用 LangExtract 把任何长文本变成可检索的结构化数据——零门槛上手指南
谷歌开源了一个能从非结构化信息中提取结构化信息的 Python 库 LangExtract
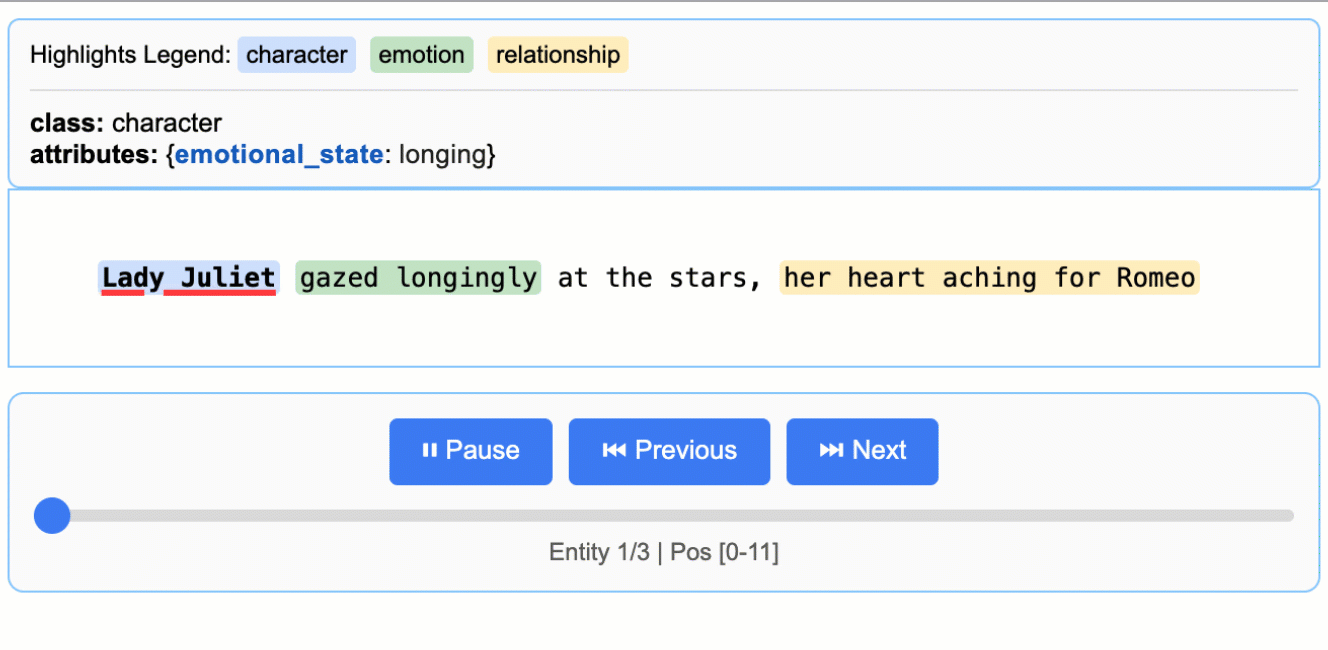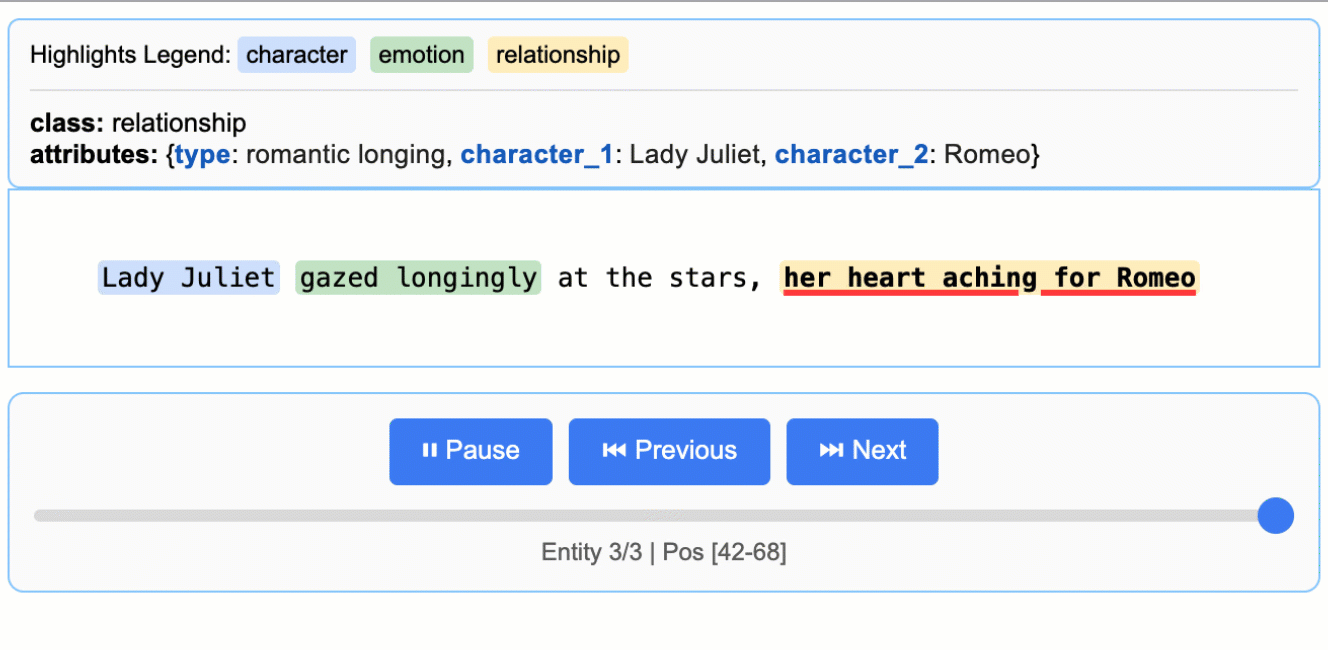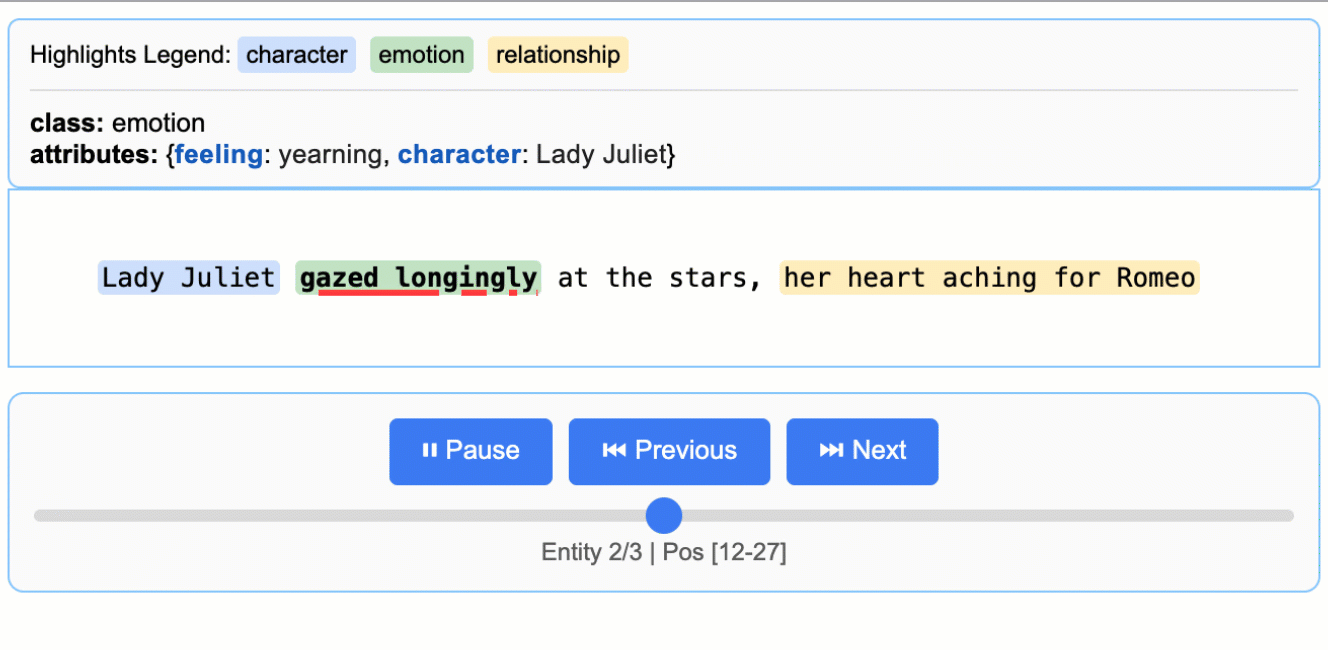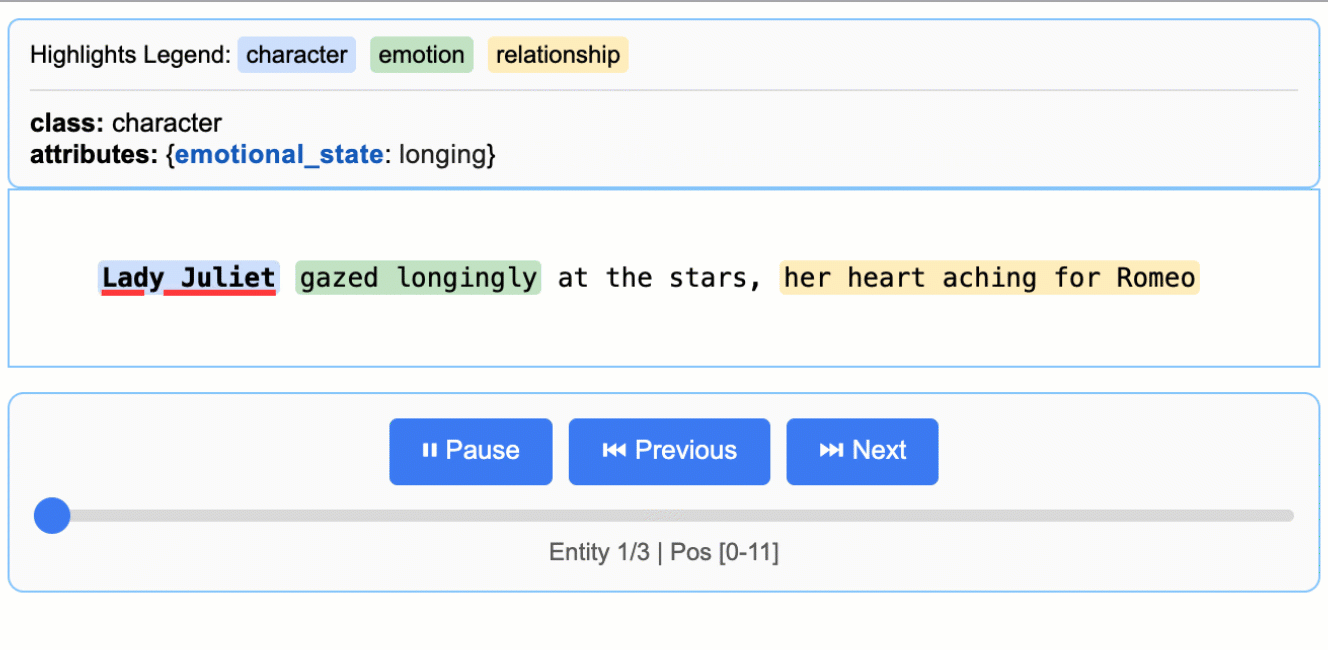
每一条提取结果都能映射到原文的具体位置
针对长文本做了优化,大幅提升召回率和处理效率
云端模型和本地模型都支持
一键生成 HTML 文件,直观展示千上万条提取实体
只需少量示例即可适配任意领域
阅读预期:30 分钟可完成首次运行,2 小时可独立完成一次完整提取任务
目录
-
我为什么需要 LangExtract? -
它到底能做什么? -
5 分钟完成第一次提取 -
处理超长文档的实用技巧 -
医疗、剧本、报告三大场景示例 -
常见问题答疑(FAQ) -
进阶:本地部署与贡献代码
1. 我为什么需要 LangExtract?
想象一下:
-
你手里有一本 15 万字的小说,老板要求“把所有人物关系整理成表格”; -
放射科每天产出上百份自由文本报告,你希望自动生成结构化数据; -
客服聊天记录散落在 200 份 PDF 里,你想快速提取“用户情绪+投诉产品”。
传统做法是写正则或训练专属模型,成本高、周期长。
LangExtract 只用“一段提示 + 几条示例”就帮你完成这件事——无需微调模型,也无需写正则。
2. 它到底能做什么?
| 功能 | 一句话解释 | 典型场景 |
|---|---|---|
| 精确溯源 | 每个字段都能定位到原文 | 审计、合规 |
| 结构稳定 | 输出 JSON Schema 保持一致 | 数据入库 |
| 长文本优化 | 自动切块、并行、多轮 | 书籍、病历 |
| 一键可视化 | 生成可交互 HTML | 产品演示 |
| 多模型支持 | Gemini、Ollama、自托管 | 成本可控 |
| 零样本适应 | 不给示例也能跑,给几条示例更准确 | 任何垂直领域 |
3. 5 分钟完成第一次提取
3.1 安装
# 推荐虚拟环境
python -m venv lx_env
source lx_env/bin/activate # Windows 用 lx_env\Scripts\activate
pip install langextract
3.2 获取并配置 API Key(仅使用 Gemini 时需要)
-
打开 AI Studio → 创建 Key -
在项目根目录新建 .envLANGEXTRACT_API_KEY=你的真实key -
把 .env加入.gitignore,防止误提交。
3.3 写第一段代码
import langextract as lx
import textwrap
# 告诉模型要做什么
prompt = textwrap.dedent("""\
提取角色、情绪、关系,按出场顺序。
使用原文,不改动措辞,不重叠实体。
给每个实体加有意义的属性。""")
# 给模型看一个高质量示例
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="角色",
extraction_text="ROMEO",
attributes={"情绪": "惊叹"}
),
lx.data.Extraction(
extraction_class="情绪",
extraction_text="But soft!",
attributes{"感受": "温柔的震撼"}
),
lx.data.Extraction(
extraction_class="关系",
extraction_text="Juliet is the sun",
attributes{"类型": "比喻"}
)
]
)
]
# 输入待处理文本
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# 运行
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash" # 默认推荐,性价比高
)
3.4 结果保存与可视化
# 保存为 JSONL
lx.io.save_annotated_documents([result], "demo.jsonl")
# 生成交互式网页
html = lx.visualize("demo.jsonl")
open("demo.html", "w", encoding="utf-8").write(html)
用浏览器打开 demo.html,即可看到原文高亮与实体卡片。
4. 处理超长文档的实用技巧
4.1 直接读取网络文本
result = lx.extract(
text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3, # 多轮提高召回
max_workers=20, # 并行加速
max_char_buffer=1000 # 每块长度,调小可提升精度
)
4.2 运行时间对照表(本地实测,供参考)
| 文本长度 | 并行块数 | extraction_passes | 耗时 | 提取实体数 |
|---|---|---|---|---|
| 14 万字符 | 20 | 3 | ≈ 90 秒 | 600+ |
| 3 万字符 | 8 | 2 | ≈ 25 秒 | 150+ |
| 5 千字符 | 1 | 1 | ≈ 5 秒 | 30+ |
5. 三大场景完整示例
5.1 剧本人物关系——《罗密欧与朱丽叶》全文
-
原文:Project Gutenberg 版全文 -
提取目标:人物、情绪、关系 -
结果:JSONL 可直接导入 Neo4j 构建知识图谱 -
官方完整示例
5.2 医疗场景——用药信息提取
免责声明:仅用于演示 LangExtract 能力,非医疗建议。
prompt = "抽取药品名称、剂量、给药途径、频次。"
examples = [lx.data.ExampleData(
text="患者每日口服阿司匹林 100 mg 两次",
extractions=[
lx.data.Extraction("药品", "阿司匹林", {"剂量": "100 mg", "途径": "口服", "频次": "bid"})
]
)]
输出字段可直接对接医院信息系统。
官方示例与更多医学用例
5.3 放射科报告结构化——RadExtract 在线演示
无需安装,浏览器打开即可体验:
HuggingFace Spaces: RadExtract
6. 常见问题答疑(FAQ)
| 提问 | 回答 |
|---|---|
| 没有 GPU 能跑吗? | 用 Gemini 这类云端模型即可,本地零 GPU。 |
| 数据会上传谷歌吗? | 使用 Gemini 时文本会发送到谷歌 API;用 Ollama 本地模型则完全本地。 |
| 如何换中文模型? | 目前 Gemini 支持中文,示例里的提示词直接写中文即可。 |
| 结果格式能改吗? | 在 extraction_class 里自定义类别,输出 JSON Schema 自动匹配。 |
| 可以离线用吗? | 可以,通过 Ollama 拉起本地 LLM,再修改 inference endpoint。 |
| 需要多少示例? | 0 条也能跑,3~5 条高质量示例可显著提升一致性。 |
| 多语言支持? | 提示词与示例用什么语言,模型就按该语言输出。 |
7. 进阶:本地部署与贡献代码
7.1 从源码安装(含测试、开发工具)
git clone https://github.com/google/langextract.git
cd langextract
# 基础安装
pip install -e .
# 带开发工具
pip install -e ".[dev]"
# 带测试套件
pip install -e ".[test]"
7.2 运行测试
pytest tests
# 或完整 CI 矩阵
tox
7.3 提交 PR 流程
-
Fork 仓库 -
新建分支 feature/你的功能 -
写测试 → 跑 pytest→ 通过 -
阅读并签署 CLA -
提交 PR,等待 Code Review
结束语
LangExtract 把“写正则、训模型、拼算力”的繁琐流程简化成“一段提示 + 几条示例”,让任何有 Python 基础的同学都能在午餐前完成一次高质量的结构化提取。
下次拿到 20 万字的文本时,不妨打开本文,复制粘贴 10 行代码,看看它能不能帮你省下三天工作量。
Happy Extracting!
