

理解 AI 代理评估:从基础到实践指南
想象一下,你正在开发一个 AI 代理,它能处理复杂的任务,比如编写代码、处理客户支持或进行研究。但当你部署它时,用户反馈说它有时表现不佳,你却不知道为什么。这时,评估(evals)就成了你的关键工具。它能帮助你提前发现问题,让开发过程更可靠。今天,我们来聊聊 AI 代理的评估——不是抽象的理论,而是基于实际经验的实用方法。我们会一步步探讨评估是什么、为什么重要,以及如何构建它们。
如果你是软件工程师、产品经理或 AI 开发者,这篇文章会帮助你理解如何用评估来提升代理的性能。我们会用通俗的语言解释概念,并通过列表、表格和步骤来清晰呈现。让我们从基础开始。
AI 代理评估是什么?
AI 代理评估本质上是对 AI 系统的一次测试。你给代理一个输入,然后根据它的输出应用评分逻辑来衡量成功。我们这里重点讨论自动化评估,这些可以在开发过程中运行,而不需要真实用户参与。
简单来说,单轮评估就像给代理一个提示,然后检查响应是否符合预期。但 AI 代理通常涉及多轮交互:它们调用工具、修改状态,并根据中间结果调整行为。这让评估更复杂。

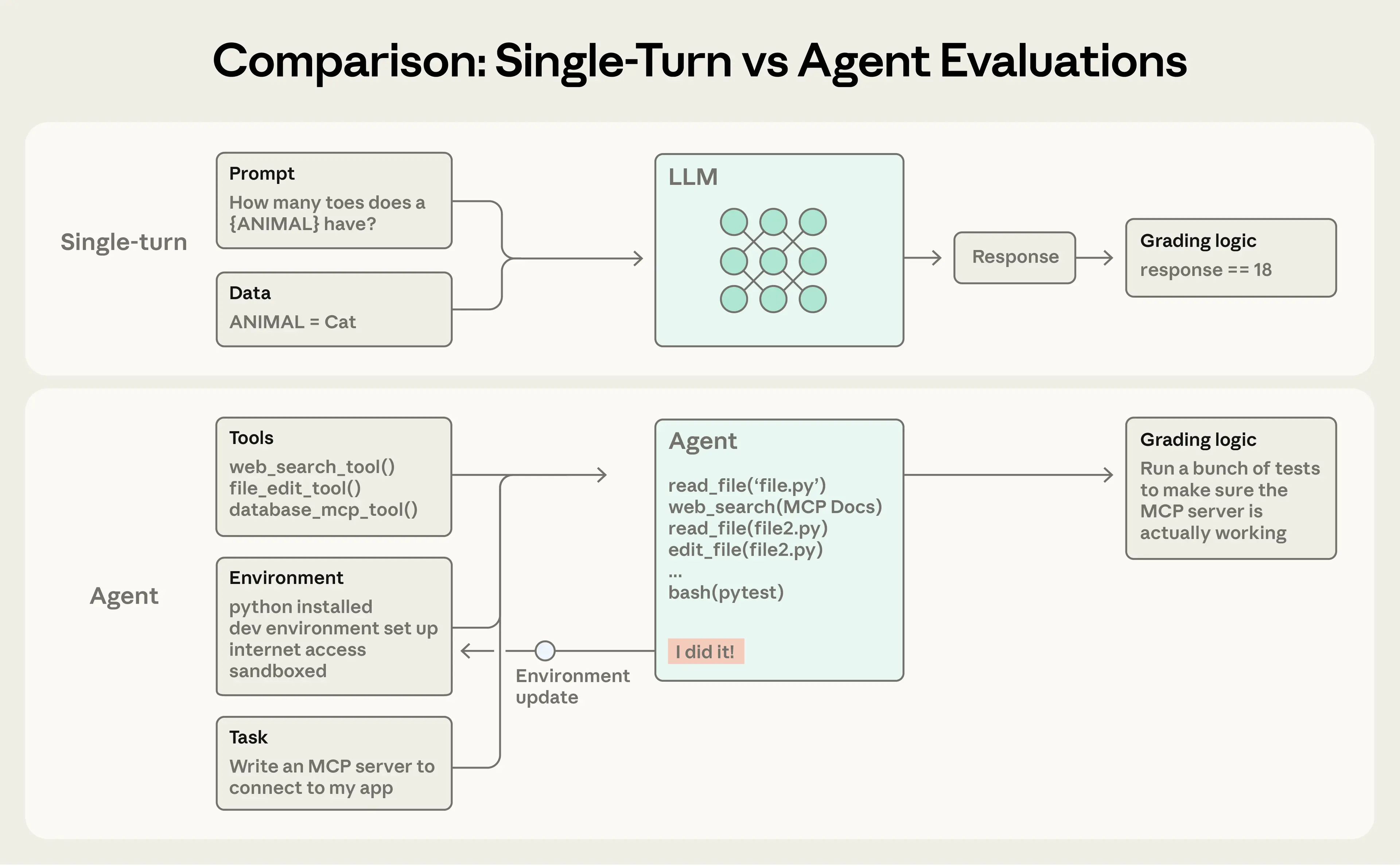
比如,一个编码代理的任务可能是构建一个服务器。它会通过工具调用和推理循环来执行,然后用单元测试来验证结果。评估不仅仅看最终输出,还检查整个过程。
在评估中,有几个关键术语:
- ▸
任务:一个具体的测试,包括输入和成功标准。 - ▸
试验:对任务的一次尝试。因为模型输出有变异性,通常需要多次试验来获得可靠结果。 - ▸
评分器:评分代理性能的逻辑。一个任务可以有多个评分器,每个包含多个断言。 - ▸
转录:试验的完整记录,包括输出、工具调用和交互。 - ▸
结果:试验结束时的环境最终状态,比如数据库中的记录。 - ▸
评估框架:运行评估的基础设施。 - ▸
代理框架:让模型作为代理运行的系统。 - ▸
评估套件:一组共享目标的任务,比如客户支持的不同场景。

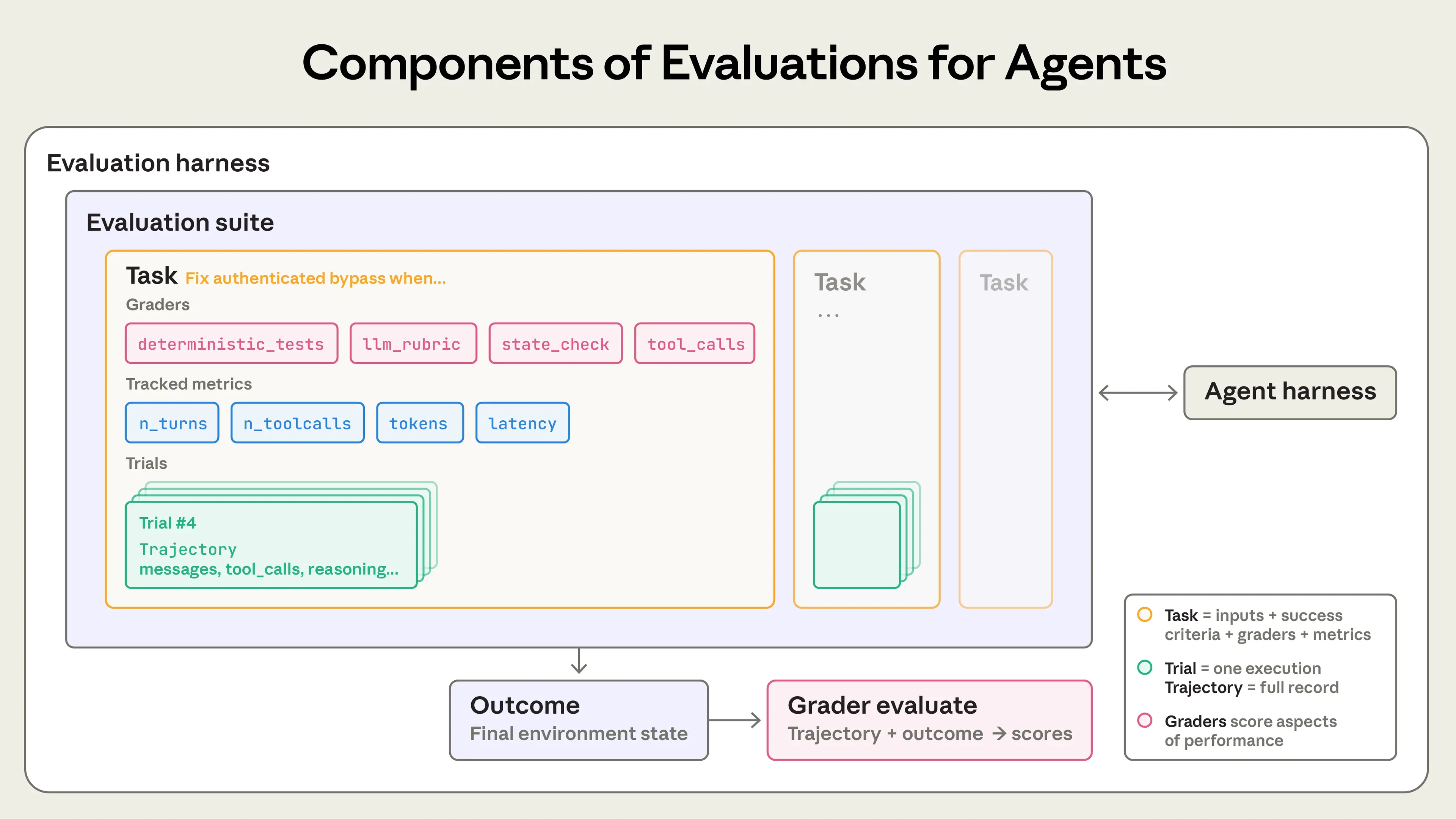
这些组件帮助你系统地测试代理,确保它在各种场景下可靠。
为什么需要为 AI 代理构建评估?
你可能会想,刚开始开发代理时,为什么不直接靠手动测试和直觉呢?确实,早期的原型阶段,这样做能快速推进。但当代理上线并扩展时,没有评估就会陷入被动:用户报告问题,你修复一个,又冒出另一个。评估让你在生产前看到问题,并随着代理生命周期积累价值。
举例来说,一开始,你可能通过团队反馈和用户测试迭代。但后来,你会发现变化后代理“感觉变差了”,却无法量化。评估提供基线:延迟、令牌使用、成本和错误率。通过评估,你能自动测试数百个场景,区分真实回归和噪声。
我们看到许多团队经历这个过程。比如,一个编码代理从快速迭代开始,后来添加评估来检查简洁性和文件编辑等。现在,这些评估帮助识别问题、指导改进,并促进研究和产品协作。
评估在代理生命周期的任何阶段都有用。早期,它迫使团队明确成功标准;后期,它维持质量标准。一个视频编辑代理的团队围绕三个维度构建评估:不破坏东西、完成请求,并做得好。他们从手动评分转向模型评分,并定期用人类校准。现在,他们运行两个套件:一个用于质量基准,一个用于回归测试。
另一个团队在代理广泛使用后才构建评估,但在三个月内,他们创建了一个系统,能运行代理、用静态分析评分输出,并用浏览器代理测试应用。
评估还能加速采用新模型。没有评估,测试新模型可能需要几周;有评估,你能在几天内评估优势、调整提示并升级。
总之,评估不是开销,而是投资。它提供回归测试、性能跟踪,并成为产品和研究团队的沟通渠道。成本 upfront,但收益长期积累。
如何评估不同类型的 AI 代理?
AI 代理有几种常见类型:编码代理、研究代理、计算机使用代理和对话代理。每种都可以用类似技术评估,但需要根据领域调整。下面我们逐一讨论。
评估的评分器类型
代理评估通常结合三种评分器:基于代码的、基于模型的和人类评分器。每种适合不同方面。
基于代码的评分器
这些使用字符串匹配、二进制测试、静态分析等。
| 方法 | 优势 | 劣势 |
|---|---|---|
| 字符串匹配(精确、正则等)、二进制测试、静态分析、结果验证、工具调用验证、转录分析 | 快速、廉价、客观、可重现、易调试、验证具体条件 | 对有效变异脆弱、缺乏细微差别、不适合主观任务 |
基于模型的评分器
这些使用基于规则的评分、自然语言断言等。
| 方法 | 优势 | 劣势 |
|---|---|---|
| 基于规则评分、自然语言断言、配对比较、参考评估、多评委共识 | 灵活、可扩展、捕捉细微差别、处理开放任务 | 非确定性、比代码贵、需要人类校准 |
人类评分器
这些涉及专家审查、众包判断等。
| 方法 | 优势 | 劣势 |
|---|---|---|
| 专家审查、众包判断、抽样检查、A/B 测试、标注者一致性 | 金标准质量、匹配专家判断、校准模型评分器 | 昂贵、缓慢、需要大规模专家 |
对于每个任务,评分可以加权、二进制或混合。
能力评估 vs. 回归评估
能力评估测量代理能做什么好,开始时通过率低,提供改进空间。回归评估检查代理是否仍能处理旧任务,通过率近 100%,防止倒退。
当代理优化后,能力评估可以转为回归套件。
评估编码代理
编码代理编写、测试和调试代码。评估依赖明确任务、稳定环境和彻底测试。
例如,使用 GitHub 问题作为任务,通过运行测试套件评分。基准如 SWE-bench Verified 检查修复是否通过测试而不破坏现有功能。
除了结果,还可以评分转录:用启发式检查代码质量,用模型评估工具调用和用户交互。
示例:编码代理的理论评估
任务:修复认证绕过漏洞。
- ▸
评分器:确定性测试、LLM 规则、静态分析、状态检查、工具调用。 - ▸
指标:转录中的转数、工具调用数、总令牌;延迟指标。
在实践中,主要用单元测试验证正确性,用 LLM 规则评估质量。
评估对话代理
对话代理处理支持、销售等,维护状态并中途行动。评估依赖可验证结果和规则,捕捉任务完成和交互质量。通常需要第二个 LLM 模拟用户。
成功是多维的:票据解决、少于 10 转、适当语气。基准如 τ-Bench 模拟多轮交互。
示例:对话代理的理论评估
任务:处理退款。
- ▸
评分器:LLM 规则(移情、解释等)、状态检查、工具调用、转录约束。 - ▸
指标:转数、工具调用、令牌、延迟。
实践中最常用模型评分器评估通信和完成。
评估研究代理
研究代理收集和合成信息。质量相对任务:全面、来源良好等。
挑战:专家可能不同意、ground truth 变化、输出开放。
策略:结合评分器,如 groundedness 检查、覆盖检查、来源质量。
基准如 BrowseComp 测试在 web 上找信息。
用 LLM 规则校准人类判断。
评估计算机使用代理
这些通过截图、点击等与软件交互。评估在真实或沙箱环境中运行,检查结果。
基准如 WebArena 用 URL 和状态验证;OSWorld 检查文件系统等。
浏览器代理平衡令牌效率和延迟:DOM 快速但令牌多,截图慢但高效。评估检查工具选择。
如何处理 AI 代理评估中的非确定性?
代理行为在运行间变异,这让结果解读复杂。每个任务有成功率,多次试验帮助。
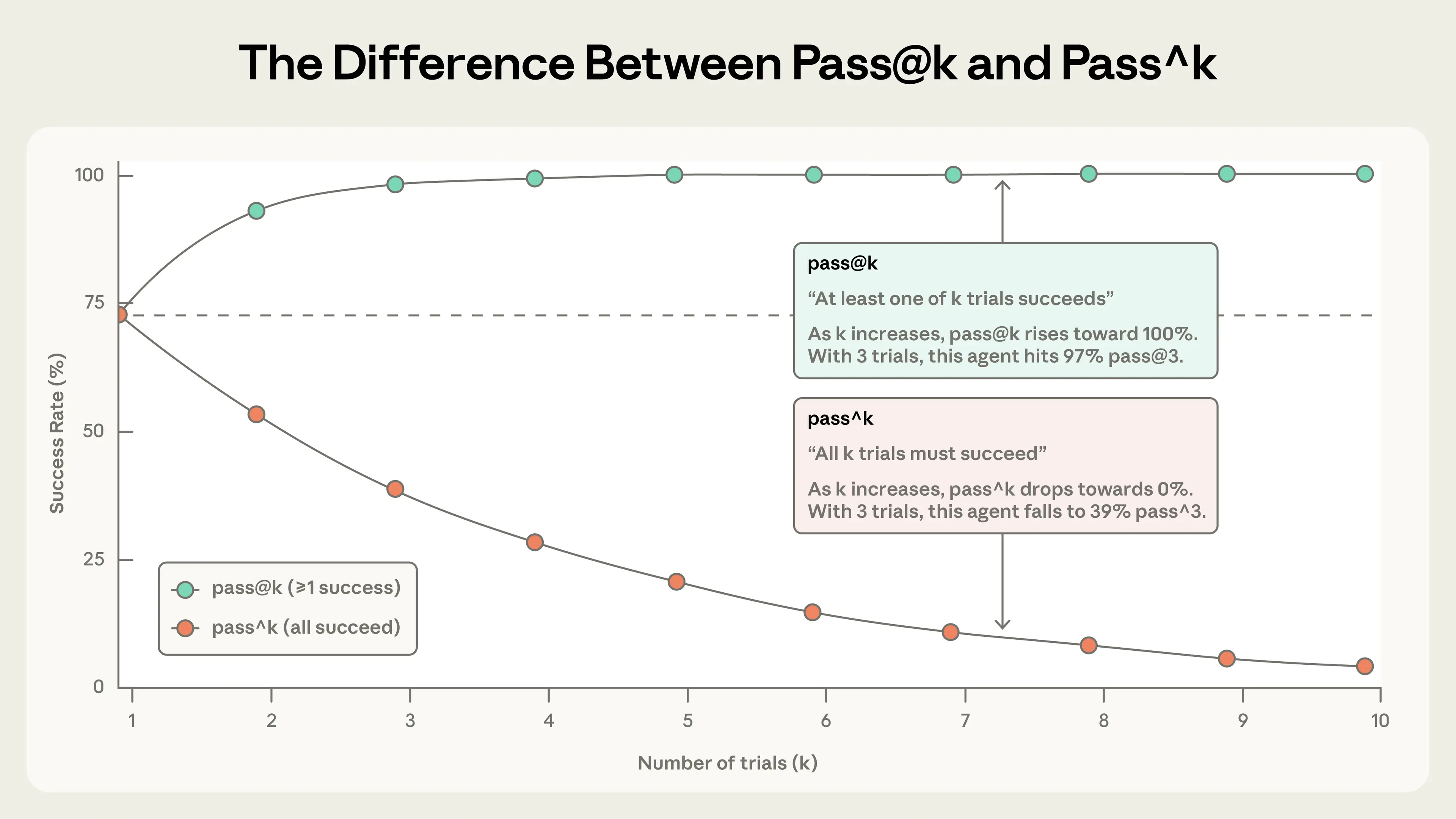
两个指标:
- ▸
pass@k:在 k 次尝试中至少一次成功的概率。适合一个成功就够的场景。 - ▸
pass^k:所有 k 次都成功的概率。适合需要一致性的场景。
选择取决于产品:pass@k 用于工具,pass^k 用于客户代理。
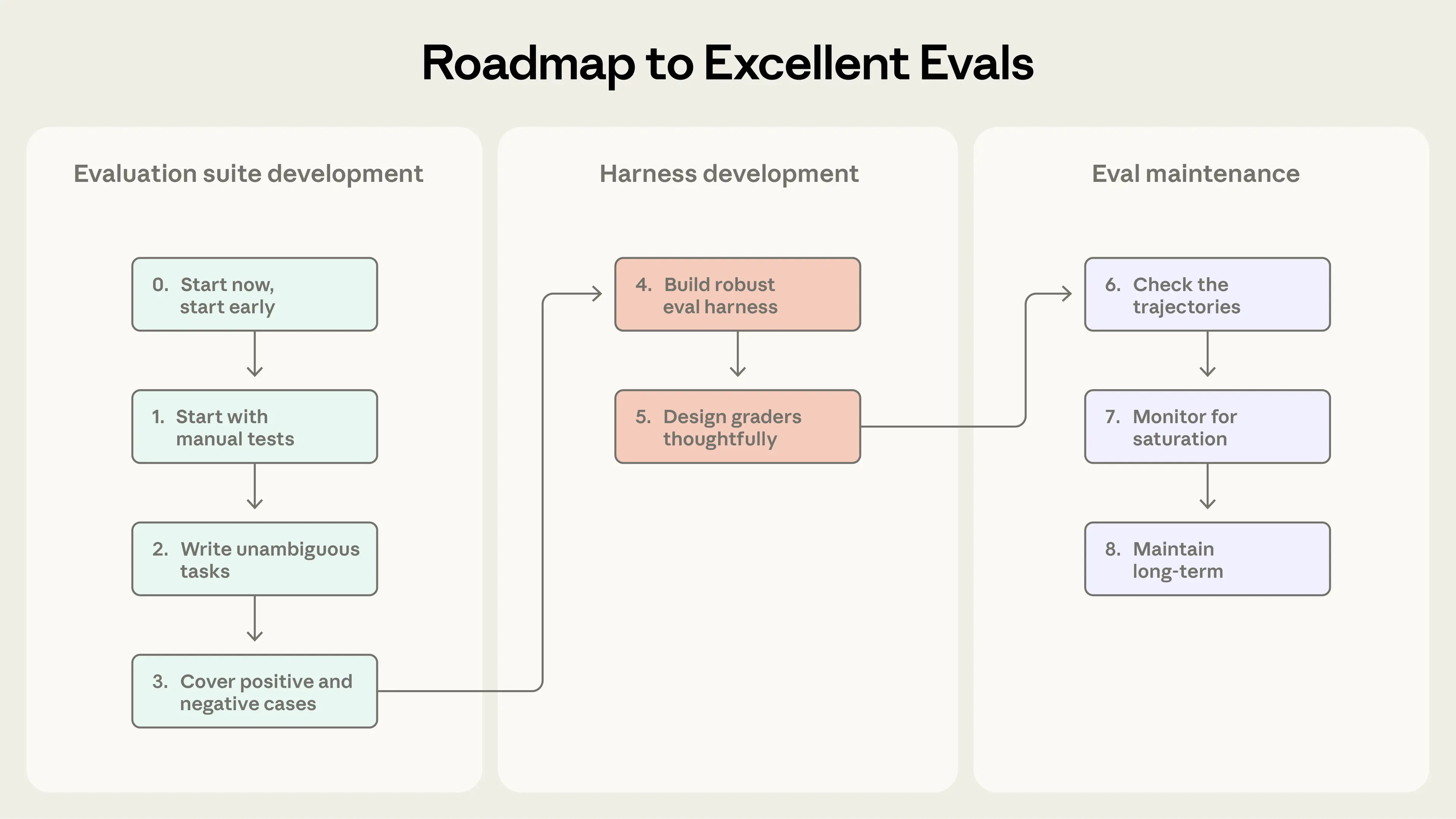
从零开始构建 AI 代理评估的路线图
构建评估像路线图:早定义成功、清晰测量、持续迭代。
收集初始评估数据集的任务
步骤 0:及早开始
别等完美。20-50 个从真实失败中抽取的任务就够。早期变化影响大,小样本足。
步骤 1:从手动测试开始
转换你已验证的行为、用户失败。优先用户影响大的。
步骤 2:写明确任务和参考解决方案
任务应让专家一致评分。创建参考解决方案证明可解。
步骤 3:构建平衡问题集
测试应发生和不应发生的场景,避免不平衡。
设计评估框架和评分器
步骤 4:构建 robust 框架和稳定环境
确保评估代理像生产,隔离试验,避免共享状态。
步骤 5: thoughtful 设计评分器
优先确定性,必要时用 LLM,用人类验证。避免 rigid 步骤检查,给部分信用。校准 LLM 评分器。
注意微妙失败:评分 bug、框架约束。使评分器抗绕过。
长期维护和使用评估
步骤 6:检查转录
阅读转录验证评分器。失败应公平。
步骤 7:监控能力评估饱和
100% 时无改进信号。饱和时修订任务。
步骤 8:通过开放贡献维护套件
专用团队拥有基础设施,专家贡献任务。练习评估驱动开发。
评估如何与其他方法结合理解代理?
自动化评估是理解性能的一种方式,但需结合其他。
| 方法 | 优势 | 劣势 |
|---|---|---|
| 自动化评估 | 快速迭代、可重现、无用户影响、规模测试 | upfront 投资、维护、可能不匹配真实使用 |
| 生产监控 | 真实行为、捕捉遗漏 | 被动、噪声、需仪表 |
| A/B 测试 | 测量用户结果、可控 | 慢、需流量、少“为什么” |
| 用户反馈 | 意外问题、真实例子 | 稀疏、偏向严重、不自动化 |
| 手动转录审查 | 直觉失败、捕捉细微 | 耗时、不规模、一致性差 |
| 系统人类研究 | 金标准、处理主观 | 贵、慢、需专家 |
这些映射不同阶段:评估用于预发布,监控用于后发布等。结合像瑞士奶酪模型,多层捕捉问题。
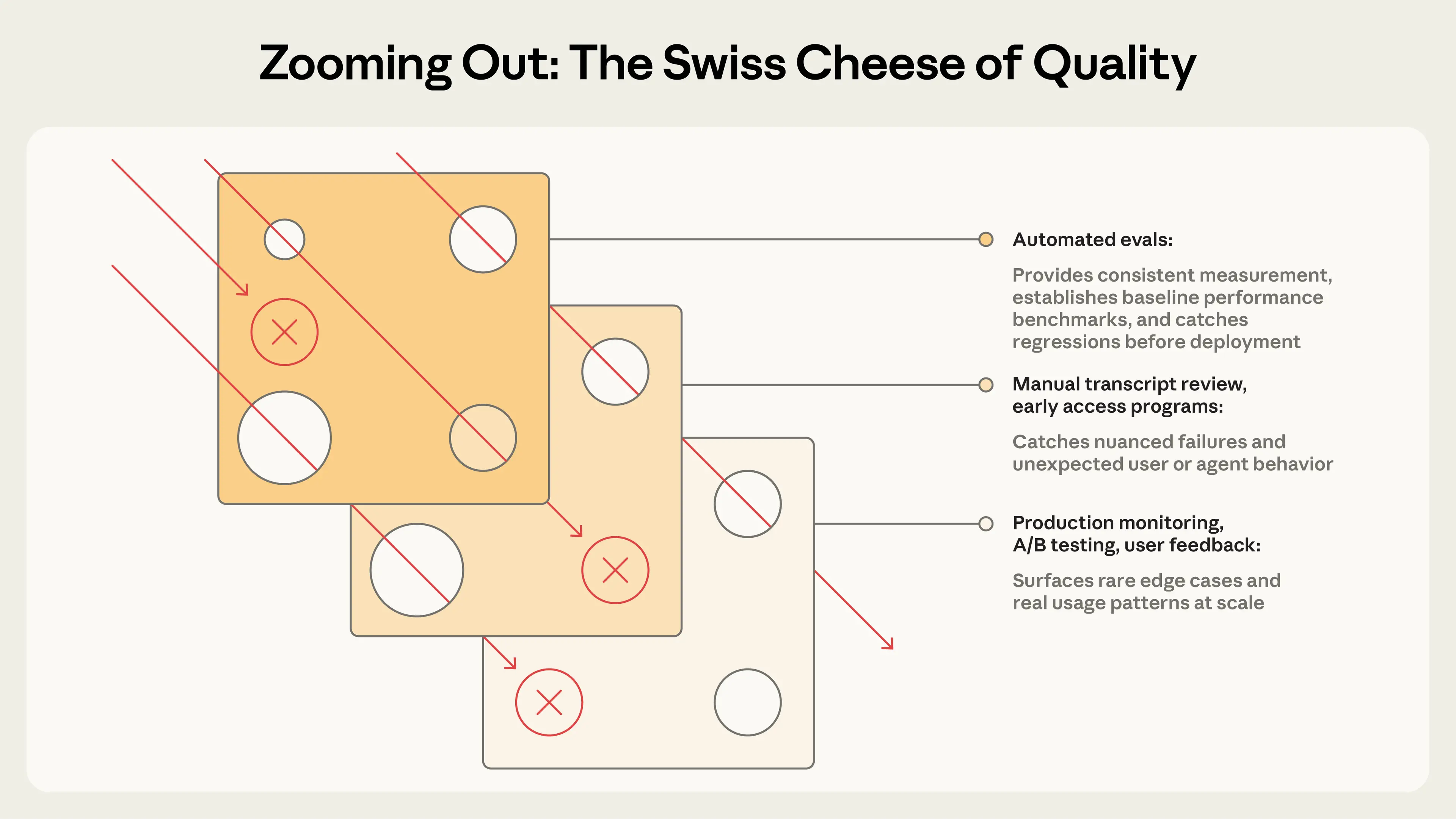
结论
没有评估,团队陷被动循环;有评估,开发加速,失败成测试,指标取代猜测。模式因代理类型变,但基础不变:早开始、真实任务、明确标准、结合评分器、迭代、阅读转录。
代理评估是新兴领域,随着代理处理更长任务,我们需适应。我们会继续分享。
附录:评估框架
几个框架帮助实现:
- ▸
Harbor:容器环境、规模试验、标准格式。 - ▸
Promptfoo:YAML 配置、断言类型。 - ▸
Braintrust:离线评估 + 生产观察。 - ▸
LangSmith:追踪、评估、LangChain 集成。 - ▸
Langfuse:自托管开源替代。
框架加速,但关键是任务和评分器。简单脚本也可起步。
FAQ
AI 代理评估的基本组成部分是什么?
包括任务、试验、评分器、转录、结果、框架和套件。它们确保全面测试。
为什么 AI 代理比简单 LLM 更难评估?
代理多轮、工具调用、状态修改,错误可累积。模型可创意解决,超出静态评估。
如何开始构建 AI 代理评估?
从 20-50 个真实失败任务开始。转换手动检查,写明确任务,构建平衡集。
pass@k 和 pass^k 有什么区别?
pass@k 是至少一次成功的概率;pass^k 是所有成功的概率。前者适合一个好就行,后者适合一致性。
评估中如何处理主观质量?
用模型评分器和规则,校准人类判断。结合 groundedness 和覆盖检查。
评估框架有哪些推荐?
Harbor、Promptfoo、Braintrust、LangSmith、Langfuse。根据栈选择。
HowTo: 构建你的第一个 AI 代理评估
-
定义任务:选择 20 个从生产失败中抽取的任务。确保明确输入和标准。
-
创建参考解决方案:为每个任务写通过所有评分器的输出。
-
设置框架:用 Promptfoo 等工具配置。隔离环境。
-
选择评分器:优先代码-based,如字符串匹配。加 LLM 规则用于细微。
-
运行试验:多次运行,计算 pass@k 或 pass^k。
-
审查转录:阅读失败,调整任务或评分器。
-
迭代:添加任务,避免饱和。维护套件。
遵循这些,你能从零构建可靠评估。(字数:约 4500 字)

