miniCOIL:轻量级稀疏神经检索模型的突破与应用

在信息爆炸的时代,如何高效地从海量数据中检索到相关内容,一直是技术领域的核心挑战。传统的检索方法各有优劣:基于关键词的检索(如BM25)速度快、可解释性强,但无法理解语义;而基于深度学习的密集检索能捕捉语义关联,却难以精确匹配关键词。miniCOIL的出现,为这一难题提供了全新的解决方案——它结合了两者的优势,同时保持轻量化和可扩展性。
本文将深入解析miniCOIL的设计思想、技术实现及其实际应用场景,揭示其如何成为下一代信息检索工具的有力候选。
一、信息检索的困境:关键词与语义的博弈
1. 基于关键词的检索:BM25的局限
BM25是信息检索领域的经典算法,通过统计词频(TF)和逆文档频率(IDF)评估关键词的重要性。它的优势在于高效和可解释,但存在两大缺陷:
-
无法区分词义:例如“蝙蝠”既可指动物,也可指棒球棍,BM25无法根据上下文判断其含义。 -
短文本效果差:在检索增强生成(RAG)等场景中,文本块较短,词频统计的意义被弱化。
2. 密集检索:语义理解的代价
以Transformer模型为核心的密集检索器(如BERT)能捕捉词语的深层语义,支持模糊匹配。但这类模型也存在问题:
-
难以精确匹配关键词:例如搜索“数据点”,结果可能包含“浮点精度”等无关内容。 -
计算资源消耗大:高维向量存储和计算成本较高,不适合实时大规模检索。
3. 稀疏神经检索的曙光
稀疏神经检索试图融合两者的优点:
-
稀疏性:沿用基于关键词的稀疏向量表示,保持高效性。 -
语义感知:通过神经网络动态调整关键词权重,区分词义。
然而,现有模型(如SPLADE)常因复杂扩展技术导致推理速度下降,或过度依赖领域内训练数据而泛化能力不足。
二、miniCOIL的设计哲学:简单而强大
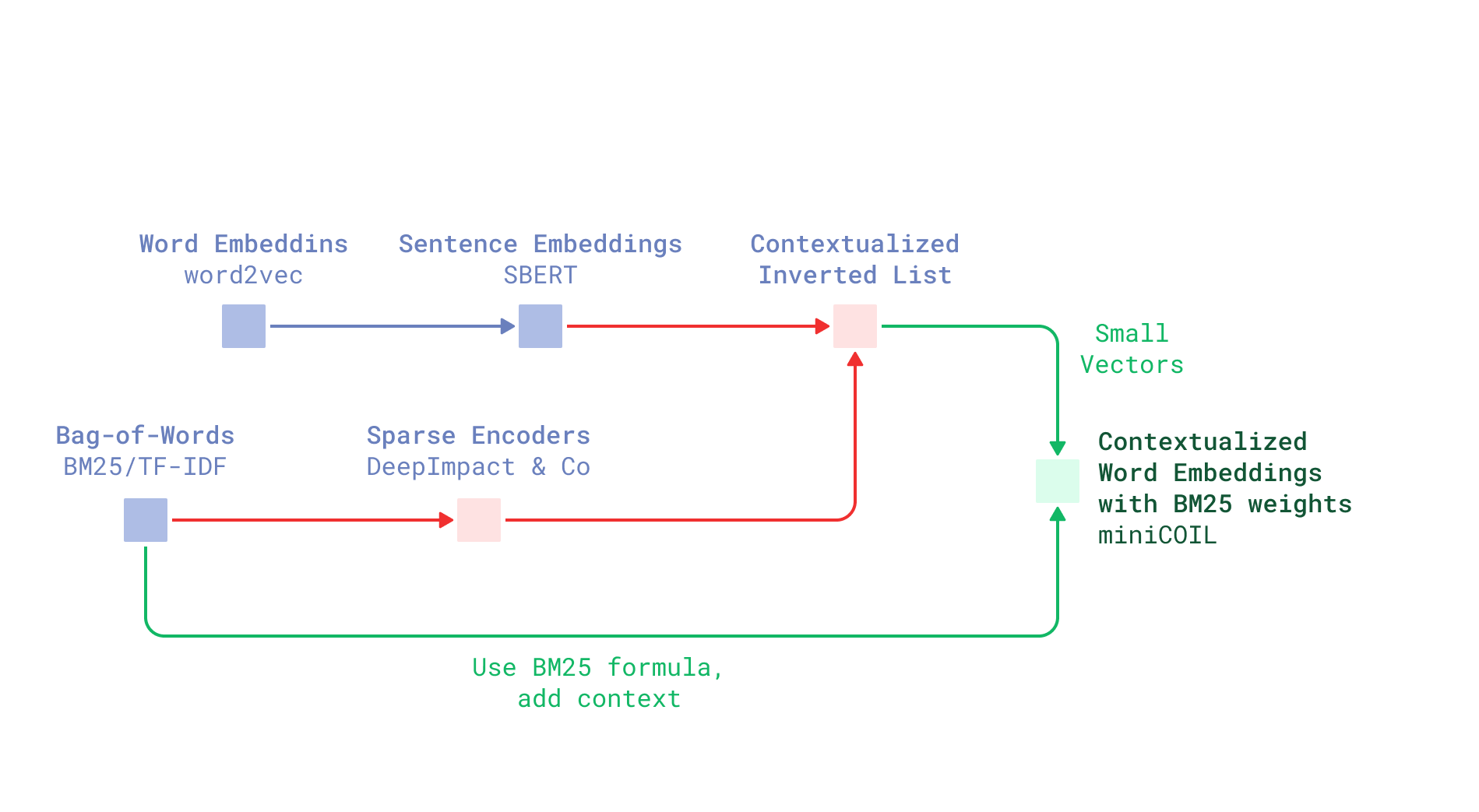
1. 从COIL到miniCOIL的进化
COIL(Contextualized Inverted List)是早期稀疏神经检索的代表,通过将词向量压缩到32维并存储于倒排索引中,实现了语义感知。但其缺陷明显:
-
索引兼容性差:传统倒排索引不支持向量操作。 -
领域依赖性强:仅在训练数据(如MS MARCO)上表现良好。
miniCOIL的改进思路:
-
简化架构:每个单词独立训练一个轻量模型,避免端到端训练的复杂性。 -
兼容传统索引:将词义编码为4维向量,直接嵌入现有倒排索引。 -
跨领域泛化:通过自监督学习,利用大规模无标签数据训练。
2. 核心思想:BM25的语义增强
miniCOIL并未完全抛弃BM25,而是在其基础上增加语义权重:
得分(D, Q) = ∑ [IDF(q_i) × 重要性(D, q_i) × 语义相似度(q_i, D)]
-
语义相似度:通过4维向量捕捉词语的上下文含义。 -
兼容性:若遇到未训练词汇,自动回退到BM25计算。
这种设计既保留了BM25的稳定性,又通过语义组件提升了排序准确性。
三、技术实现:轻量化与泛化的平衡
1. 训练数据与模型架构
-
数据来源:OpenWebText数据集(4000万句子),覆盖广泛领域。 -
词向量压缩:使用线性层将512维密集向量(如Jina Embeddings)降维至4维。 -
训练目标:三元组损失(Triplet Loss),确保语义相近的句子在向量空间中靠近。
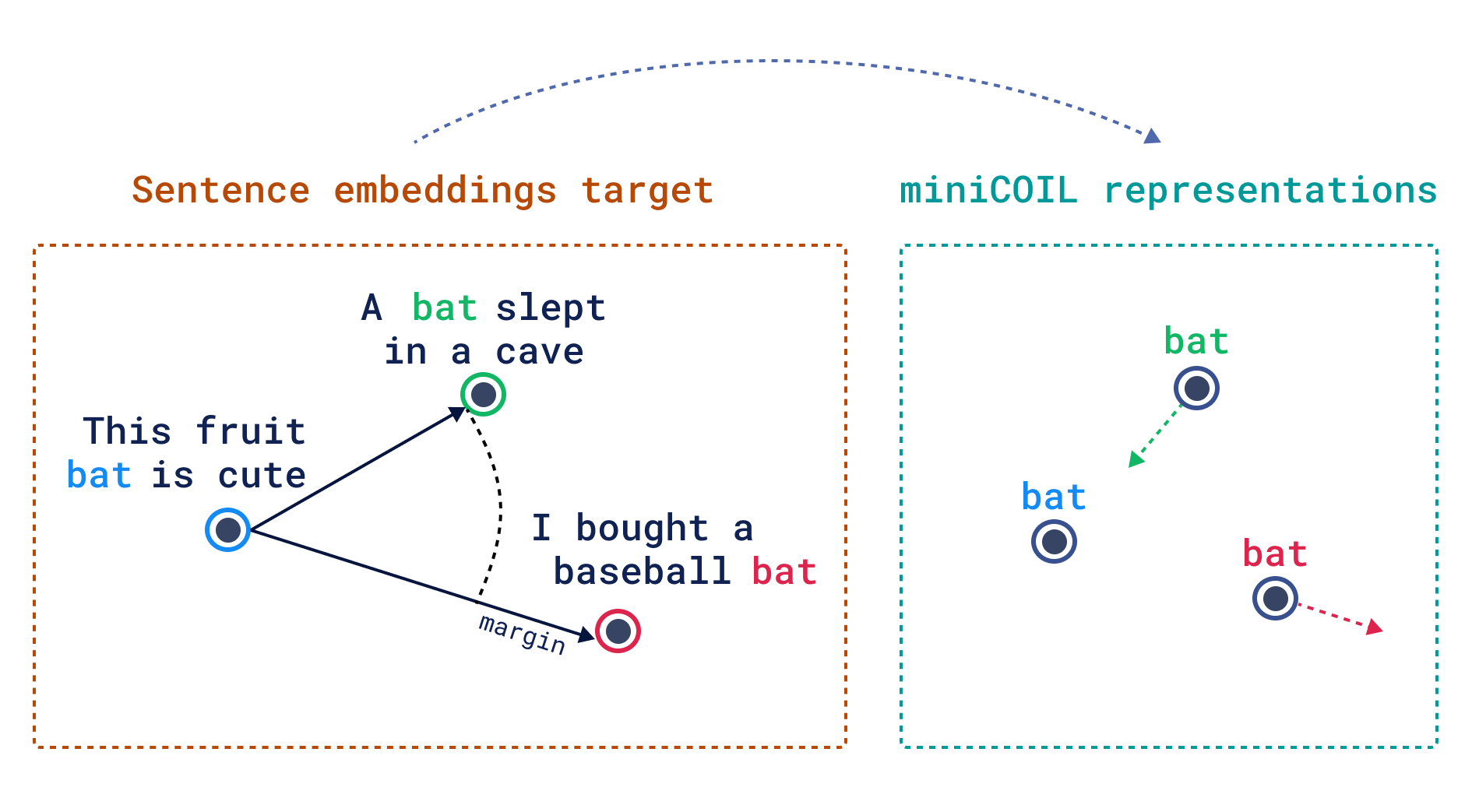
2. 分而治之的训练策略
miniCOIL采用“一词一模型”的独特设计:
-
独立训练:为3万个常用词分别训练4维向量模型。 -
灵活扩展:可根据需求增减词汇量,无需重新训练整个模型。 -
高效推理:单CPU训练每个词仅需50秒,模型推理速度接近BM25。
3. 实际效果验证
在BEIR基准测试中,miniCOIL在多个领域超越BM25:
| 数据集 | BM25(NDCG@10) | miniCOIL(NDCG@10) |
|---|---|---|
| MS MARCO | 0.237 | 0.244 |
| NQ | 0.304 | 0.319 |
| Quora | 0.784 | 0.802 |
| FiQA-2018 | 0.252 | 0.257 |
唯一例外是HotpotQA(0.634 vs. 0.633),说明miniCOIL在复杂推理场景仍有改进空间。
四、应用场景:何时选择miniCOIL?
1. 精确匹配的语义优化
-
案例1:搜索“数据点”时,优先返回“Qdrant中的一条记录”而非“浮点精度”。 -
案例2:区分“苹果公司”与“水果苹果”的上下文。
2. 混合搜索的经济升级
-
优势:复用密集编码器的中间结果,无需额外计算即可提升稀疏检索的语义能力。 -
资源消耗:4维向量对存储和计算的影响可忽略不计。
3. 不适合的场景
-
模糊语义搜索:如需查找“环保能源”但文档使用“可再生能源”,仍需依赖密集检索。 -
长尾词汇:未纳入训练集的生僻词可能回退到BM25。
五、未来展望:更智能的稀疏检索
1. 技术优化方向
-
多语言支持:当前模型仅针对英语,扩展至其他语言需重新训练。 -
动态词表更新:在线学习新词,避免手动扩展词表。 -
高维语义编码:探索4维以上的平衡点,兼顾效率与语义区分度。
2. 生态整合
-
开源社区:代码和模型已在GitHub和Hugging Face开源。 -
Qdrant支持:可通过FastEmbed库直接集成到检索系统。
六、总结
miniCOIL的诞生标志着稀疏神经检索从实验室走向实际应用。它并非颠覆传统方法,而是通过巧妙的改进,在BM25的坚实基础上添加了一层语义理解能力。这种“渐进式创新”使其兼具实用性与前瞻性——既能无缝融入现有系统,又为未来的语义搜索提供了新的可能性。
对于开发者而言,miniCOIL的价值在于:
-
低成本升级:无需重构索引即可提升检索质量。 -
灵活适配:可根据业务需求定制词表和模型。 -
透明可控:4维向量的设计保留了可解释性,避免黑盒模型的不可控风险。
正如Qdrant团队所言:“合适的工具做合适的事。”在关键词匹配仍占主导的场景中,miniCOIL无疑是一把更锋利的瑞士军刀。它的出现,让我们离“既懂关键词又懂语义”的智能检索系统又近了一步。
相关资源