

2025年大型语言模型回顾:推理崛起、成本下降与未来展望
2025年即将结束,这无疑是人工智能领域,特别是大型语言模型(LLM)发展历程中又一个里程碑式的年份。如果你感觉技术进步的步伐不仅没有放缓,反而在加快,你的感觉是对的。从能够展示“思考过程”的推理模型,到训练成本的大幅下降,再到模型架构的持续进化,过去一年充满了实质性的突破。
这篇文章将带你回顾2025年LLM领域最重要的进展,解释这些技术如何改变我们与AI互动的方式,并展望即将到来的2026年。我们将避开艰涩的黑话,用通俗的语言讲清楚:这一年到底发生了什么,以及它为何与你息息相关。
为什么说2025年是“推理之年”?
回顾过去几年,LLM的发展每年都有一个突出的主题。你可以这样概括:
-
2022年:RLHF + PPO。这是ChatGPT惊艳世界的基础,通过人类反馈来微调模型的行为。 -
2023年:LoRA与高效微调。让人们能够以更低的成本为自己的需求定制小型模型。 -
2024年:中期训练。各大实验室开始专注于优化训练数据,使用合成数据、调整数据配比,让预训练更精良。 -
2025年:RLVR + GRPO。核心是让模型学会“推理”。
那么,什么是“推理”?在LLM的语境中,推理不仅仅是指模型给出答案,更是指它能够展示出得出这个答案的中间思维步骤。就像一位数学老师不仅给出最终解,还一步步写下演算过程一样。这种“过程输出”本身通常就能显著提高答案的准确性。
DeepSeek R1:2025年的开年震撼
2025年1月,中国的研究机构深度求索(DeepSeek)发布了R1模型的论文,如同一颗投入湖面的巨石,激起了层层涟漪。R1之所以备受关注,原因有三:
-
强大的开放性能:DeepSeek R1作为一个“开放权重”模型(即其设计细节和部分参数公开),其性能足以与当时顶尖的闭源模型(如ChatGPT、Gemini)相媲美。这让更多研究者和开发者能够接触到前沿技术。 -
颠覆性的成本认知:R1的论文促使人们重新审视其前身DeepSeek V3的成本。结论令人惊讶:训练一个顶尖模型的成本可能接近500万美元,这比之前人们猜测的5000万甚至5亿美元低了一个数量级。更震撼的是,在V3基础上训练出R1,额外成本仅需约29.4万美元。这大大降低了顶级AI模型研发的门槛。 -
引入RLVR与GRPO:这是技术上的核心突破。R1论文提出了具有可验证奖励的强化学习(RLVR),并采用了GRPO算法。简单理解,这是一种新的训练方法,能让模型通过解决大量可以自动验证对错的问题(比如数学题、代码题)来学习复杂的推理能力,而无需依赖昂贵且稀缺的人工标注。

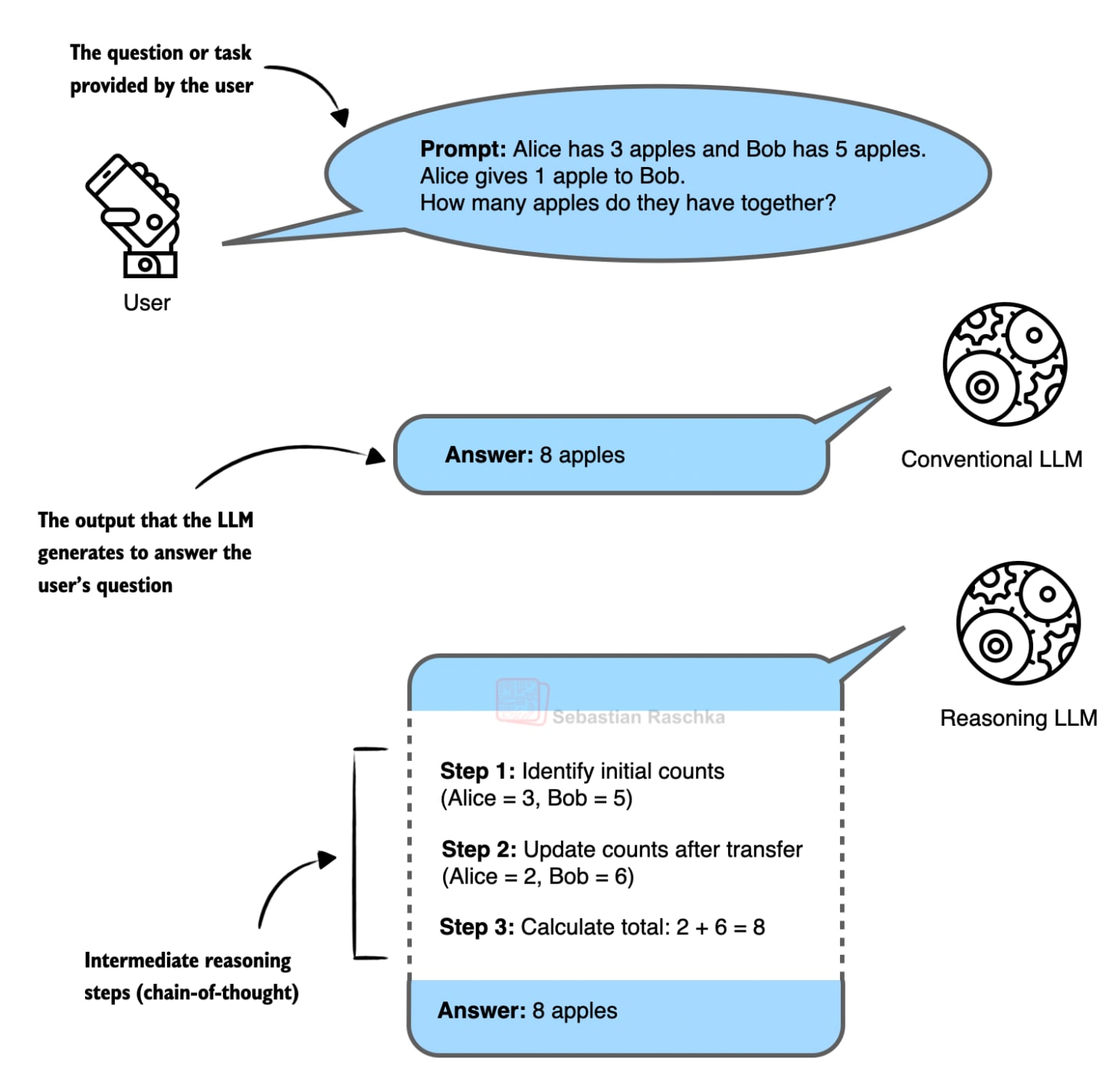
图1:推理模型的回答对比。左边是直接给出答案,右边是展示了推理链条(思考过程)的答案。
RLVR中的“可验证”,意味着系统可以使用确定性的方法(比如运行代码、验算数学结果)自动判断模型输出的对错,从而提供学习信号。这解决了以往RLHF需要大量人工偏好标注的瓶颈。
自此之后,几乎每个主要的LLM开发商,无论是开放还是闭源,都推出了自己模型的“推理”或“思考”变体。 可以说,DeepSeek R1为2025年的LLM发展定下了基调。
GRPO:2025年学术与工业界的研究宠儿
在LLM训练成本高昂的时代,学术界常常能孕育出后来被工业界广泛采用的高效方法。前几年有LoRA(高效微调)和DPO(直接偏好优化)。
2025年的明星无疑是GRPO。虽然它随DeepSeek R1论文提出,但其概念清晰且在一定规模下实验成本可承受,迅速激发了大量研究。学术界和工业界的研究人员提出了各种GRPO的改进技巧,例如:
-
零梯度信号过滤 -
主动采样 -
令牌级损失 -
无KL损失
这些改进并非纸上谈兵,它们被成功集成到了像OLMo 3和DeepSeek V3.2等最先进模型的训练流程中,使得训练过程更加稳定和高效。实践者反馈,应用这些技巧后,训练过程更少出错,效果提升显著。
模型架构:Transformer依然主流,但效率优化层出不穷
在模型架构方面,一个基本事实是:最先进的模型仍然基于解码器风格的Transformer。然而,为了提升效率,2025年的主流开源模型普遍采用了两种技术:
-
混合专家(MoE)层:让模型的不同部分擅长处理不同任务,从而在不显著增加计算成本的情况下扩大模型规模。 -
高效注意力机制:如分组查询注意力、滑动窗口注意力等,以降低长文本处理的计算开销。
除此之外,我们也看到了一些更激进的、旨在实现线性效率的架构开始进入实用视野,例如Qwen3-Next和Kimi Linear中的Gated DeltaNets,以及NVIDIA Nemotron 3中的Mamba-2层。这些架构探索的目标很明确:在模型训练和部署规模巨大的今天,任何能节省成本的工程优化都具有巨大的商业价值。

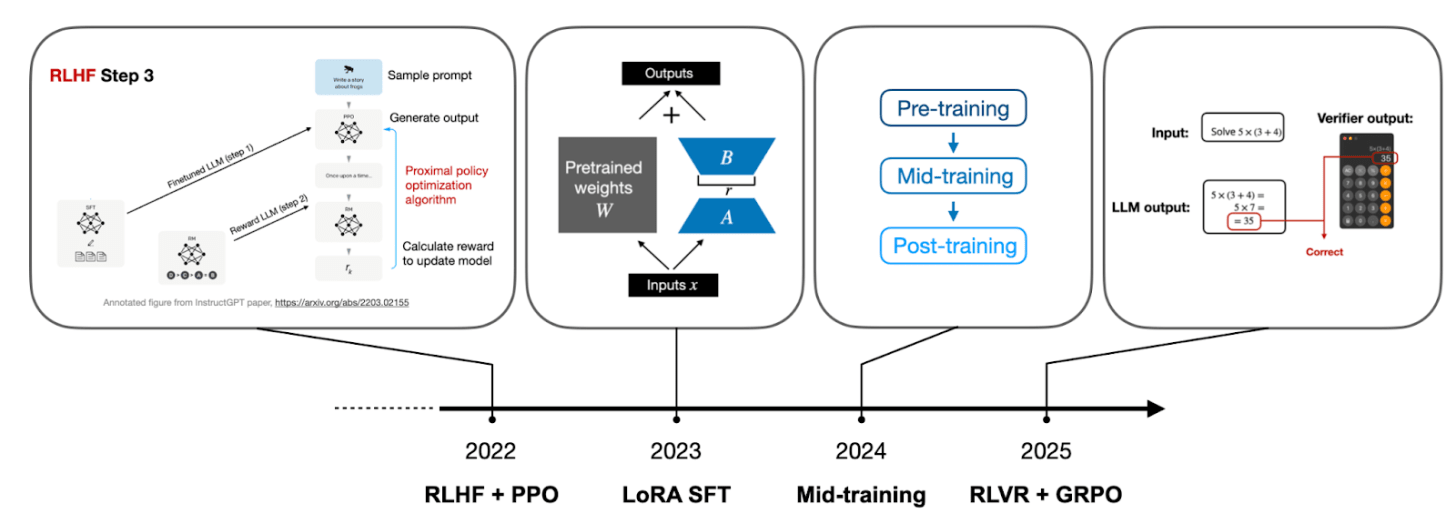
图6:LLM发展重点的演变。新的技术会加入,但旧的技术并未消失,而是构成了累积的技术栈。
预测:Transformer架构的核心地位在未来几年仍将保持,但我们会看到越来越多围绕它的效率和工程优化。同时,像文本扩散模型(如谷歌的Gemini Diffusion)这类替代架构,可能会在需要极低延迟的特定任务(如代码补全)中找到用武之地。
超越训练:推理扩展与工具使用的崛起
2025年告诉我们,改进LLM不只有“扩大训练数据”和“改进架构”这两条路。推理扩展和工具使用成为了至关重要的新维度。
什么是推理扩展?
简单说,就是在模型生成答案时,允许它“多想想”。这可能会增加响应时间和计算成本,但对于那些准确性远比速度重要的任务(如解决复杂的数学竞赛题、编程难题),这是完全值得的。例如,DeepSeekMath-V2和GPT Heavy Thinking等模型就通过极致的推理扩展,在顶级数学竞赛基准上达到了金牌水平。
工具使用:对抗“幻觉”的利器
LLM“一本正经地胡说八道”(幻觉)的问题一直在改善,其中一大功臣就是工具使用。与其让LLM死记硬背所有知识(这不可能且容易出错),不如教会它在需要时调用合适的工具。
-
问“1998年世界杯冠军是谁?” -> LLM调用搜索引擎API,从国际足联官网获取准确信息。 -
问一个复杂计算题 -> LLM调用计算器API。
这不仅提高了准确性,也大大扩展了LLM的能力边界。OpenAI的gpt-oss就是较早专为工具使用设计的开源模型之一。不过,在开源生态中,安全、可控地集成工具使用仍是一个正在发展的挑战。
基准测试的困境:“刷榜”时代的反思
2025年的一个关键词是 “benchmaxxing” ,即过度专注于提升在公开基准测试排行榜上的分数,有时甚至到了为分数而优化,而非提升真实能力的地步。
一个著名的例子是Llama 4,它在许多基准测试上取得了惊人高分,但用户实际使用后发现,其通用能力和实用性并未达到分数所暗示的水平。问题根源在于,当测试集公开且可能被无意甚至有意地混入训练数据时,基准测试分数就逐渐失去了衡量模型泛化能力的效力。
这给我们什么启示?
-
基准测试是必要的门槛:如果一个模型在关键基准上分数很低,它很可能不是好模型。 -
但不是充分的标准:两个模型在同一个基准上分数都很高,并不代表它们在实际应用中的表现差距与分数差距成正比。
评估一个多才多艺的LLM,远比评估一个单纯的图像分类器复杂得多。目前,除了不断创建新的、更难以“刷题”的基准测试,以及在真实场景中试用模型,还没有完美的解决方案。
LLM如何改变工作:赋能者,而非取代者
很多人担心LLM会取代人类工作。但更积极的视角是:LLM是强大的“赋能工具”,它赋予从业者“超能力”,消除工作中的障碍,让人能聚焦于更有价值的部分。
在编程中
-
我仍然编写我关心的核心代码:对于需要深刻理解和确保正确性的逻辑(如训练算法),亲自动手能巩固知识、确保质量。 -
LLM帮我处理繁琐的样板代码:例如,为脚本添加命令行参数解析接口。这节省了大量重复劳动时间。 -
LLM作为高级助手:帮我发现代码问题、提出改进建议、验证想法的合理性。

图14:LLM帮助快速生成代码样板的一个例子。
关键在于辨别何时使用LLM,何时亲力亲为。使用LLM来提升技能和效率,而不是完全外包思考。由专家精心设计和维护的代码库(即使专家用了LLM辅助),其质量在可预见的未来仍将远超完全由LLM从零生成的代码。
在技术写作与研究中
-
LLM是优秀的协作者:可以帮助检查技术正确性、提高文字清晰度、查找文献、提出实验思路。 -
但无法替代专家的深度工作:一本优秀的技术书籍需要作者数千小时的投入和深厚的领域知识。LLM可以辅助,但核心的叙事、判断和知识体系构建仍依赖于人。 -
对读者亦然:LLM适合快速答疑和入门解释。但要建立系统性的深入理解,遵循专家设计的结构化学习路径(书籍、课程)仍然是更高效的选择。
一个有用的比喻:国际象棋
国际象棋AI早已超越人类冠军,但人类国际象棋比赛并未消失,反而变得更加精彩。职业棋手利用AI来探索新战术、挑战直觉、深度分析错误。LLM之于脑力工作者,就如同AI之于棋手——是一个能加速学习、拓展能力边界的高效伙伴。
2025年的意外与2026年的预测
2025年令人惊讶的进展
-
推理模型金牌级表现:多个模型(包括开源和闭源)在2025年就在国际数学奥林匹克竞赛难度的基准上达到金牌水平,比预期来得更快。 -
Llama失宠,Qwen崛起:在开源社区,Qwen系列的受欢迎程度和影响力已经超过了Meta的Llama系列。 -
架构借鉴成为常态:例如,Mistral AI在其旗舰模型Mistral 3中采用了DeepSeek V3的架构。 -
开源战场群雄并起:除了Qwen和DeepSeek,Kimi、GLM、MiniMax、Yi等都加入了顶尖开源模型的竞争。 -
OpenAI发布开源模型:发布了gpt-oss,这是一个标志性事件。
对2026年的预测
-
扩散模型走向实用:像Gemini Diffusion这样的文本扩散模型,可能会因其极低的延迟而在消费级应用(如代码补全)中找到一席之地。 -
工具使用成为标配:开源社区将逐步接受并整合本地化的工具使用能力,LLM的“智能体”属性会增强。 -
RLVR拓展疆域:强化学习与可验证奖励的训练方法将从数学、代码扩展到化学、生物学等其他需要严谨推理的领域。 -
长上下文模型部分替代RAG:对于文档问答,随着“小而精”的长上下文模型变得更好,传统的“检索-增强生成(RAG)”可能不再是唯一默认方案。 -
进步来源的转移:性能的显著提升将更多地来自推理扩展、工具调用等外围改进,而不仅仅是模型核心训练本身的突破。同时,产业界也会更努力地优化延迟,避免不必要的“思考”开销。
总结:多元化的进步与不变的判断力
2025年的启示是清晰的:LLM的进步不是依靠单一的“银弹”,而是通过架构、数据、训练范式、推理过程、工具生态等多个维度齐头并进取得的。
与此同时,模型的评估依然困难,基准测试并不完美。最终,如何以及何时使用这些强大的系统,仍然依赖于人类良好的判断力。 我们希望2026年,在见证更多惊喜进步的同时,也能对这些进步的根源有更清晰、更透明的认识。
常见问题解答 (FAQ)
1. 什么是LLM的“推理”能力?
在大型语言模型中,“推理”能力指的是模型不仅给出最终答案,还能展示出得出该答案的逻辑思维过程和中间步骤。这类似于解数学题时写出“解题步骤”,通常能提高答案的准确性。
2. DeepSeek R1为什么重要?
DeepSeek R1在2025年初发布,它证明了可以通过强化学习技术(RLVR/GRPO)高效地训练出具有强大推理能力的模型。同时,它作为开放权重模型展现了媲美闭源模型的性能,并显著降低了顶级模型训练的成本预期。
3. RLVR和传统的RLHF有什么区别?
RLHF(基于人类反馈的强化学习)依赖人工标注的偏好数据,成本高且稀缺。RLVR(具有可验证奖励的强化学习)则利用可以自动验证对错的数据(如数学题、可运行代码)作为训练信号,实现了更低成本、大规模的推理能力训练。
4. 2025年LLM在基准测试上分数那么高,为什么实际体验有时不符?
这种现象被称为“benchmaxxing”。由于很多基准测试集是公开的,模型可能会在训练中直接或间接地“见过”类似题目,导致分数虚高。这提醒我们,基准分数是必要参考,但不能完全代表模型的通用能力和实用体验。
5. LLM会让程序员或技术作家失业吗?
目前来看,LLM更像是一个强大的“赋能工具”。它自动化了繁琐工作(如写样板代码、检查错误),让专业人士能更专注于需要创造力、深度思考和判断的核心任务。它改变了工作方式,而非简单地取代职位。
6. 对普通用户来说,2025年LLM最大的进步是什么?
最直观的进步可能是出现了更多能够“展示思考过程”的模型(如各种“深度思考”模式),这让AI的回答更可信、更易理解。同时,模型在复杂问题解决(如数学、编程)和工具使用(联网搜索、调用计算器)方面的能力显著增强。
7. 2026年LLM发展最重要的方向是什么?
预计会集中在以下几个方向:1) 将推理训练(RLVR)扩展到更广泛的科学领域;2) 让工具使用和智能体能力成为LLM的标配;3) 持续优化模型架构和推理效率以降低成本;4) 探索如何更好地利用私有数据进行领域专业化。

