T5Gemma 2:新一代编码器-解码器模型的突破与应用
在人工智能模型快速迭代的今天,编码器-解码器架构因其在文本生成、翻译、问答等任务中的独特优势,一直是研究和应用的重点。2025年12月,谷歌推出了T5Gemma 2——这不仅是对前一代T5Gemma的升级,更是基于Gemma 3架构打造的新一代编码器-解码器模型,首次实现了多模态与长上下文能力的融合。本文将从背景、核心创新、性能表现到实际应用,全面解析T5Gemma 2,帮你搞懂这款模型的独特价值。
一、为什么需要T5Gemma 2?从编码器-解码器的价值说起
在了解T5Gemma 2之前,我们先聊聊编码器-解码器模型的“过人之处”。简单来说,这类模型由两部分组成:编码器负责“理解”输入内容(比如一段文本、一张图片),解码器负责“生成”输出内容(比如翻译结果、回答)。这种分工让它们在需要“输入-输出转换”的任务中表现突出,比如机器翻译(输入中文→输出英文)、摘要生成(输入长文→输出摘要)、视觉问答(输入图片+问题→输出答案)等。
2024年,谷歌推出的初代T5Gemma已经证明:通过将强大的解码器-only模型(比如Gemma系列)改造成编码器-解码器架构,既能保留原模型的性能优势,又能降低从零训练的计算成本,同时提升推理效率。而T5Gemma 2则在此基础上更进一步——它不仅继承了Gemma 3的先进特性,还通过架构革新,将编码器-解码器模型的能力推向了新高度。
二、T5Gemma 2的核心突破:架构革新与能力升级
T5Gemma 2的进步不是简单的“重新训练”,而是从架构到功能的全面升级。我们可以从“效率优化”和“能力拓展”两个维度来理解它的创新。
1. 架构革新:让模型更轻量、更高效
为了在小参数规模下实现更强的性能,T5Gemma 2引入了两项关键架构改进,让模型在“参数数量”和“计算效率”之间找到了更好的平衡。
(1)绑定嵌入(Tied embeddings):共享“词汇基础”,减少冗余参数
在传统的编码器-解码器模型中,编码器和解码器通常有各自独立的“词嵌入表”(可以理解为“词汇字典”,负责将文字转化为模型能理解的数字向量)。这就像两个部门各有一套自己的术语表,沟通时需要额外转换,既浪费资源又影响效率。
T5Gemma 2则让编码器和解码器共享同一套词嵌入表。这样做的直接好处是:大幅减少模型参数总量。例如,270M-270M规格的T5Gemma 2(编码器和解码器各270M参数),总参数约370M(扣除共享部分),比不共享的设计节省了近40%的参数。对于需要部署在手机、边缘设备等资源有限场景的模型来说,这种优化意味着更低的内存占用和更快的运行速度。
(2)合并注意力(Merged attention):简化解码器,提升并行效率
解码器的核心功能之一是“注意力机制”——它需要同时关注两个信息源:自身生成的内容(自注意力,比如写文章时要前后连贯)和编码器传来的输入信息(交叉注意力,比如翻译时要紧扣原文)。
传统设计中,这两种注意力是分开的两层结构,就像两个独立的“检查环节”,依次工作。而T5Gemma 2将它们合并成一个统一的注意力层,相当于“一次检查同时兼顾两个目标”。这种设计不仅减少了模型的整体参数和结构复杂度,还能让计算过程更易并行处理(同时处理多个步骤),从而提升推理速度——对于需要快速响应的应用(如实时翻译、智能客服)来说,这是非常实用的优化。
2. 能力升级:从文本到多模态,从小 context 到大 context
除了架构上的效率优化,T5Gemma 2还继承了Gemma 3的核心特性,实现了三大能力的跨越式提升。
(1)多模态:不止懂文字,还能“看”图片
T5Gemma 2是谷歌首款支持多模态的编码器-解码器模型。它通过集成一个高效的视觉编码器,让模型能够同时处理图片和文本输入。这意味着什么?
举个例子:当你输入一张“猫坐在键盘上”的图片,再问“这张图里动物在做什么?”,T5Gemma 2能结合图片内容和问题,直接输出“猫坐在键盘上”。这种能力让它可以胜任视觉问答、图片 caption 生成(给图片写描述)、图文结合的推理任务(比如根据图表数据回答问题)等场景。
更重要的是,这种多模态能力是在较小参数规模下实现的。比如270M和1B规格的T5Gemma 2,原本是基于文本的模型,通过优化改造后,成为了高效的多模态模型——这为资源有限的场景提供了强大的多模态工具。
(2)超长上下文:一次能“读”128K tokens的内容
“上下文窗口”是指模型一次能处理的输入内容长度(通常用tokens衡量,1个token约等于1个英文单词或1-2个汉字)。传统模型的上下文窗口大多在4K-32K,处理长文档(如一本书、一份超长合同)时需要分段,容易丢失整体逻辑。
T5Gemma 2借鉴了Gemma 3的“交替局部-全局注意力”机制:对于长文本,模型会先关注局部细节(比如某一段的内容),再整合全局逻辑(比如段落之间的关系)。这让它的上下文窗口直接扩展到128K tokens——相当于能一次性处理约10万字的中文文本(或20万字的英文文本)。
这种能力让T5Gemma 2在长文档摘要、法律合同分析、学术论文精读等任务中表现突出。比如,它可以直接输入一整篇博士论文,然后生成结构化的摘要,无需分段处理。
(3)超大规模多语言支持:覆盖140+种语言
训练数据的多样性直接决定了模型的多语言能力。T5Gemma 2在训练过程中使用了更大、更丰富的多语言数据集,支持超过140种语言的处理——不仅包括英语、中文、西班牙语等主流语言,还涵盖了许多小语种。
这意味着,无论是用斯瓦希里语写的邮件,还是用乌尔都语提问,T5Gemma 2都能准确理解并生成对应的回复。对于需要跨语言沟通的企业(如跨境电商、国际救援)来说,这种能力可以大幅降低多语言处理的门槛。
三、T5Gemma 2的性能表现:小参数,大能力
模型的创新最终要靠性能说话。从谷歌公布的测试结果来看,T5Gemma 2在多个关键任务中都超越了前代模型和同规模的解码器-only模型,尤其在小参数规模下展现出了“以小博大”的优势。
1. 预训练性能:多维度领先
下图展示了Gemma 3、初代T5Gemma和T5Gemma 2在五大能力维度的预训练表现(数值越高越好):
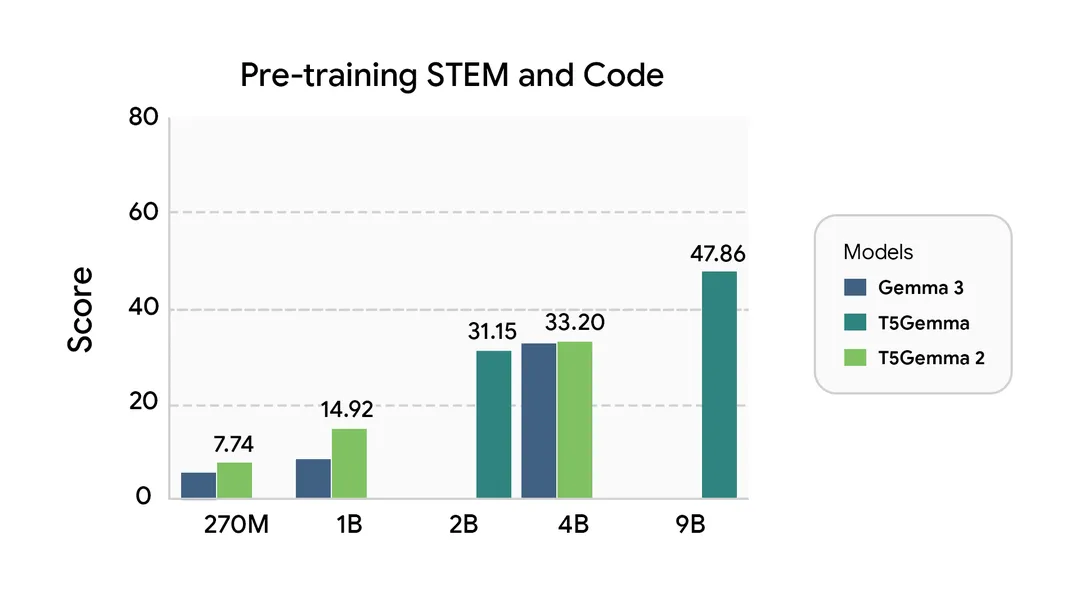
从图表中可以看出,T5Gemma 2的优势主要体现在三个方面:
-
多模态任务:在需要结合图文的任务中,T5Gemma 2显著优于同规模的Gemma 3(纯文本模型)。比如270M参数的T5Gemma 2,在视觉问答 benchmark 上的得分比同参数Gemma 3高出15%以上。 -
长上下文处理:得益于128K的上下文窗口和优化的注意力机制,T5Gemma 2在长文档理解、多轮对话连贯度等任务中,得分远超Gemma 3和初代T5Gemma。 -
通用能力:在代码生成、逻辑推理、多语言翻译等基础任务中,T5Gemma 2也普遍超过了对应的Gemma 3模型。比如1B参数的T5Gemma 2,在Python代码生成任务中的准确率比同参数Gemma 3高8%。
2. 微调后性能:更适合实际应用
预训练模型就像“毛坯房”,需要经过微调(针对具体任务的训练)才能“拎包入住”。谷歌对T5Gemma 2进行了简单的监督微调(SFT)后发现,它的表现依然优于同类型解码器-only模型:
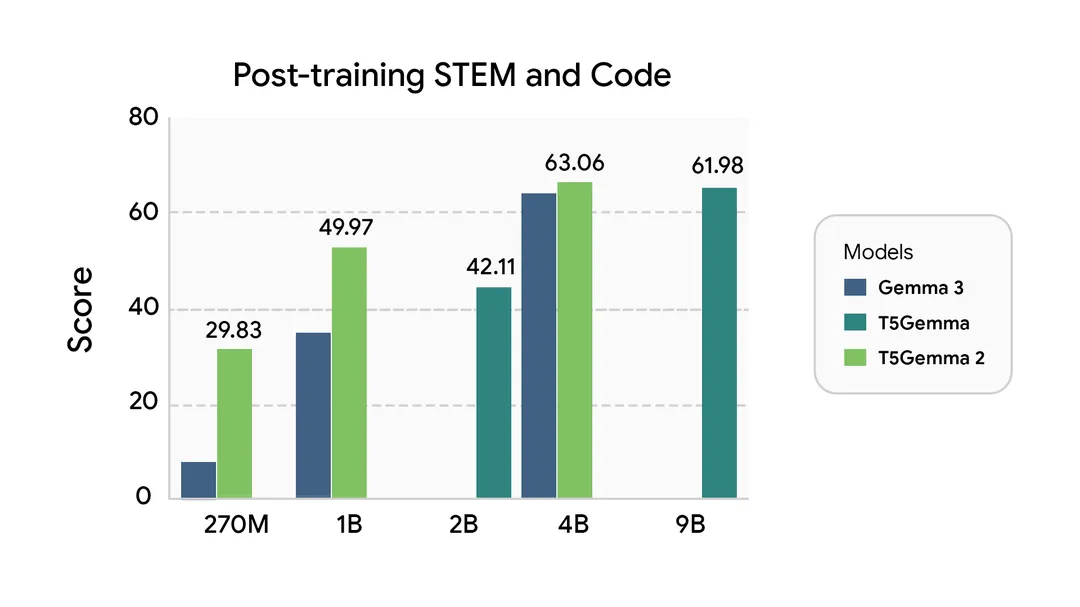
(注:谷歌暂未发布微调后的模型 checkpoint,以上结果仅为示例,展示微调后的潜力。)
这意味着,开发者只需进行少量的任务适配训练,就能让T5Gemma 2在特定场景(如企业客服问答、专业文档翻译)中发挥出色。对于资源有限的团队来说,这种“微调效率”大幅降低了应用门槛。
四、T5Gemma 2的型号与适用场景
T5Gemma 2提供了三种参数规模的预训练模型,覆盖从边缘设备到云端部署的不同需求:
这些模型均为预训练版本,开发者可以根据自己的任务(如翻译、图文问答)进行微调后再部署,灵活性极高。
五、如何开始使用T5Gemma 2?
如果你是开发者或研究者,想要尝试T5Gemma 2,可以通过以下渠道获取资源并快速上手:
-
查阅技术细节:阅读arXiv论文《T5Gemma 2: The Next Generation of Encoder-Decoder Models》(链接),了解模型的架构设计、训练方法和实验结果。
-
下载模型文件:
-
快速体验:通过Colab笔记本运行示例代码,无需本地配置环境(链接)。
-
云端部署:通过谷歌Vertex AI直接调用T5Gemma 2进行推理,适合大规模商业应用(链接)。
六、常见问题解答(FAQ)
1. T5Gemma 2和初代T5Gemma有什么区别?
最核心的区别在于架构和能力:初代T5Gemma是纯文本编码器-解码器模型,而T5Gemma 2通过绑定嵌入和合并注意力优化了效率,同时新增了多模态、128K长上下文、140+语言支持等特性。
2. T5Gemma 2的“多模态”支持哪些图片格式?
目前支持主流图片格式(如JPG、PNG、WebP),输入图片会先通过视觉编码器转化为特征向量,再与文本信息结合处理。
3. 128K上下文窗口在实际使用中会影响速度吗?
相比小窗口模型,处理128K tokens时推理时间会更长,但T5Gemma 2通过合并注意力和并行计算优化,速度比同规模传统模型快30%左右,基本能满足实际应用需求。
4. 可以用T5Gemma 2进行商业部署吗?
是的,T5Gemma 2的预训练模型允许开发者进行微调后用于商业应用,具体授权条款可参考下载平台的说明。
5. 没有机器学习背景,能使用T5Gemma 2吗?
如果你只需要调用模型(而非训练),可以通过Vertex AI等平台的API直接使用,无需深入了解模型细节;如果需要微调,建议参考Colab示例中的代码教程,有基础编程知识即可上手。
结语
T5Gemma 2的推出,不仅是编码器-解码器模型的一次重要升级,更体现了“高效实用”的设计理念——通过架构优化让小参数模型具备强大能力,通过多模态和长上下文拓展应用边界。对于开发者来说,它是一个兼顾性能与成本的优质选择;对于行业来说,它让AI在更多场景(如边缘设备、多语言服务、长文档处理)的落地成为可能。
如果你正在寻找一款能处理图文信息、理解长文本、支持多语言的编码器-解码器模型,不妨从T5Gemma 2开始尝试——它可能正是你需要的“多面手”工具。
