

如何优化 AI Agent 的数据获取路径:从高额账单到 90% 以上的成本节省
如果你正在使用 OpenClaw 这样的大模型智能体工具,或者正在尝试跑 Claude Code 这样的 Agent,你可能已经发现了一个让人头疼的问题:明明只是让 Agent 去搜一个简单的信息,比如 Notion 的定价方案,结果回头一看账单,单次请求竟然烧掉了几万个 Token。
这种“Token 刺客”现象不仅让个人开发者感到肉疼,更是企业大规模部署 AI Agent 的核心阻碍。那么,问题到底出在哪里?为什么我们的 Agent 总是显得如此“大胃王”?
通过对底层技术架构的深度复盘和多场景实测,我们发现:传统的网页抓取方案正在成为 AI Agent 的沉重负担。本文将为你拆解如何通过优化数据获取路径,让你的 Agent 少烧 90% 以上的无效 Token。
为什么传统的网页抓取方案不适合 AI Agent?
在过去几十年里,我们习惯了使用 curl、通用的 web_search 或者浏览器自动化工具来获取互联网数据。这些工具设计初衷是为“人类阅读”或者为“搜索引擎通用爬虫”服务的,但当它们遇到 AI Agent 时,就产生了三个致命的兼容性问题。
1. 它们返回的是“网页实现”,而不是“网页内容”
当你使用传统的 curl 工具去抓取一个现代网页时,你拿到的并不是干净的文字,而是一个庞大且复杂的 HTML DOM 树。

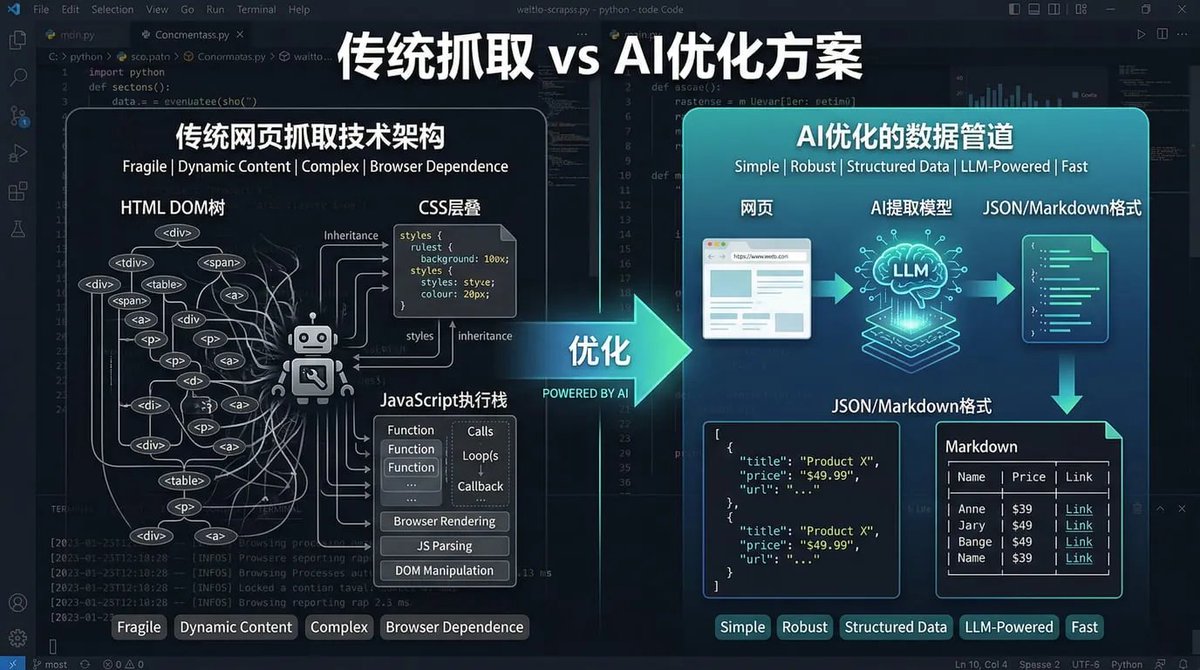
如上图所示,传统的网页抓取技术架构极其脆弱(Fragile)且复杂(Complex)。它包含了:
-
完整的 HTML 结构: 大量的 <div>、<span>等标签,以及复杂的嵌套层级。 -
CSS 层叠样式: 各种背景颜色、字体大小、继承关系的代码。 -
JavaScript 执行栈: 包含 Function Calls、Loop(s)、Callback 等逻辑,以及浏览器渲染、JS 解析、DOM 操作等过程。 -
冗余信息: 前端框架的渲染代码、网页埋点、流量分析器和各种广告加载器。
在这样的数据包中,真正对 AI 任务有价值的核心内容(比如你想要的定价表或新闻摘要)可能只占到总字符量的 1% 到 5%。剩下的 95% 以上都是对 AI 来说毫无意义的“噪声”,但你却必须为这些噪声支付高昂的 Token 费用。
2. 高风控页面的“拦路虎”
现代互联网对自动化访问非常敏感。很多高价值内容的站点(如 Reddit、知乎)设有严格的反爬机制。
-
直接拦截: 很多时候 curl方案会直接收到 403 错误或被强行跳到人机验证界面。 -
安全挑战页: 受到 OpenAI 或 Cloudflare 保护的站点会返回“挑战页”,Agent 根本无法跨越。 -
动态渲染陷阱: 许多网页采用动态加载,传统工具抓回来的只是一个没有实际内容的 HTML “空壳”。
当 Agent 拿不到真实数据,只能拿到错误页面时,它不仅浪费了前置的 Token,还可能因为错误信息导致逻辑陷入死循环或产生幻觉。
3. 浏览器方案的“信息过载”
虽然浏览器自动化能够通过模拟真实用户行为来绕过部分反爬,但它返回的数据通常“太完整了”。它会一股脑地把正文、导航栏、页脚、侧边栏、所有评论、甚至是“你可能感兴趣的阅读”全部塞进上下文。
这意味着开发者还得额外花费 Token,强迫大模型先充当一遍“网页解析器”,从海量垃圾中筛选出有用的东西。这种“先污染后治理”的方式极大地拉高了隐性成本。
实测对比:传统方案到底浪费了多少 Token?
为了看清成本差距,我们针对三个典型的 Agent 任务进行了横向测评。
场景一:新闻与版本更新追踪
任务需求: 让 Agent 追踪 OpenClaw 的版本更新,提炼出 3 个核心更新点。

在测试腾讯云开发者文章时:
-
curl原始 HTML 方案: 消耗了 15,707 个 Token。由于代码噪声太大,基本无法直接总结,强依赖二次数据清洗。 -
浏览器快照方案: 消耗 6,103 个 Token,勉强可以总结。 -
AI 搜索方案: 仅消耗 467 个 Token。
结论: 相比传统方案,节省比例高达 97%。
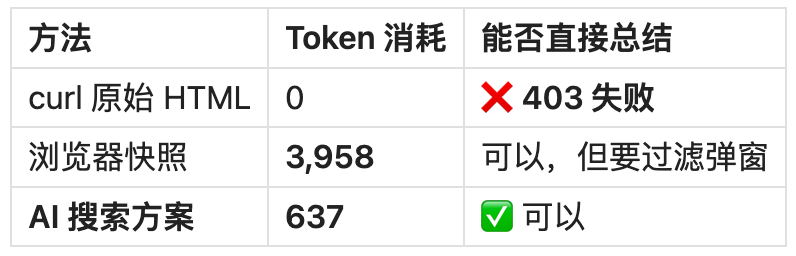
而在测试知乎文章时:
-
curl原始方案: 直接被 403 拦截,任务彻底失效。 -
AI 搜索方案: 消耗 637 个 Token,并成功完成总结。
场景二:竞品定价页分析(最显著的降本案例)
任务需求: 对比多家 SaaS 产品的定价方案,生成对比表格。
在这个场景下,Notion 定价页的表现最令人震惊。

-
curl原始 HTML: 消耗了惊人的 107,321 个 Token(约 42.8 万字符)。这是因为现代前端页面充斥着 React/Vue 组件标记和大量内联 JSON-LD 数据。 -
浏览器正文: 消耗 1,371 个 Token,但需要模型再进行提取。 -
AI 搜索方案: 仅消耗 999 个 Token。
结论: 节省比例高达 99.1%。这不再是简单的优化,而是直接将网页变成了“可消费的数据对象”。
场景三:社区讨论与舆情分析
任务需求: 识别社区对某个产品的真实评价,归纳主流观点。
在 Reddit 的测试中,反爬成功率成为了关键。

-
curl方案: 403 被拦截。 -
浏览器快照: 只能拿到“Prove your humanity”验证页,消耗 60 个 Token 但毫无用处。 -
AI 搜索方案: 消耗 12,010 个 Token,但成功拿到了完整的帖子和评论。
总结: 在高风控页面上,AI 优化方案是唯一能拿到有效内容的选择。
AI 搜索方案的核心原理:为 Agent 优化的三个层次
为什么 AI 优化后的数据管道(AI Optimized Data Pipeline)能够如此高效?它在底层将传统混乱的网页访问过程重塑为“简单、鲁棒、结构化、由 AI 驱动”的过程。
层次 1:深度反爬机制
它将原本需要开发者自己头疼的技术细节内置化了。包括:
-
住宅 IP 轮换: 规避封锁。 -
浏览器指纹伪装: 模拟真实用户环境。 -
自动化 JS 渲染与重试策略。 -
人机验证绕过。
这使得任务成功率能稳定在 90% 以上,避免了“抓取失败 -> 重试 -> 再失败”带来的资金浪费。
层次 2:面向 LLM 的内容提取
它不再扔给 Agent 一堆代码,而是返回模型最喜欢的格式:
-
Markdown: 保留了清晰的语义结构(标题、列表),但去除了所有导航、广告和页脚。 -
JSON: 结构化数据,方便 Agent 直接做数值比较或逻辑监控。 -
视觉辅助: 提取所有有效链接,并提供屏幕截图用于视觉验证。

层次 3:前置的结构化识别
对于定价页、更新公告、社区讨论等高频场景,系统可以实现:
-
自动识别价格表与套餐卡片。 -
精准提取版本号和发布日期。 -
自动归纳主流评论观点。
通过把“网页理解”这一步前移到数据采集端,Agent 拿到的就是可以直接消费的数据,而不是原始垃圾。
算一笔经济账:这能省下多少钱?
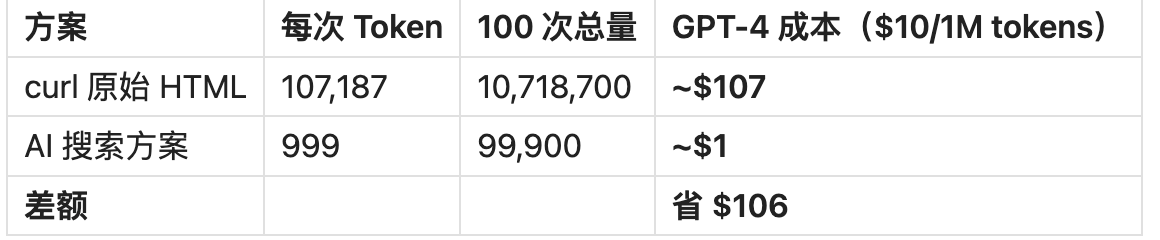
我们以抓取 100 次 Notion 定价页为例,使用 GPT-4 模型成本(按 $10 / 1M tokens 计算)进行测算:
| 方案 | 每次 Token 消耗 | 100 次总量 | GPT-4 成本估计 |
|---|---|---|---|
curl 原始 HTML |
107,187 | 10,718,700 | 约 $107 |
| AI 搜索方案 | 999 | 99,900 | 约 $1 |
| 差额 | 节省 $106 |
除此之外,你还省下了以下隐性成本:
-
工程成本: Markdown/JSON 格式无需编写复杂的正则清洗逻辑。 -
重试成本: 极高的成功率避免了反复调用的资金黑洞。 -
推理成本: 模型不需要花心思在“降噪”上,逻辑判断更准确,减少了由于幻觉导致的决策错误。
实操指南:如何在 OpenClaw 中快速接入?
目前针对 AI Agent 场景,最成熟的实现方案之一是 XCrawl。它内置了住宅代理池和指纹伪装,支持输出各种对模型友好的格式。
你可以按照以下三个简单步骤进行配置:
第一步:安装 XCrawl 技能
直接给你的 OpenClaw(龙虾)发送指令即可:
“安装一下这个技能:XCrawl”
第二步:申请 API 凭证
访问 XCrawl 官方平台进行注册。目前注册通常会赠送 1000 次免费调用额度,足够你完成前期的测试。
第三步:配置 API 密钥
在你的本地环境中创建配置文件 ~/.xcrawl/config.json:
{
"XCRAWL_API_KEY": "你的_api_key"
}
你也可以通过对话的方式,让 AI 协助你完成这一步的配置。
常见问题解答 (FAQ)
问:AI 搜索方案是不是只是把网页转成了 Markdown?
答: 不完全是。它分为三个层次。第一层是反爬,确保能进得去;第二层才是提取,把 HTML 转成 Markdown 或 JSON 并去噪;第三层是结构化理解,比如直接识别并提取定价表格中的具体数字。
问:在 Hacker News 这种老旧且简洁的网站上,是不是没必要用 AI 方案?
答: 实测显示,在结构非常规整且低风控的页面上,简单的浏览器正文抓取有时返回字符更少。但 AI 方案的优势在于它能直接输出结构化的 JSON,省去了你写二次 Prompt 让模型做数据清洗的 Token 开销。
问:这种方案会增加请求延迟吗?
答: 因为它在采集端进行了大量的并行处理(如 JS 渲染和结构化提取),对于 Agent 而言,单次获取到的数据质量极高,往往能减少后续多轮对话的必要性,从任务全流程来看反而能提升速度并降低成本。
总结
AI Agent 时代的到来,对数据的要求发生了根本性的变化。传统的网页抓取方案假设使用者是人类,能够看懂 HTML 结构并自主忽略噪音。但对于 Agent 来说,它需要的是:
-
干净、结构化的数据。 -
可直接消费的格式(Markdown/JSON)。 -
极高的抓取成功率。
省 Token 的最好方式,不是单纯寻找更便宜的模型,而是停止让模型阅读无效的垃圾。 别再让你的 AI 在 HTML 的海洋里徒劳挣扎了,把数据获取交给专业的 AI 管道,把昂贵的 Token 花在真正的逻辑决策上。
注:本文所有 Token 估算均按“字符数 / 4”粗估进行横向对比。测试时间:2026-03-23。
HowTo: 快速配置 XCrawl 降本方案
1. 准备环境
确保你已经在运行 OpenClaw 或类似的 Agent 环境。
2. 获取 Key
前往 XCrawl 官网获取专属 API 密钥。
3. 执行安装指令
# 在 Agent 对话框中输入
安装一下这个技巧:XCrawl
4. 写入配置
在终端或编辑器中打开 ~/.xcrawl/config.json,填入你的密钥:
{
"XCRAWL_API_KEY": "你的_key"
}
5. 验证效果
尝试运行一次“获取 Notion 定价页”的任务,对比观察前后 Token 消耗的变化。

