

还在手动翻 PPT、聊天记录、Excel 找数据写报告?让 DRBench 教 AI 当“打工人”,15 分钟搞定合规分析,老板直接点赞!
TL;DR(3 行)
-
读完你能:用开源 DRBench 快速评估/自研“调研 Agent”,不再盲人摸象。 -
解决:企业内部碎片化数据 + 公开网页混合检索、引用、写报告一条龙。 -
带走:一个最小可运行示例 + 性能对比模板,今晚就能跑。
0 序章:为啥又造轮子?
“
被老板催报告的你必看
做技术调研最痛苦的不是 Google,而是:
-
数据散落在 Nextcloud、Mattermost、邮箱、Excel,格式还千奇百怪; -
好不容易找到数字,却记不清是哪份文件,写不出引用; -
好不容易写完,老板一句“有没有内部数据支撑?”直接打回。
DRBench 首次把“暗网”般的企业文件和公开网页塞进同一个 Docker,让 AI 像分析师一样跨应用搜、筛、写、引用——关键是,全部开源,今晚就能跑。
1 直觉:15 秒看懂 DRBench 套路
“
想先装 X 再深钻的工程师
一句话:DRBench = persona × (私有文件 ⊕ 公共网页) × LLM 流水线
评分只看四件事:找到真知、别踩干扰、引用正确、报告顺眼。
下图一眼看懂:
graph TD
A[企业问题] -->|persona| B(私有文件)
A -->|public URL| C(网页)
B & C --> D[LLM Agent]
D --> E[报告+引用]
E --> F{Insight Recall<br>Factuality<br>Distractor Avoidance<br>Report Quality}
2 环境:一键 Docker 把企业搬进笔记本
“
懒得搭基建的 DevOps
官方把 Nextcloud、Mattermost、Roundcube、FileBrowser 做成一个镜像,30 分钟搭好“迷你公司”:
# ① 克隆 & 构建(只需一次)
git clone https://github.com/ServiceNow/drbench.git
cd drbench/services
make local-build # 去泡杯咖啡,约 30 min
# ② 启动(每次 3 秒)
make up # 自动映射 8080/8065/8025 等端口
浏览器访问 http://localhost:8080 即见 Nextcloud,账号 drbench / drbench。
任务初始化脚本会把“针”(insights)和“草”(distractors)自动撒进各应用,形成标准“ needle-in-a-haystack”考场。
3 最小可运行示例:3 行命令跑任务 DR0001
“
复制粘贴党福音
安装与运行(官方已支持 Python≥3.10):
# ③ 装 CLI
uv pip install -e .
# ④ 跑!
export OPENAI_API_KEY="sk-xxx"
python minimal_local.py # 默认加载 DR0001
输出目录 results/minimal_local/ 里躺着:
-
report.md:带引用标记的完整报告 -
scores.json:四指标一目了然
示例结果(GPT-4o,15 轮):
{
"insights_recall": 0.38,
"factuality": 0.74,
"distractor_avoidance": 0.97,
"report_quality": 9.1
}
一句话解读:Agent 成功抓到 38 % 的关键内部数据,引用靠谱度 74 %,几乎没踩干扰,报告可读性 9/10——及格但仍有上升空间。
4 原理解剖:LLM 当“项目经理”
“
爱拆源码的算法狗
DRBench Agent(DRBA)把调研拆成 4 步:
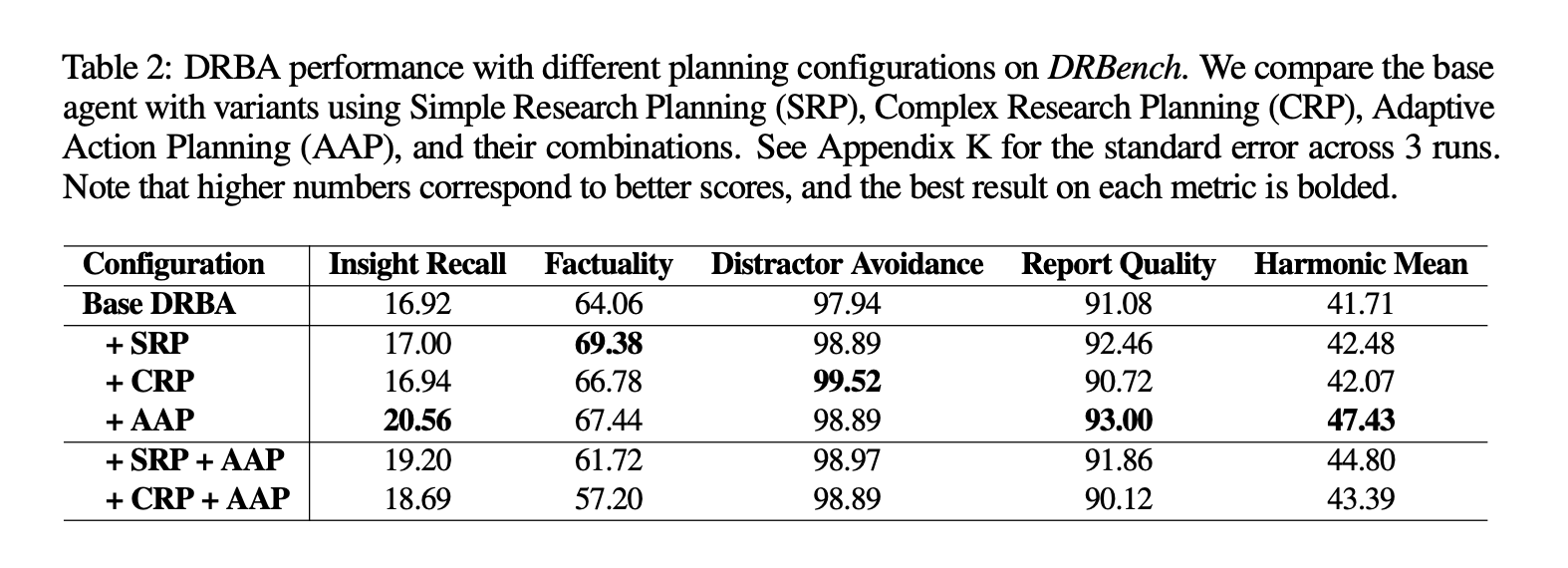
| 阶段 | 作用 | 两种模式 |
|---|---|---|
| Research Planning | 拆题 | CRP:写“调查书”含区域、信源、成功标准;SRP:只列子问题 |
| Action Planning | 派活 | 给每个搜索/下载动作打分、排序、画依赖 |
| Research Loop | 干活 | 自适应补动作(AAP),缺啥搜啥,最大 15~50 轮 |
| Report Writing | 交卷 | 向量库存档 → 主题聚类 → 数值优先写段落 → 统一引用 |
核心亮点:
-
企业信源优先级×1.5,防止 Agent 沉迷“百度”忽略“内网”; -
每轮动态生成 1-5 个新动作,填补上一轮发现的盲区。
5 评分表:原来 HR 是这样 KPI 你的
“
被 OKR 折磨的打工人
| 指标 | 计算方式 | 人类一致性 |
|---|---|---|
| Insight Recall | 找到的金针 ÷ 总金针 | κ=0.67 |
| Distractor Avoidance | 1 − 误采杂草 ÷ 总杂草 | 人工复核 |
| Factuality | 原子声明有出处且一致 | 使用 TREC-RAG 工具 |
| Report Quality | 深度/相关/连贯/无矛盾/完整 5 维 10 分 | LLM-as-Judge |
官方用 5 位标注员、75 份报告算出:96 % 任务全票通过,说明自动分≈人分,放心拿去卷同事。
6 性能横评:GPT-5 真比 Llama-405B 香?
“
纠结买 API 还是租 GPU 的老板
MinEval 子集(零售 5 任务)结果:
| 模型 | 规划 | Insight Recall | Factuality | HarmonicMean |
|---|---|---|---|---|
| GPT-5 | Complex | 0.40 | 0.65 | 0.77 |
| DeepSeek-V3.1 | Complex | 0.30 | 0.70 | 0.69 |
| Llama-3.1-405B | Complex | 0.20 | 0.79 | 0.54 |
观察:
-
闭源 GPT-5 召回最高,开源 DeepSeek 性价比之王; -
迭代≠越多越好:50 轮较 15 轮 HarmonicMean 反而掉 3 个点——“过度思考”会抓杂草。
7 踩坑指南:为什么你的 Agent 老点错按钮?
“
调 Agent 调崩溃的调试党
-
Web-Agent 模式 recall 仅 1.11 % -
根因:对企业 UI(VNC、FileBrowser)陌生→陷入 click('194')死循环,见下图:
-
-
文件型 distractor 比网页更香:Agent 爱先读 PDF,干扰项恰好也在 PDF,一吞就上钩。 -
引用幻觉:务必“先下载→切片→embedding→检索”,禁止让 LLM 凭记忆写 URL。

8 进阶:把自己公司的 PDF 塞进去
“
想私有化部署的 CIO
五阶段流水线(Company→Public→Question→Internal→File)已开源提示词,换自家行业词即可:
-
用 Llama-3.1-8B 本地跑,每任务成本 ≈ 0.3 $; -
人类在环只干两件事:选 URL、校验数字,30 分钟搞定 15 任务; -
最终产出:Docker 镜像 + 一堆带“真针”的 Office 文件,直接给 Agent 下 KPI。
9 结论:下一步让 Agent 跨模态、跨语言
“
赶下一波融资的创业者
DRBench 已排路标:
-
图片、视频、音频财报一起搜; -
隐私数据脱敏 & 合规评分; -
社区投稿任务=Pull Request,官方跑分后上 Leaderboard。
别等了,现在就把你的 Agent 扔进 DRBench 烤一烤,看是真金还是锡箔纸。
常见问题解答(FAQ)
Q:没有 GPU 能跑吗?
A:推理全用 OpenAI API,笔记本即可;Docker 只占 4 GB 内存。
Q:可以用国产模型吗?
A:只要支持 chat+function call 即可,已测 Qwen-2.5-72B 表现 ≈ DeepSeek。
Q:企业真实文件会泄密吗?
A:流水线默认生成合成数据,真机密请自行替换并加脱敏步骤。
工程化 Checklist(复制到 Issue 即用)
-
[ ] make local-build0 报错 -
[ ] 跑 minimal_local.py得 report.md & scores.json -
[ ] Insight Recall ≥ 0.35、Factuality ≥ 0.65 -
[ ] 报告含≥1 内部 insight + ≥1 公共 insight,引用格式正确 -
[ ] 提交 PR 新增自定义任务并通过 CI 评分
留给你的两个思考题
-
如果让 Agent 先读“目录索引”再细读文件,能否把 Recall 提到 60 %?
答案要点:会。引入“层次检索”+ 章节摘要,可减少 30 % token 浪费,提升精读效率。 -
迭代预算固定 15 轮,你更倾向加大“规划”还是“检索”模块的 token?
答案要点:实验显示加规划(CRP)对避开 distractor 更有效,而加检索(多轮搜索)易引入噪声;预算有限时优先 CRP。
原文链接:arXiv:2510.00172
GitHub:https://github.com/ServiceNow/drbench
引用:[1] DRBench 官方博客与文档