

Gelato-30B-A3B:革新GUI操作的AI模型,超越GTA1-32B
在人工智能技术飞速发展的今天,如何让AI代理准确理解并执行用户在图形界面上的操作指令,成为了一个关键挑战。想象一下,当你对AI说“打开设置菜单”或“点击保存按钮”,它能否精准找到并操作对应的屏幕元素?这正是图形用户界面(GUI) grounding 技术要解决的核心问题。
最近,ML Foundations研究团队发布了 Gelato-30B-A3B——一个专门为GUI计算机使用任务设计的先进 grounding 模型。这个模型不仅在专业基准测试中表现卓越,甚至超越了规模更大的视觉语言模型,为AI代理的实用化迈出了重要一步。
什么是GUI Grounding,为什么它如此重要?
GUI grounding 指的是将自然语言指令映射到图形用户界面中具体元素位置的过程。简单来说,就是让AI理解“点击哪里”来实现用户的指令。
在实际应用中,一个完整的计算机使用代理通常由两部分组成:规划模块负责理解用户的高层指令并制定行动计划,grounding 模块则负责将这些计划转化为具体的界面操作。 Gelato-30B-A3B 就是这样一个专门负责 grounding 的模块化组件。
举个例子,当用户指示“清理浏览器缓存”,规划模型(如GPT-5)可能会分解为一系列步骤:“打开浏览器设置”、“找到隐私与安全选项”、“选择清除浏览数据”。 Gelato 的任务就是精准定位每个步骤中需要操作的屏幕元素——找到设置图标的位置、识别隐私选项的准确坐标,最终完成整个任务。
这种规划与执行的分离设计极具实用价值。现代计算机环境包含多种操作系统(Windows、macOS、Linux)和成千上万种应用程序,每种都有独特的界面布局。通过专门的 grounding 模型,AI代理可以适应这种多样性,而不需要为每个环境重新训练整个系统。
Gelato-30B-A3B模型详解
Gelato-30B-A3B是一个拥有310亿参数的大型模型,基于Qwen3-VL-30B-A3B Instruct模型构建,采用了混合专家架构。从技术角度看,它接收两个输入:屏幕截图和文本指令,输出则是一个单一的点击坐标。

这种设计使得 Gelato 可以轻松集成到现有的AI代理框架中。在实际部署时,规划模型决定下一步要执行的高级动作,然后调用 Gelato 将这些动作解析为屏幕上的具体点击位置。
模型性能表现
在专业基准测试中,Gelato-30B-A3B展现出了卓越的性能:
-
☾ 在ScreenSpot Pro测试中达到63.88%的准确率 -
☾ 在OS-World-G测试中达到69.15%的准确率 -
☾ 在OS-World-G Refined测试中达到74.65%的准确率
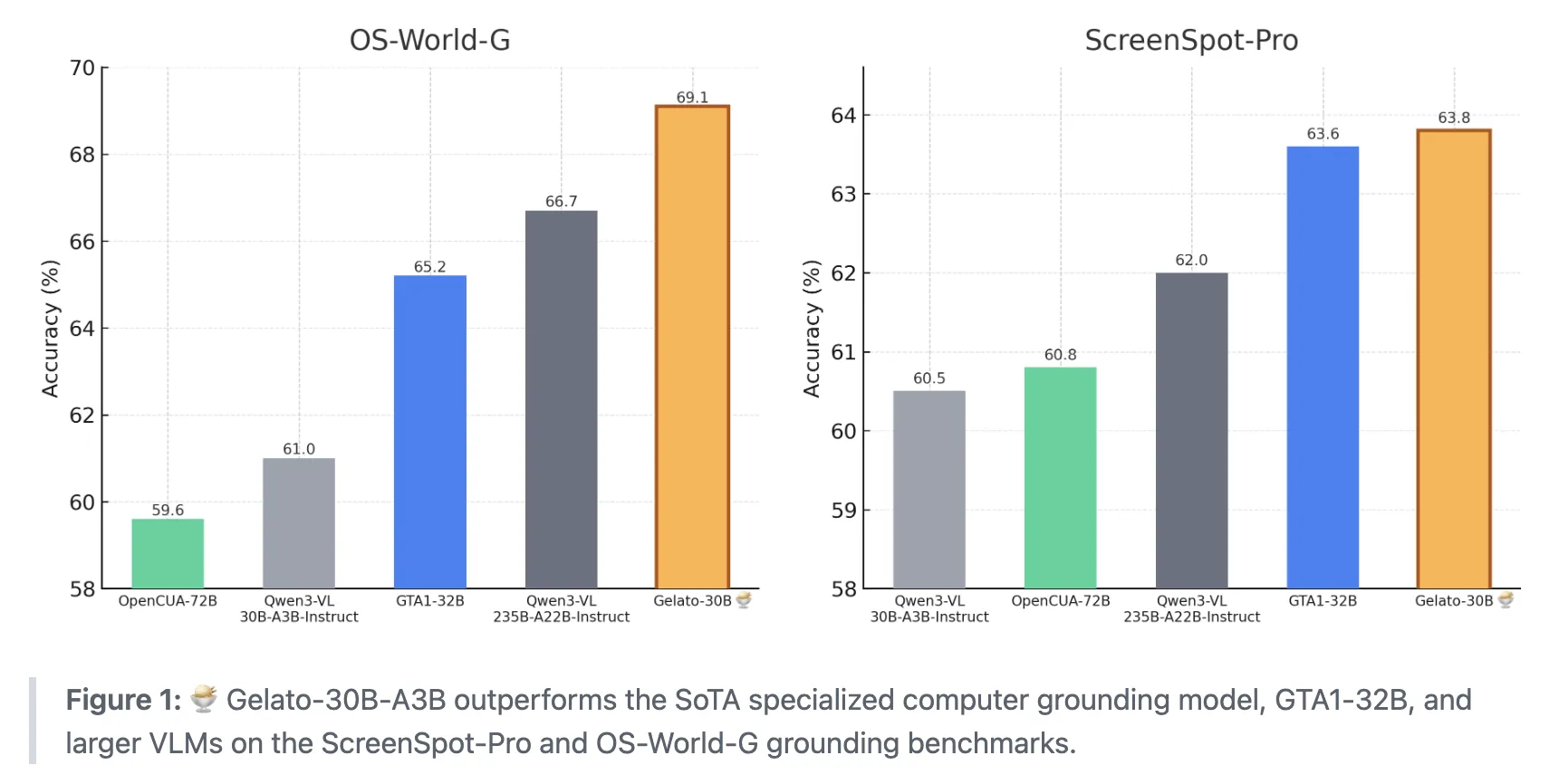
这些数字可能看起来不算极高,但在GUI grounding这一极具挑战性的任务中,已经代表了当前最先进的水平。更重要的是,Gelato-30B-A3B的表现超越了之前的专用计算机 grounding 模型GTA1-32B,甚至超过了参数量大得多的视觉语言模型,如Qwen3-VL-235B-A22B-Instruct。
| 模型 | 激活参数量 | ScreenSpot-Pro | OS-World-G | OS-World-G (Refined) |
|---|---|---|---|---|
| Qwen3-VL-30B-A3B-Instruct | 30亿 | 60.5% | 61.0% | – |
| Qwen3-VL-235B-A22B-Instruct | 220亿 | 62.0% | 66.7% | – |
| OpenCUA-72B | 720亿 | 60.8% | 59.6% | – |
| GTA1-32B | 320亿 | 63.6% | 65.2% | 72.2% |
| Gelato-30B-A3B | 30亿 | 63.88% | 69.15% | 74.65% |
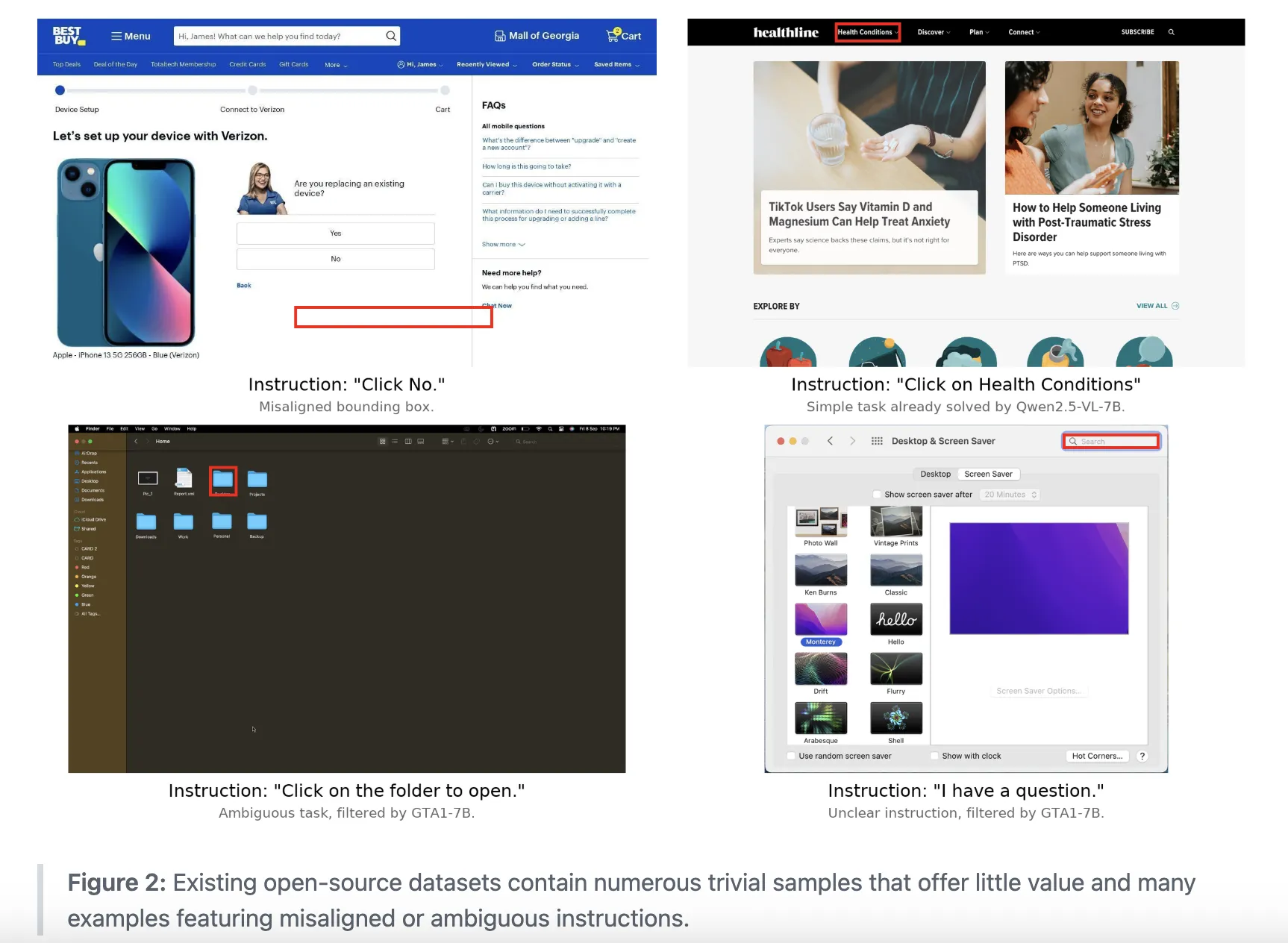
Click-100k数据集:高质量训练数据的基石
任何优秀的AI模型都离不开高质量的训练数据。 Gelato-30B-A3B 的成功很大程度上归功于其训练基础——Click-100k数据集。这是一个专门为GUI grounding任务精心策划的数据集,包含了超过10万个计算机屏幕图像与自然语言指令的配对样本。
数据集的构建过程
Click-100k并非从零开始创建,而是通过整合和优化多个现有的公共数据集构建而成。研究人员汇集了包括ShowUI、AutoGUI、PC Agent E、WaveUI、OS Atlas、UGround、PixMo Points、SeeClick、UI VISION等多个数据源,并将它们映射到一个统一的架构中。
每个数据源最多贡献5万个样本,确保数据集的多样性和平衡性。每个样本都包含屏幕图像、自然语言指令、目标元素的边界框、图像尺寸和归一化后的边界框坐标。

严格的数据过滤流程
仅仅汇集数据还不够,研究团队实施了一套严格的数据过滤流程,以确保训练样本的质量:
-
使用OmniParser排除无效点击:过滤掉那些没有落在检测到的界面元素上的点击 -
移除简单样本:使用Qwen2.5-7B-VL和SE-GUI-3B识别并移除过于简单的交互(如简单的超链接点击) -
消除指令与区域不匹配的样本:使用GTA1-7B-2507和UI-Venus-7B移除那些文本指令与点击区域不一致的样本
这种精心设计的数据过滤策略带来了显著的效果提升。实验表明,在过滤后的数据上训练的模型,比在未过滤数据上训练的模型,在ScreenSpot Pro基准测试中准确率高出9个百分点。
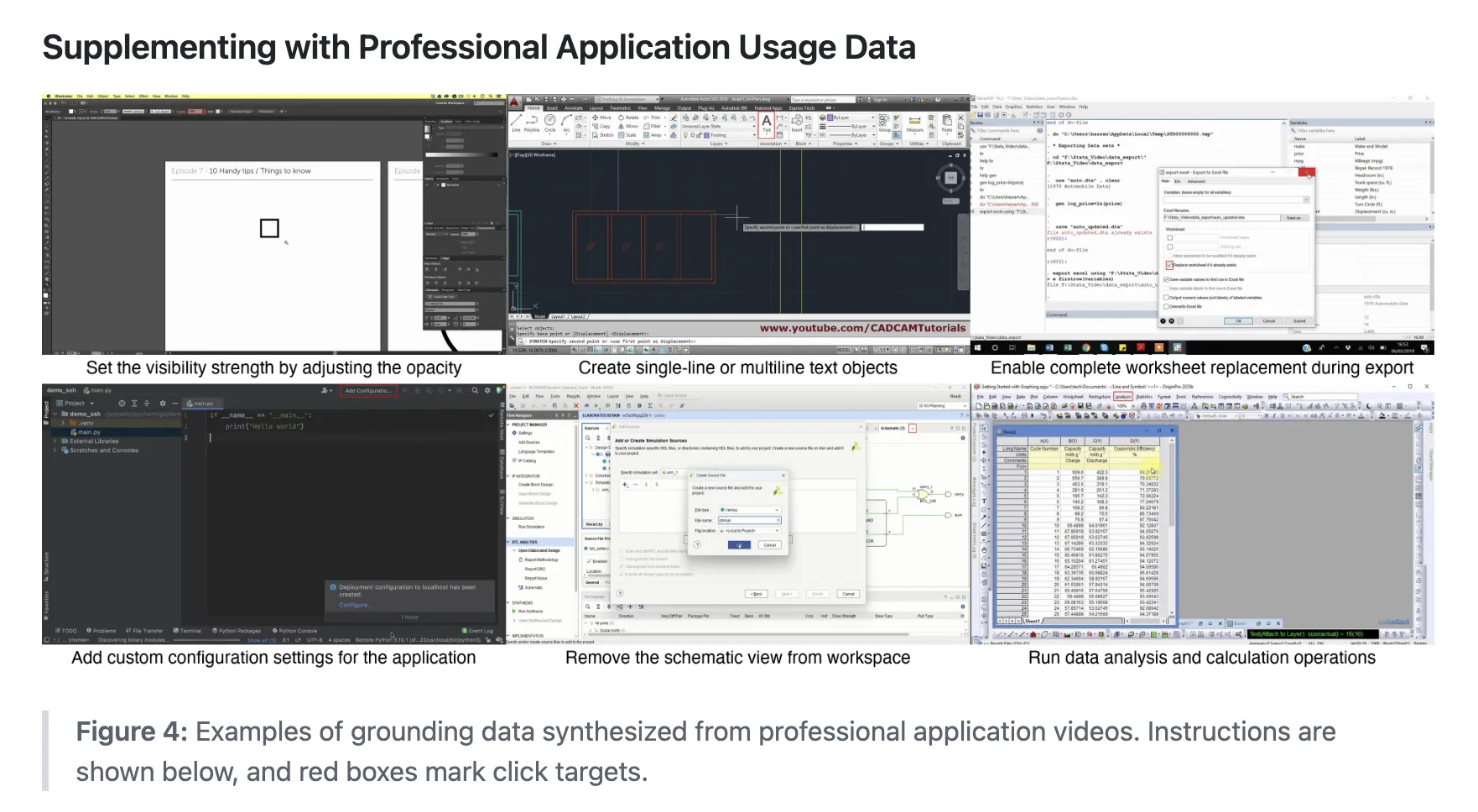
增强专业应用覆盖
现有的公开数据集往往缺乏专业应用程序的覆盖,这对于构建通用的计算机使用代理来说是一个重大缺口。为了解决这个问题,研究团队特意添加了来自UI VISION和JEDI子集(专注于电子表格和文本单元格操作)的数据。
此外,他们还从85多个专业应用程序教程视频中提取数据,使用Claude-4-Sonnet生成点击边界框和低级指令,并辅以人工检查和校正。这一步骤显著增强了模型在处理专业软件任务时的能力。
Gelato-30B-A3B的训练过程
Gelato-30B-A3B的训练采用了GRPO(Group Relative Policy Optimization)算法,这是一种基于强化学习的方法,源自DeepSeekMath等系统的研究成果。
训练设置的关键特点
研究团队遵循DAPO(Decoupled Advantage Policy Optimization)设置,但进行了一些重要调整:
-
☾ 从目标函数中移除了KL散度项 -
☾ 设置更高的裁剪阈值(0.28) -
☾ 跳过优势为零的rollout
奖励设计采用了稀疏奖励机制——只有当预测的点击落在目标边界框内时,才会给予奖励。这种方法与GTA1模型使用的配方相似,但通过细致的调整实现了更好的性能。
训练过程与结果
训练从Qwen3-VL-30B-A3B-Instruct模型初始化开始,在32台配备40GB内存的A100 GPU上进行了100个RL步骤。训练过程中,模型在各项基准测试上的表现稳步提升。

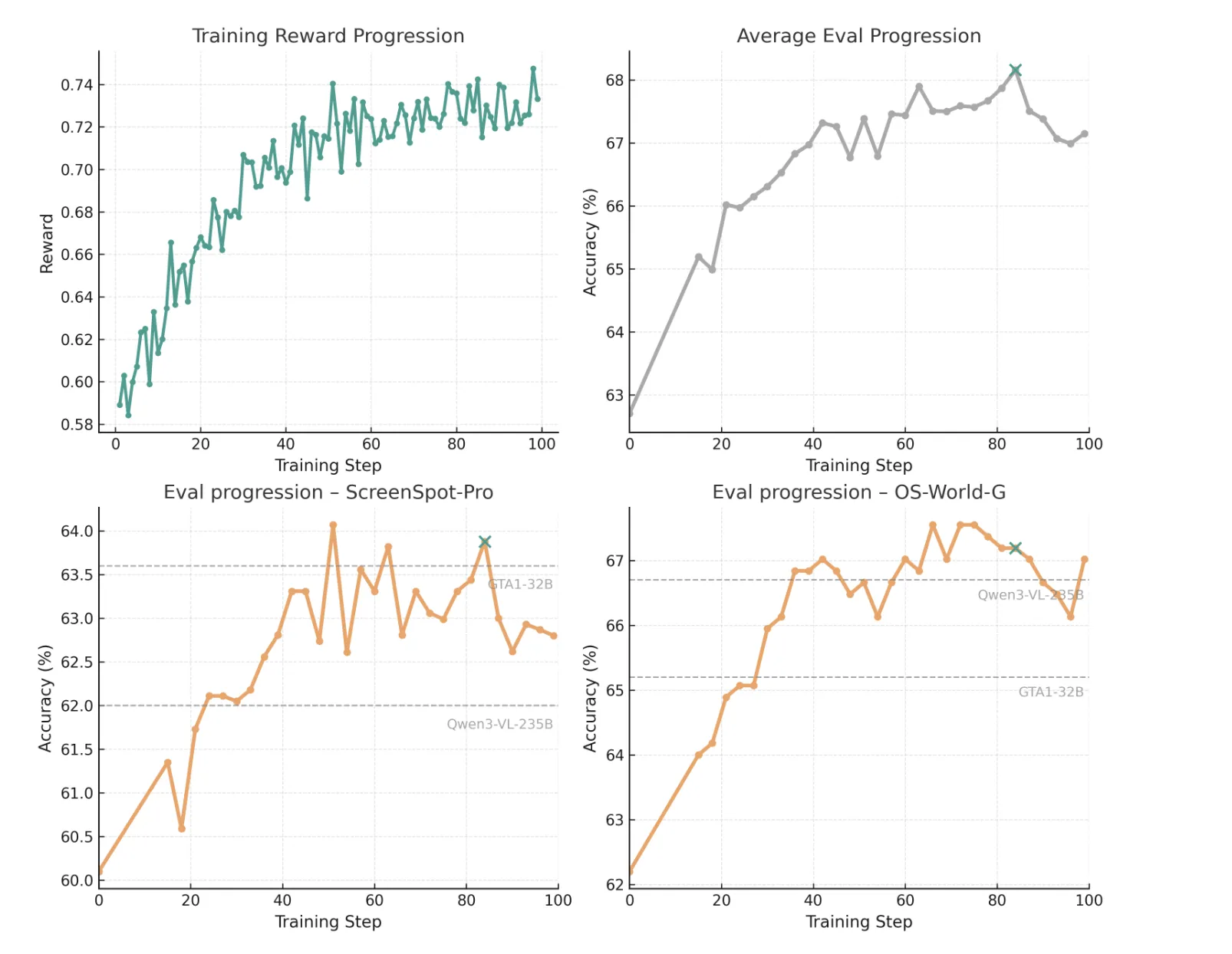
最佳检查点出现在第84步(上图中用绿色十字标记),这是根据在ScreenSpot Pro、OS-World-G和OS-World-G Refined上的平均表现选出的。此时,模型在ScreenSpot-Pro上达到63.88%的准确率,在OS-World-G和OS-World-G Refined上分别达到67.19%和73.40%的准确率。
引导模型的拒绝能力
一个有趣的发现是,研究团队无需显式训练,就成功引导出了Gelato的拒绝行为——当无法定位目标元素时,模型能够拒绝执行 grounding。只需在指令提示后附加“如果找不到元素,请返回拒绝”,就能将OS-World-G的准确率提升至69.15%,OS-World-G Refined的准确率提升至74.65%。
这种拒绝能力在实际应用中极为重要,可以防止AI代理在不确定时执行错误的操作。
端到端代理性能评估
为了评估Gelato在实际应用中的表现,研究团队将其集成到GTA1.5代理框架中,并在OS-World环境中进行了完整的计算机使用代理测试。
测试设置
在这个测试环境中:
-
☾ GPT-5作为规划模型,负责决定高级动作 -
☾ Gelato-30B-A3B负责 grounding,将动作转化为具体点击 -
☾ 代理最多执行50个步骤,每个动作之间等待3秒钟
为确保公平比较,研究团队对每个模型在固定的OS-World快照上进行了三次运行,并记录了成功率。
评估结果
Gelato-30B-A3B实现了58.71%的自动化成功率,标准差很小。在相同的测试环境中,GTA1-32B的成功率为56.97%。
然而,研究人员发现自动化的OS-World评估会遗漏一些有效的解决方案。因此,他们对20个有问题的任务进行了人工评估。在人工评分下,Gelato的成功率达到61.85%,而GTA1-32B为59.47%。

这些结果表明,更好的 grounding 能力直接转化为更强的端到端代理性能。 Gelato-30B-A3B不仅在独立的 grounding 任务中表现优异,在实际的计算机使用场景中也带来了可衡量的改进。
如何在项目中使用Gelato-30B-A3B
对于开发者和研究人员来说, Gelato-30B-A3B 已经开源,可以通过Hugging Face平台轻松获取和使用。以下是一个基本的使用示例,展示如何加载模型并进行推理:
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor
import re
from PIL import Image, ImageDraw
import requests
from io import BytesIO
def extract_coordinates(raw_string):
"""
从原始字符串中提取坐标。
参数:
raw_string: str (例如 "(100, 200)")
返回:
x: float (例如 100.0)
y: float (例如 200.0)
"""
try:
matches = re.findall(r"\((-?\d*\.?\d+),\s*(-?\d*\.?\d+)\)", raw_string)
return [tuple(map(int, match)) for match in matches][0]
except:
return 0,0
def visualize_prediction(img, pred_x, pred_y, img_width, img_height):
"""
在图像上可视化预测的坐标(高可见度)。
"""
pred_x = int((pred_x * img_width) / 1000)
pred_y = int((pred_y * img_height) / 1000)
draw = ImageDraw.Draw(img, "RGBA")
r = 30
draw.ellipse(
(pred_x - r, pred_y - r, pred_x + r, pred_y + r),
outline="lime",
fill=(0, 255, 0, 90),
width=5
)
cross_len = 15
draw.line((pred_x - cross_len, pred_y, pred_x + cross_len, pred_y), fill="lime", width=5)
draw.line((pred_x, pred_y - cross_len, pred_x, pred_y + cross_len), fill="lime", width=5)
img.save("predicted_coordinates.png")
print(f"预测坐标: ({pred_x}, {pred_y})")
# 加载模型和处理器
MODEL_PATH = "mlfoundations/Gelato-30B-A3B"
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
MODEL_PATH,
device_map="auto",
dtype="auto"
)
processor = AutoProcessor.from_pretrained(
MODEL_PATH
)
url = "https://github.com/QwenLM/Qwen3-VL/raw/main/cookbooks/assets/computer_use/computer_use1.jpeg"
response = requests.get(url)
img = Image.open(BytesIO(response.content))
img_width, img_height = img.size
# 准备消息
PROMPT = '''
您是一个专业的UI元素定位器。给定一个GUI图像和用户的元素描述,提供指定元素的坐标作为单个(x,y)点。对于有区域的元素,返回中心点。
准确输出坐标对:
(x,y)
'''
PROMPT = PROMPT.strip()
INSTRUCTION = "重新加载缓存。"
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": PROMPT + "\n\n"},
{"type": "image", "image": img},
{"type": "text", "text": "\n" + INSTRUCTION},
],
}
]
device = next(model.parameters()).device
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(device)
# 推理:生成输出
generated_ids = model.generate(**inputs, max_new_tokens=32)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# 从输出文本中提取坐标
print(f"模型输出: {output_text[0]}")
pred_x, pred_y = extract_coordinates(output_text[0])
# 从归一化坐标计算绝对坐标
visualize_prediction(img, pred_x, pred_y, img_width, img_height)
这段代码展示了 Gelato 模型的基本使用流程:加载模型、处理输入图像和指令、生成坐标预测,并将结果可视化。模型输出的坐标是归一化的(范围0-1000),需要根据实际图像尺寸转换为绝对坐标。
Gelato模型的意义与影响
Gelato-30B-A3B的发布在AI代理发展道路上标志着一个重要里程碑。它证明了通过精心策划的数据集和专门优化的训练方法,可以在GUI grounding这一关键任务上实现显著进步。
技术贡献总结
-
先进的 grounding 性能:在多项基准测试中超越了先前最先进的专用计算机 grounding 模型和规模更大的通用视觉语言模型。
-
高质量数据集:Click-100k数据集通过严格的过滤和整合流程,为GUI grounding任务提供了高质量的训练资源。
-
有效的训练方法:GRPO强化学习配方结合稀疏奖励机制,显著提高了 grounding 准确性。
-
实践验证:当与GPT-5等规划模型集成时,Gelato-30B-A3B在OS-World计算机使用任务中提高了成功率,证明更好的 grounding 直接转化为更强的端到端代理性能。
未来展望
Gelato-30B-A3B为AI代理的实用化打开了新的可能性。随着这类技术的成熟,我们可以预见AI将在更多场景中辅助或替代人类执行计算机操作任务——从简单的数据录入到复杂的工作流自动化,从桌面应用到专业软件操作。
对于开发者和组织而言,这意味着可以构建更加智能和可靠的自动化解决方案,减少重复性人工操作,提高工作效率和准确性。
常见问题解答
Gelato模型与一般的视觉语言模型有什么不同?
Gelato是一个专门为GUI grounding任务优化的模型,它接收屏幕截图和文本指令,输出具体的点击坐标。而一般的视觉语言模型通常设计用于更广泛的视觉问答任务,在专门的GUI操作任务上精度较低。Gelato通过在高质量的Click-100k数据集上专门训练,在GUI grounding任务上甚至超越了参数量大得多的通用视觉语言模型。
如何在自定义任务中使用Gelato模型?
Gelato模型可以通过Hugging Face平台轻松获取。使用流程包括:加载模型、准备屏幕截图和文本指令、调用模型生成坐标预测。对于集成到AI代理系统中的情况,通常将Gelato作为 grounding 模块,与规划模型(如GPT-5)配合使用,由规划模型决定高级动作序列,由Gelato将这些动作解析为具体操作。
Gelato模型的准确率是否足够用于实际应用?
尽管Gelato在基准测试中的准确率在60%-75%之间,这在GUI grounding这一极具挑战性的任务中已经代表了当前最先进的水平。在实际应用中,可以通过多种策略提高整体系统的可靠性,例如结合多种验证机制、设置回退策略,或者在关键任务中引入人工审核环节。随着技术的不断发展,这一准确率预计会继续提升。
Gelato模型可以处理哪些类型的应用程序?
Gelato在训练过程中接触了多种类型的应用程序数据,包括网络浏览器、办公软件、系统工具等。通过包含专业应用程序教程数据,它也获得了一定的专业软件操作能力。然而,对于极其 specialized 或新出现的应用程序,可能需要进行额外的微调或使用领域特定的数据增强。
模型输出的坐标格式是怎样的?
Gelato模型输出的坐标是归一化后的值,范围在0到1000之间。在实际使用中,需要根据屏幕或图像的实际尺寸将这些归一化坐标转换为绝对坐标。例如,对于宽度为1920像素的图像,x坐标500对应的是960像素(500/1000 * 1920)。
结语
Gelato-30B-A3B代表了GUI grounding技术的一个重要进步。通过结合高质量的数据集、精心设计的模型架构和有效的训练方法,它在图形用户界面元素定位任务上设定了新的标准。
这一技术的发展不仅推动了AI代理能力的边界,也为未来更加智能和自主的计算机使用系统奠定了基础。随着开源社区的参与和进一步的研究改进,我们可以期待看到更多基于这类技术的实用应用出现,真正改变我们与计算机交互的方式。
对于AI研究者和开发者来说,Gelato-30B-A3B提供了一个强大的工具,可以用于构建更加智能和可靠的自动化解决方案,推动AI技术在日常生活和工作中的实际应用。

