Chain-of-Agents:让AI像团队一样协作完成任务的新范式

引言:当AI学会”团队协作”
想象你正在策划一场大型活动,需要同时处理场地预订、餐饮安排、嘉宾邀请等多项任务。如果让一个人独自完成所有工作,效率可能很低;但如果组建一个团队,每个成员负责不同领域,协同工作就能事半功倍。
最近,AI领域也出现了类似的”团队协作”突破。在2025年8月20日发布的论文中,OPPO AI团队提出了名为**Chain-of-Agents(CoA)**的新框架,让单个AI模型能像多智能体系统一样动态任务分解、工具调用和协作推理,在复杂任务中表现远超传统方法。
本文将用通俗易懂的方式,为您解析这个可能改变未来AI工作方式的重要技术。
一、现有AI系统的”痛点”
1.1 传统方法的局限性
目前主流的AI系统主要存在三大问题:
| 痛点 | 传统TIR方法 | 多智能体系统 |
|---|---|---|
| 计算效率 | 低(重复通信) | 高(需要复杂流程设计) |
| 通用性 | 固定流程难扩展 | 需要大量重新配置 |
| 学习能力 | 难以通过数据优化 | 无法直接训练提升 |
就像一个只能按固定流程操作的机器人 vs 需要大量人工调度的团队。
1.2 一个典型案例
假设要回答”2024年AI领域有哪些突破?”这个问题:
-
传统TIR方法:像流水线工人一样按固定步骤执行
-
调用搜索工具找信息 -
分析搜索结果 -
生成回答
-
-
多智能体系统:像分工明确的团队
-
规划员分解任务 -
搜索员收集信息 -
分析师整理数据 -
总结员撰写回答
-
但传统多智能体系统需要复杂的流程设计,且各”队员”之间沟通成本高。
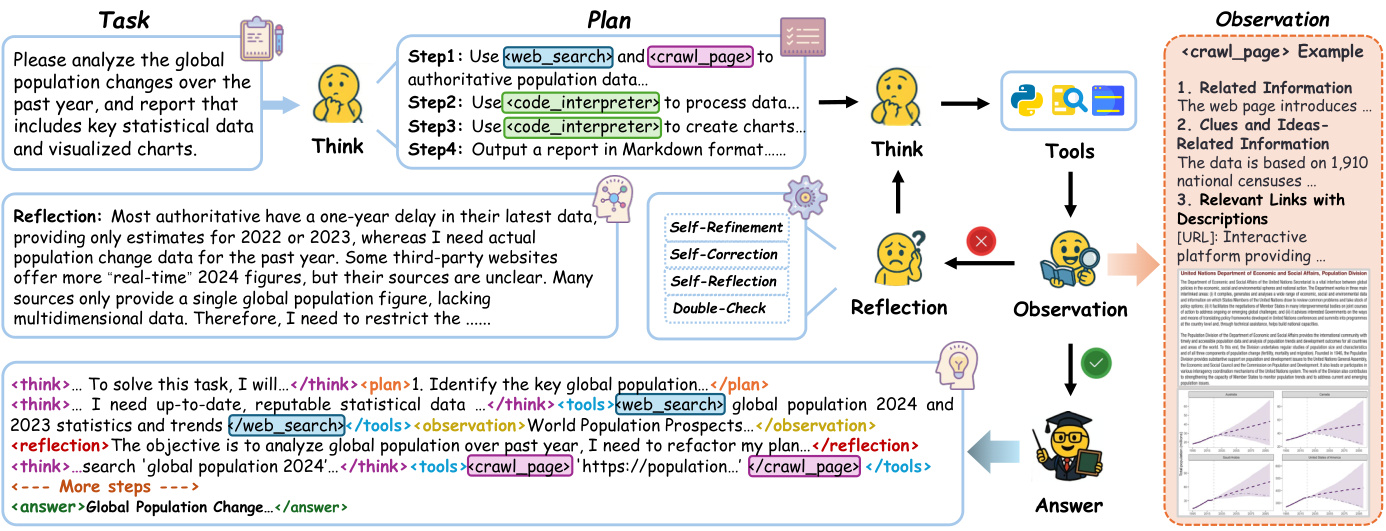
二、CoA框架:让AI学会”动态组队”
2.1 核心思想
CoA框架的核心创新在于:让单个AI模型能像指挥家一样动态调用不同”智能体”。

就像一个经验丰富的项目经理,可以根据任务需要实时组建团队:
-
需要搜索信息时,调用”搜索员” -
需要代码编写时,调用”程序员” -
需要验证结果时,调用”质检员”
2.2 两大核心组件
CoA框架包含两种关键”角色”:
A. 角色扮演智能体(高管团队)
-
思考智能体:全局协调,激活专业智能体 -
规划智能体:分解任务为可执行步骤 -
反思智能体:自我批判,修正错误 -
验证智能体:检查推理完整性
B. 工具智能体(专业团队)
-
搜索智能体:生成优化查询,优先处理可靠来源 -
爬取智能体:并行内容提取,解析技术细节 -
代码生成智能体:在沙盒环境生成并执行代码
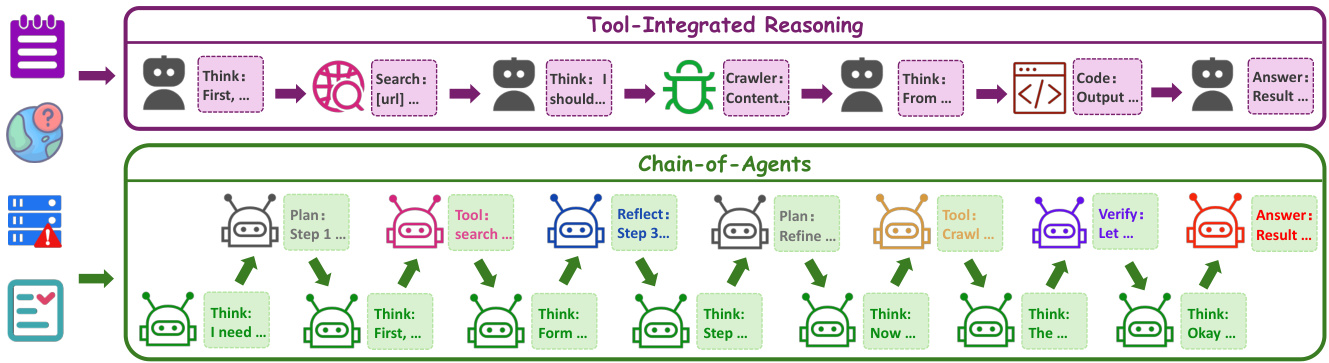
2.3 工作原理
与传统”思考-行动-观察”(ReAct)循环不同,CoA的工作流程更像是动态团队协作:
当前状态 → 激活专业智能体 → 执行任务 → 更新状态 → 重复
就像项目经理根据项目进展,实时调整团队成员的工作重点。
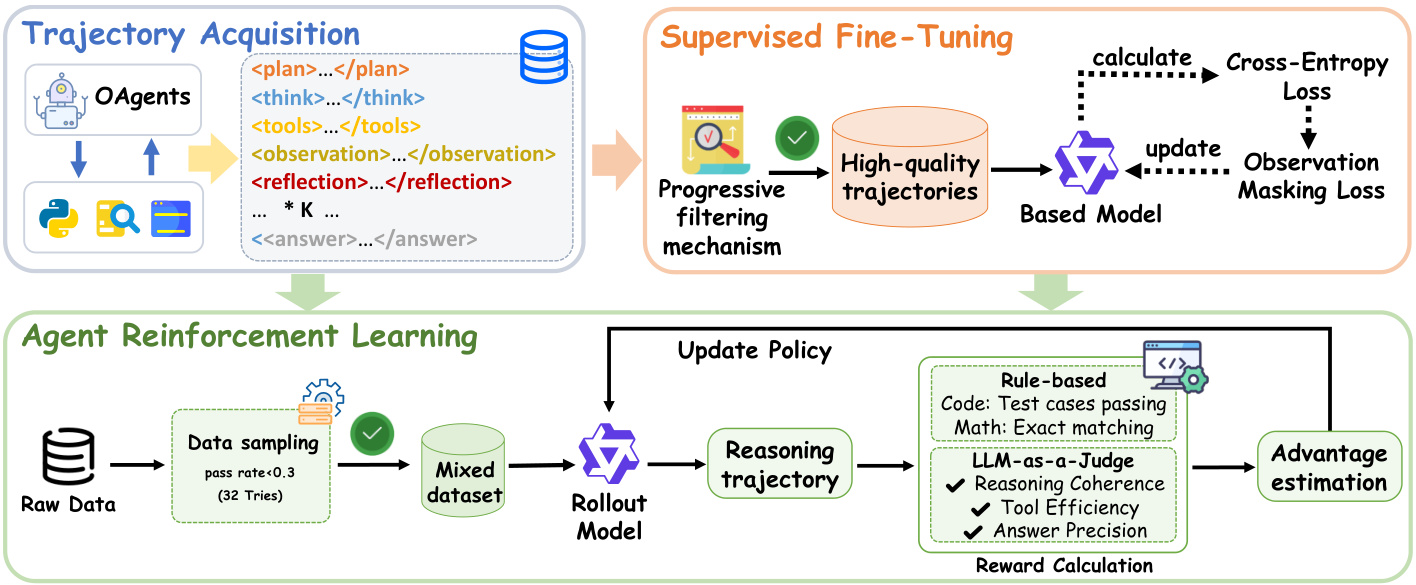
三、如何训练这样的”AI团队”?
3.1 多智能体知识蒸馏
核心思路:从现有优秀的多智能体系统中提取”协作模式”,教给单个AI模型。
就像:
-
录制优秀团队的工作过程 -
分析每个决策点(谁在什么情况下做了什么) -
将这些模式转化为训练数据 -
用这些数据训练新模型
3.2 渐进式质量过滤
研究团队设计了四层过滤机制,确保训练数据的质量:
-
复杂度过滤:排除交互少于5次的简单任务 -
质量过滤:移除错误答案、冗余操作等”脏数据” -
反思增强:优先保留包含自反思机制的轨迹 -
错误修正轨迹上采样:对通过迭代修正最终正确的样本进行加权
3.3 基于代理的强化学习
在监督训练基础上,进一步通过强化学习优化模型:
Web Agent奖励函数:
-
关注最终答案正确性(通过LLM作为裁判评分) -
不需要格式验证奖励(前期训练已保证)
Code Agent奖励函数:
-
同时考虑答案正确性和格式正确性 -
代码任务需通过沙盒环境所有测试用例
四、实验结果:性能显著提升
4.1 多跳问答(MHQA)基准测试
在7个数据集上的平均准确率:
| 模型 | 3B参数 | 7B参数 |
|---|---|---|
| AFM-SFT | 39.7% | 41.7% |
| AFM-RL | 41.3% | 45.5% |
关键发现:即使只在NQ和HotpotQA上训练,模型在其他未见数据集上表现依然出色,体现了强大的泛化能力。
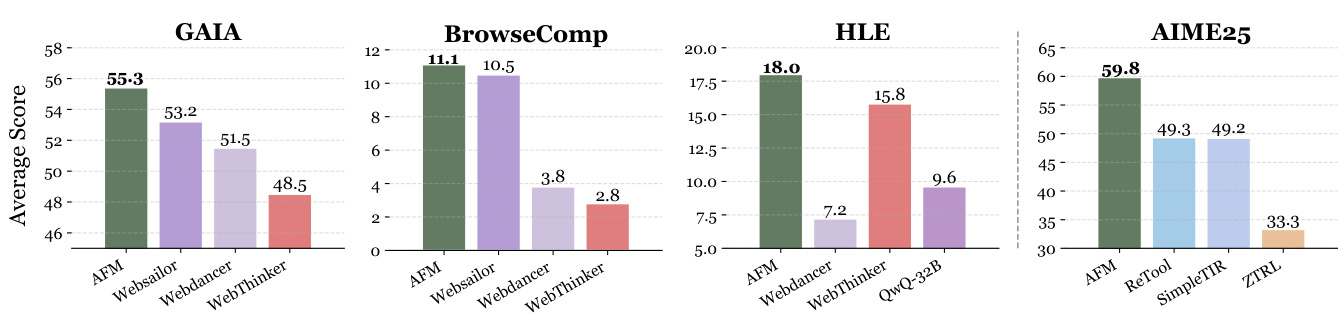
4.2 复杂网络任务基准
在GAIA、BrowseComp、HLE等 benchmark上:
| 基准 | AFM表现 | 对比提升 |
|---|---|---|
| GAIA | 55.3% | +2.1%超过WebSailor |
| BrowseComp | 11.1% | 32B模型新SOTA |
| HLE | 18.0% | 超越WebThinker-RL |

4.3 代码智能体实验
在LiveCodeBench v5和CodeContests上的Pass@1准确率:
| 模型 | LiveCodeBench v5 | CodeContests |
|---|---|---|
| AFM-RL-32B | 47.9% | 32.7% |
| ReTool-32B | 23.4% | 10.3% |
| Reveal-32B | 42.4% | – |
五、深入分析:为何CoA更高效?
5.1 计算效率
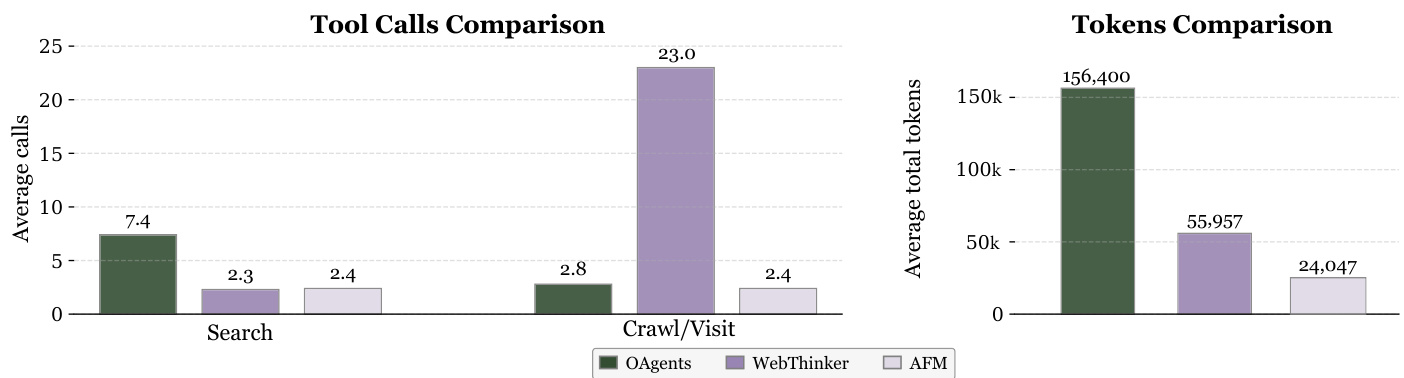
与OAgents、WebThinker等方法相比:
| 指标 | AFM优势 |
|---|---|
| 工具调用次数 | 最少 |
| 令牌消耗 | 最低(减少84.6%) |
| 推理延迟 | 明显改善 |

5.2 未见智能体泛化
有趣发现:
-
代码智能体模型可以正确调用未训练过的Web搜索工具 -
Web智能体模型尝试调用Python执行器时频繁失败
这说明:
-
严格格式训练(如代码)能提升工具调用的鲁棒性 -
动态协作能力在不同任务间存在差异
5.3 测试时扩展
增加候选答案数量(Pass@3)能显著提升性能:
| 基准 | AFM | AFM-Pass@3 |
|---|---|---|
| GAIA | 55.3 | 69.9 (+14.6) |
| HLE | 18.0 | 33.2 (+15.2) |
六、相关工作
6.1 多智能体系统
传统多智能体系统(如OAgents)面临:
-
智能体间通信成本高 -
缺乏全局状态表示 -
难以端到端训练
6.2 工具集成推理
从CoT到TIR的发展:
-
CoT:适合内部知识推理 -
TIR:引入外部工具调用 -
现有方法:静态模板或单工具优化
6.3 推理强化学习
现有RL方法局限:
-
缺乏多工具协同机制 -
多步序列奖励稀疏
七、总结
CoA框架通过将多智能体协作能力嵌入单个模型,实现了:
-
高效协作:动态调用专业智能体,减少通信成本 -
强大泛化:跨领域任务表现优异 -
端到端优化:支持监督训练和强化学习
未来展望:随着AI系统越来越复杂,像CoA这样的”团队协作”框架可能会成为主流,让AI能像人类团队一样高效处理复杂任务。
八、常见问题(FAQ)
Q: CoA框架与现有TIR方法的主要区别是什么?
A: 传统TIR像固定流程的工人,CoA像能动态组队的团队,可根据任务需要灵活调用不同”专业智能体”。
Q: AFM模型在哪些任务上表现最好?
A: 在需要多工具协作的任务(如GAIA基准)和数学推理任务(如AIME25)上提升最显著。
Q: 该技术何时会应用到实际产品中?
A: 论文已开源模型权重、训练代码和数据集,为未来研究奠定基础,但具体产品化时间表尚未公布。
Q: 普通开发者如何体验CoA框架?
A: 可访问项目开源地址:https://github.com/OPPO-AI/Chain-of-Agents 获取模型和代码。