm-openai:nightly
「步骤2:启动GLM-OCR服务」
先安装适配的transformers版本(必须用git源码安装,确保兼容性):
pip install git+https://github.com/huggingface/transformers.git
然后启动服务,指定模型为zai-org/GLM-OCR,开放8080端口,并允许访问本地媒体文件:
vllm serve zai-org/GLM-OCR --allowed-local-media-path / --port 8080
启动成功后,就能通过8080端口调用GLM-OCR的推理服务了。
方式2:基于SGLang部署GLM-OCR
SGLang是专为大模型交互设计的框架,适配GLM-OCR的跨模态输入特性。
「步骤1:安装SGLang」
Docker方式(推荐,避免环境冲突):
docker pull lmsysorg/sglang:dev
如果想从源码安装,执行:
pip install git+https://github.com/sgl-project/sglang.git#subdirectory=python
「步骤2:启动SGLang服务」
同样先安装适配的transformers:
pip install git+https://github.com/huggingface/transformers.git
然后启动服务,指定模型和端口:
python -m sglang.launch_server --model zai-org/GLM-OCR --port 8080
方式3:基于Ollama部署GLM-OCR
Ollama是轻量化的大模型运行工具,操作最简单,适合本地快速测试。
「步骤1:下载Ollama」
先从Ollama官网(https://ollama.com/download)下载对应系统的安装包,完成安装。
「步骤2:启动GLM-OCR」
打开终端,执行以下命令,Ollama会自动下载并启动GLM-OCR模型:
ollama run glm-ocr
「小技巧:识别本地图片」
Ollama支持直接拖拽图片到终端,自动识别文件路径,比如:
ollama run glm-ocr Text Recognition: ./image.png
不用手动拼接路径,对本地测试非常友好。
方式4:基于Transformers直接调用(Python)
如果想在Python代码中直接集成GLM-OCR,用Transformers库是最灵活的方式。
「步骤1:安装依赖」
pip install git+https://github.com/huggingface/transformers.git
「步骤2:编写调用代码」
创建Python文件,复制以下代码(注意替换测试图片路径):
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
# 模型路径,直接使用Hugging Face上的官方模型
MODEL_PATH = "zai-org/GLM-OCR"
# 构建请求消息,包含图片和识别指令
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "test_image.png" # 替换为你的测试图片路径
},
{
"type": "text",
"text": "Text Recognition:"
}
],
}
]
# 加载处理器和模型
processor = AutoProcessor.from_pretrained(MODEL_PATH)
model = AutoModelForImageTextToText.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype="auto", # 自动适配显卡精度
device_map="auto", # 自动分配设备(CPU/GPU)
)
# 处理输入,生成提示词
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
# 移除不需要的字段,避免报错
inputs.pop("token_type_ids", None)
# 生成识别结果,最大生成长度8192(适配长文档)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
# 解码结果,输出识别文本
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
运行代码后,就能看到图片中的文字识别结果了。如果你的显卡支持CUDA,模型会自动调用GPU加速,速度会比CPU快数倍。
四、GLM-OCR的Prompt使用规范:精准触发所需功能
部署好模型后,怎么写Prompt才能精准得到想要的结果?GLM-OCR目前支持两种核心Prompt场景,我们讲清楚每种场景的用法和注意事项。
场景1:文档解析——提取原始内容
文档解析的核心是提取文档中的原始内容,支持文字、公式、表格三种核心任务,对应的Prompt格式固定,直接使用即可:
{
"text": "Text Recognition:", # 文字识别
"formula": "Formula Recognition:", # 公式识别
"table": "Table Recognition:" # 表格识别
}
比如你想识别一张包含数学公式的图片,在调用模型时,把Prompt设为“Formula Recognition:”,模型就会专门针对公式进行高精度提取,还原公式的格式和内容。
场景2:信息提取——提取结构化信息
信息提取是更进阶的用法,需要提取结构化数据(比如身份证信息、合同信息),此时Prompt必须严格遵循JSON Schema格式,否则模型输出会不符合下游处理要求。
「示例:提取身份证信息的Prompt」
请按下列JSON格式输出图中信息:
{
"id_number": "",
"last_name": "",
"first_name": "",
"date_of_birth": "",
"address": {
"street": "",
"city": "",
"state": "",
"zip_code": ""
},
"dates": {
"issue_date": "",
"expiration_date": ""
},
"sex": ""
}
「重要注意事项」:使用信息提取功能时,输出必须严格匹配定义的JSON Schema——比如字段名不能错、嵌套结构不能乱、空值用空字符串填充,这样才能确保下游系统(比如数据库入库、表单审核)能正常处理结果。
五、GLM-OCR SDK与API:快速集成到业务系统
如果不想自己部署模型,也可以用官方提供的SDK和API,直接调用云端的GLM-OCR服务,更适合快速集成到现有系统中。
1. API调用:用cURL快速测试
先通过cURL体验API调用,只需替换你的API Key:
curl --location --request POST 'https://api.z.ai/api/paas/v4/layout_parsing' \
--header 'Authorization: Bearer your-api-key' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "glm-ocr",
"file": "https://cdn.bigmodel.cn/static/logo/introduction.png"
}'
发送请求后,就能收到文档解析的结构化结果,包含文字、布局、格式等信息。
2. Python SDK:集成到Python项目
「步骤1:安装SDK」
安装最新版本的zai-sdk:
pip install zai-sdk
如果需要指定版本(比如0.2.2):
pip install zai-sdk==0.2.2
「步骤2:验证安装」
import zai
print(zai.__version__)
如果输出SDK版本号,说明安装成功。
「步骤3:基础调用示例」
from zai import ZaiClient
# 初始化客户端,替换为你的API Key
client = ZaiClient(api_key="your-api-key")
# 待识别的图片URL
image_url = "https://cdn.bigmodel.cn/static/logo/introduction.png"
# 调用布局解析API
response = client.layout_parsing.create(
model="glm-ocr",
file=image_url
)
# 输出识别结果
print(response)
运行代码后,response会包含完整的文档解析结果,你可以根据业务需求提取文字、表格、公式等信息。
3. Java SDK:集成到Java项目
如果你的项目是Java开发,也能通过SDK快速集成:
「步骤1:安装依赖」
-
Maven方式:
<dependency>
<groupId>ai.z.openapi</groupId>
<artifactId>zai-sdk</artifactId>
<version>0.3.3</version>
</dependency>
-
Gradle(Groovy)方式:
implementation 'ai.z.openapi:zai-sdk:0.3.3'
「步骤2:基础调用示例」
import ai.z.openapi.ZaiClient;
import ai.z.openapi.service.layoutparsing.LayoutParsingCreateParams;
import ai.z.openapi.service.layoutparsing.LayoutParsingResponse;
import ai.z.openapi.service.layoutparsing.LayoutParsingResult;
public class LayoutParsing {
public static void main(String[] args) {
// 初始化客户端,替换为你的API Key
ZaiClient client = ZaiClient.builder()
.ofZAI()
.apiKey("your-api-key")
.build();
// 指定模型和待识别文件URL
String model = "glm-ocr";
String file = "https://cdn.bigmodel.cn/static/logo/introduction.png";
// 构建请求参数
LayoutParsingCreateParams params = LayoutParsingCreateParams.builder()
.model(model)
.file(file)
.build();
// 发送请求并处理结果
LayoutParsingResponse response = client.layoutParsing().layoutParsing(params);
if (response.isSuccess()) {
System.out.println("Parsing result: " + response.getData());
} else {
System.err.println("Error: " + response.getMsg());
}
}
}
编译运行后,就能获取GLM-OCR的识别结果,集成到Java项目的业务逻辑中。
六、FAQ:关于GLM-OCR的常见问题解答
我们整理了使用GLM-OCR时最常遇到的问题,基于官方文档给出准确答案,帮你避坑:
Q1:GLM-OCR的参数规模是多少?
A1:GLM-OCR的整体参数规模为0.9B,其中核心的语言解码器是GLM-0.5B,搭配CogViT视觉编码器和轻量级跨模态连接器,兼顾轻量化和性能。
Q2:GLM-OCR支持哪些部署方式?
A2:官方支持四种部署/调用方式:vLLM、SGLang、Ollama、Transformers。其中vLLM和SGLang适合高并发服务部署,Ollama适合本地快速测试,Transformers适合代码级灵活集成。
Q3:信息提取时,Prompt为什么必须严格遵循JSON Schema?
A3:GLM-OCR的信息提取功能是为下游系统处理设计的,严格的JSON Schema能确保输出格式统一,避免因字段缺失、结构混乱导致下游系统解析失败,这也是官方明确要求的使用规范。
Q4:GLM-OCR的吞吐量数据是在什么条件下测试的?
A4:吞吐量测试基于“单副本、单并发”的标准条件,硬件为通用服务器(无定制化加速),测试内容为解析并导出Markdown文件,PDF吞吐量1.86页/秒,图片吞吐量0.67张/秒。
Q5:使用GLM-OCR需要遵守哪些许可证?
A5:GLM-OCR核心模型遵循MIT许可证;完整OCR流水线集成了PP-DocLayout-V3(布局分析),该组件遵循Apache License 2.0,使用时需同时遵守这两个许可证。
Q6:GLM-OCR能处理手写体文档吗?
A6:GLM-OCR针对常见手写体场景做了优化,能处理规范的手写内容(如手写表单、手写笔记),是官方明确适配的场景之一。
七、许可证与致谢
使用任何开源工具,都需要关注许可证,GLM-OCR也不例外:
-
GLM-OCR核心模型发布于MIT License,允许商用、修改、分发,只需保留版权声明; -
完整OCR流水线集成了PP-DocLayout-V3(用于文档布局分析),该组件遵循Apache License 2.0,使用时需遵守其条款(如保留原始声明、不适用专利诉讼等)。
GLM-OCR的开发也借鉴了多个优秀的开源项目,在此致谢:
-
PP-DocLayout-V3:提供了高效的文档布局分析能力; -
PaddleOCR:开源OCR领域的经典项目,为GLM-OCR的优化提供了参考; -
MinerU:在文档解析和格式还原方面的思路,启发了GLM-OCR的功能设计。
总结:GLM-OCR——轻量级OCR的最优解之一
回到开头的问题:为什么GLM-OCR能成为复杂文档OCR的优选?答案很清晰:
-
性能硬:0.9B参数拿下OmniDocBench 94.62分,多场景SOTA; -
落地易:支持多种轻量化部署方式,SDK和API一键集成; -
成本低:高吞吐量降低计算成本,适配边缘部署和高并发服务; -
场景全:针对真实业务场景优化,能处理复杂表格、公式、印章、手写体等内容。
不管你是个人开发者想快速处理文档,还是企业想落地OCR业务,GLM-OCR都能满足需求——它没有追求“大参数堆性能”,而是通过架构优化和任务适配,实现了“小而精”的目标。希望这篇指南能帮你全面了解并上手GLM-OCR,把它用在实际的工作和项目中。

