

GLM-4.5:大语言模型领域的新突破
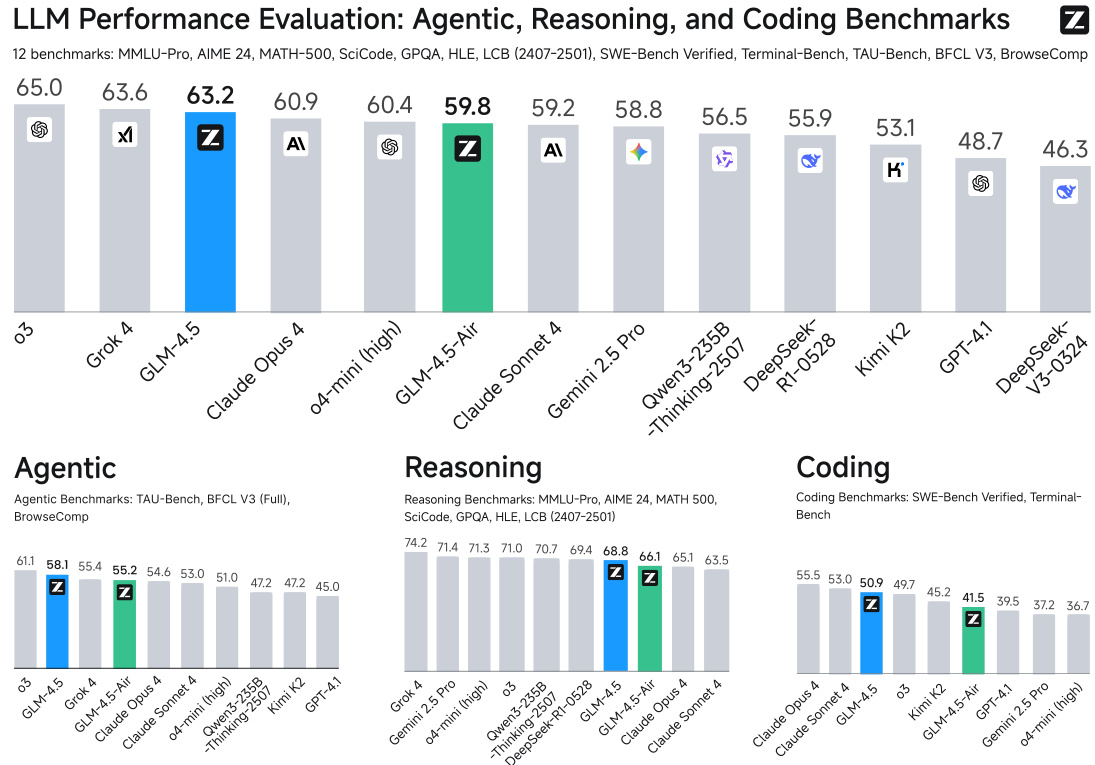
图1:GLM-4.5在代理、推理和编码(ARC)基准测试中的平均表现

一、什么是GLM-4.5?
GLM-4.5是由智谱AI和清华大学联合研发的新一代开源大语言模型(LLM)。与常见的语言模型不同,它采用了混合专家架构(MoE),在保持高参数规模(总参数3550亿)的同时,通过动态激活机制(仅32亿参数参与计算)实现高效运算。
核心亮点:
-
多模态推理能力:支持「思考模式」和「直接响应」两种工作方式 -
领域突破:在代理任务(Agent)、复杂推理(Reasoning)、代码生成(Coding)三大领域表现优异 -
开源友好:提供355B完整版和106B精简版(GLM-4.5-Air)两个版本
二、架构设计:为什么选择MoE?
2.1 什么是MoE架构?
MoE(Mixture-of-Experts)是一种特殊的神经网络结构,将模型拆分为多个「专家模块」。每个输入 token 会根据内容动态选择最相关的专家处理,就像医院分诊系统——不同症状的患者被分配到不同科室。
参数对比表
| 模型 | 总参数 | 激活参数 | 密集层数 | MoE层数 |
|---|---|---|---|---|
| GLM-4.5 | 355B | 32B | 3 | 89 |
| GLM-4.5-Air | 106B | 12B | 1 | 45 |
| DeepSeek-V3 | 671B | 37B | 3 | 58 |
| Kimi K2 | 1043B | 32B | 1 | 60 |
数据来源:论文Table 1
2.2 架构创新点
-
深度优先设计
与同类模型(如DeepSeek-V3)相比,GLM-4.5选择增加模型层数而非扩大宽度。实验表明,更深层的架构在数学推理等任务中表现更优。 -
注意力机制优化
-
采用分组查询注意力(GQA) -
注意力头数增加到96个(隐藏维度5120时) -
引入QK-Norm技术稳定注意力逻辑值范围
-
-
多Token预测层(MTP)
在模型末端增加特殊层,支持推理时的投机解码(Speculative Decoding),提升生成速度30%以上。
三、训练过程:如何打造顶级模型?
3.1 预训练:数据决定上限
训练数据构成
-
网页文本(英语/中文) -
多语言文本(通过质量分类器筛选) -
代码仓库(GitHub等平台) -
数学/科学文献
数据处理特色
-
网页去重:结合MinHash和语义去重(SemDedup)技术 -
代码增强:使用Fill-In-the-Middle目标函数训练 -
质量分层:对不同来源数据赋予权重,优先学习高频知识
3.2 中期训练:专项能力突破
阶段1:代码仓库级训练
-
将同一仓库的代码文件拼接训练 -
包含问题(Issues)、拉取请求(PRs)、提交记录(Commits) -
序列长度扩展至32K tokens
阶段2:合成推理数据
-
生成数学/科学竞赛题解过程 -
构造代码竞赛题目及解答
阶段3:长上下文与代理训练
-
序列长度扩展至128K tokens -
引入大规模代理轨迹数据(Agent Trajectories)
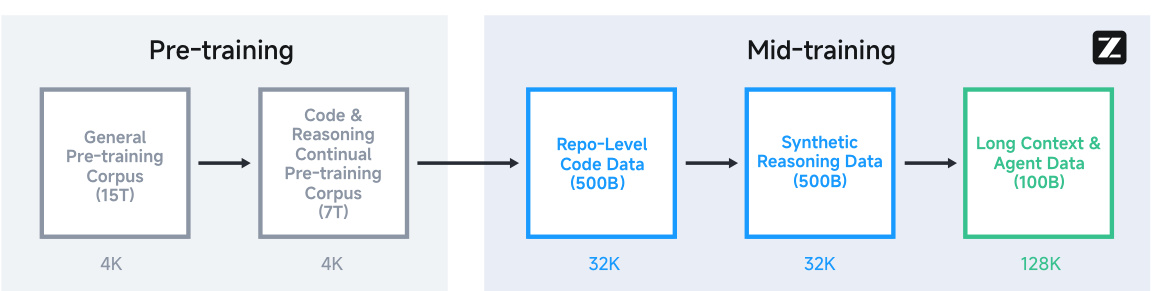
图3:GLM-4.5预训练与中期训练完整流程
3.3 后训练:专家模型迭代
采用两阶段策略:
-
专家训练(Expert Training)
训练三个专项模型:-
推理专家(Reasoning) -
代理专家(Agent) -
通用对话专家(General Chat)
-
-
统一训练(Unified Training)
通过自蒸馏(Self-Distillation)整合专家能力,最终模型可同时支持:-
深度思考模式(复杂任务) -
快速响应模式(日常对话)
-
四、性能表现:实际效果如何?
4.1 代理任务(Agent)
关键指标
| 基准测试 | GLM-4.5 | 对比模型(o3) |
|---|---|---|
| TAU-Retail | 79.7% | 70.4% |
| BFCL V3 | 77.8% | 72.4% |
| BrowseComp | 26.4% | 49.7% |
数据来源:Table 3
实际应用案例
在TAU-Bench零售场景测试中,模型能完成:
-
多轮对话理解用户需求 -
调用API查询商品库存 -
处理订单修改等复杂操作
4.2 推理能力
数学与科学任务表现
| 基准测试 | 准确率 | 对比模型(o3) |
|---|---|---|
| AIME 24 | 91.0% | 90.3% |
| MATH-500 | 98.2% | 99.2% |
| GPQA | 79.1% | 82.7% |
数据来源:Table 4
技术亮点
-
在AIME 2024数学竞赛题中准确率达91% -
解决「人类最后考试」(HLE)14.4%的问题 -
LiveCodeBench编码任务得分72.9%
4.3 代码生成
SWE-bench验证集结果
| 模型 | 准确率 | 对比模型(Claude Sonnet 4) |
|---|---|---|
| GLM-4.5 | 64.2% | 70.4% |
数据来源:Table 5
实际能力展示
-
修复真实GitHub问题的成功率达64.2% -
Terminal-Bench终端任务得分37.5%
五、典型应用场景
5.1 代码开发助手
功能支持
-
自动生成Python/JavaScript代码 -
修复现有代码库的问题 -
理解项目文档并提供建议
真实案例
在CC-Bench测试中:
-
40.4%任务胜率 vs Claude Sonnet 4 -
工具调用成功率90.6%(行业领先)
5.2 智能客服系统
核心优势
-
支持多轮复杂对话 -
理解隐含用户意图 -
调用外部API处理订单查询
5.3 教育辅助
适用场景
-
数学问题自动解题 -
代码作业批改 -
科学概念解释
六、如何获取与使用?
6.1 下载地址
-
完整版模型
HuggingFace链接 -
精简版模型
GLM-4.5-Air
6.2 硬件要求
| 模型版本 | 显存需求 | 推荐GPU配置 |
|---|---|---|
| GLM-4.5 | 80GB+ | NVIDIA H100/A100 |
| GLM-4.5-Air | 24GB+ | NVIDIA A10/A6000 |
七、常见问题(FAQ)
Q1: GLM-4.5适合哪些开发者?
适合需要构建智能代理系统、自动化代码工具或复杂对话机器人的开发者。特别适合:
-
企业级智能客服开发 -
代码辅助工具构建 -
教育类AI应用
Q2: 如何调用模型API?
官方提供Python SDK示例:
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="your_api_key")
response = client.chat.completions.create(
model="glm-4.5",
messages=[{"role": "user", "content": "写一个Python排序算法"}]
)
print(response.choices[0].message.content)
Q3: 与其他模型相比优势在哪?
-
参数效率:355B参数达到与千亿参数模型相当的性能 -
长上下文处理:原生支持128K tokens上下文 -
多语言支持:中文/英文混合处理能力强
Q4: 是否有微调指南?
官方仓库提供:
-
LoRA微调示例代码 -
RLHF训练框架 -
多GPU训练配置模板
八、技术演进方向
论文提到未来将重点提升:
-
多模态能力:支持图像/视频理解 -
推理速度优化:通过投机解码技术 -
安全性增强:更好的价值观对齐

